这篇文章主要讲述集成学习的bagging和boosting。
首先bagging和boosting是集成学习的两个大家族,每个家族也包括很多成员,例如boosting包括adaboost、xgboost,bagging也有RandomForest等方法。既然bagging和boosting是这些算法的基础,那他们的思想是什么呢?
Bagging和Boosting的理解与思想
简单总结Bagging:对数据集进行多次有放回抽样,每次的抽样进行分类计算生成弱分类器,分类问题就是把每一次的计算结果进行投票,看哪一种情况票数多即为最后结果。回归问题就是把所有生成的弱分类器结果进行取平均。
简单总结Boosting:初始对每个样本分配相同的权重,每次经过分类,把对的结果的权重降低,错的结果权重增高,如此往复,直到阈值或者循环次数。
Bagging和Boosting的区别
(1) bagging的训练集是随机的,各训练集是独立的;而boosting训练集的选择不是独立的,每一次选择的训练集都依赖于上一次学习的结果;
(2) bagging的每个预测函数都没有权重;而boosting根据每一次训练的训练误差得到该次预测函数的权重;
(3) bagging的各个预测函数可以并行生成;而boosting只能顺序生成。(对于神经网络这样极为耗时的学习方法,bagging可通过并行训练节省大量时间开销)。
Bagging和Boosting的例子
Bagging:
参数介绍:
x:输入的数据
y:输入数据对应的类别
k:阈值
绿色框真实的类别
蓝色框算法计算的类别
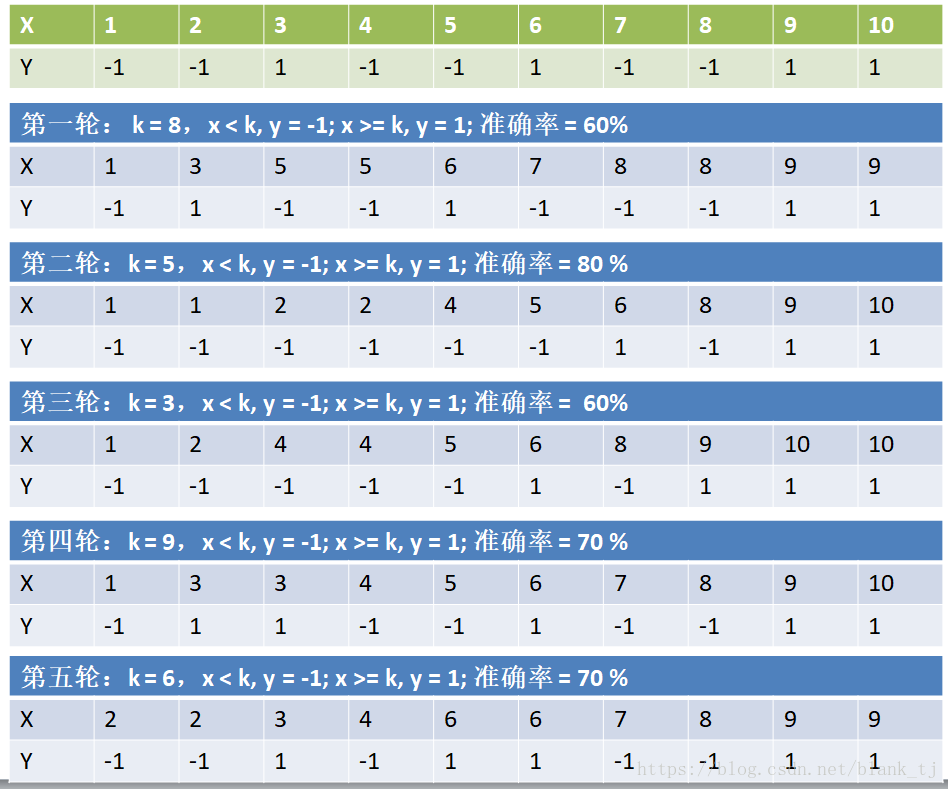
经过了5轮计算,并把5轮的计算综合得出结果:

可以看到准确率有90%。每次循环生成的弱分类器得到的结果的集成是一个强分类器。
adaboosting:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布
,一个子分类器
其中划圈的样本表示被分错的。在右边的图中,比较大的“+”表示对该样本做了加权。
第二步:

根据分类的正确率,得到一个新的样本分布
,一个子分类器
第三步:
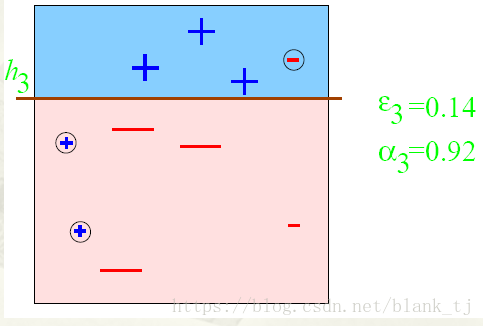
得到一个子分类器
整合所有子分类器:
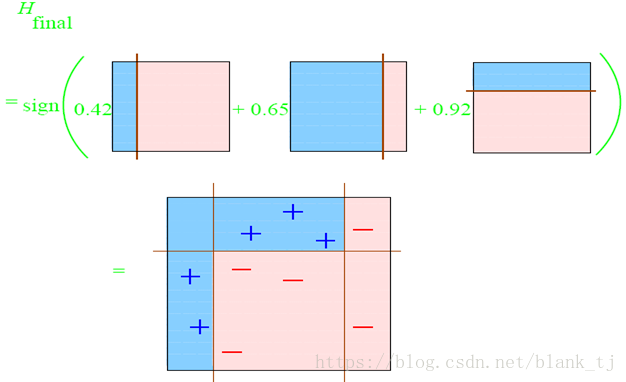
因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
Adaboost算法的某些特性是非常好的,在我们的报告中,主要介绍adaboost的两个特性。一是训练的错误率上界,随着迭代次数的增加,会逐渐下降;二是adaboost算法即使训练次数很多,也不会出现过拟合的问题。
adaboost特点:
1)每次迭代改变的是样本的分布,而不是重复采样
2)样本分布的改变取决于样本是否被正确分类
总是分类正确的样本权值低
总是分类错误的样本权值高(通常是边界附近的样本)
3)最终的结果是弱分类器的加权组合
权值表示该弱分类器的性能
adaboost优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!