1、梯度下降算法步骤:
a. 用随机值初始化权重和偏差
b.把输入传入神经网络得到输出值
c.计算预测值和真实值之间的误差
d.对每一个产生误差的神经元调整相应的权重值,以减小误差
e.重复迭代,直到得到最佳权重
2、把数据传入神经网络之前需要做一系列数据预处理(旋转、平移、缩放)工作,神经网络本身不能完成这些变换
3、Bagging操作和神经网络中的Dropout类似,Bagging(装袋方法,和boosting提升方法并列),是一种根据均匀概率分布从数据中重复抽样(有放回)的技术
4、在训练神经网络的时候,损失函数loss在最初的几个epochs时没有下降,可能是因为:学习率太低、正则参数太高或者陷入了局部最优解
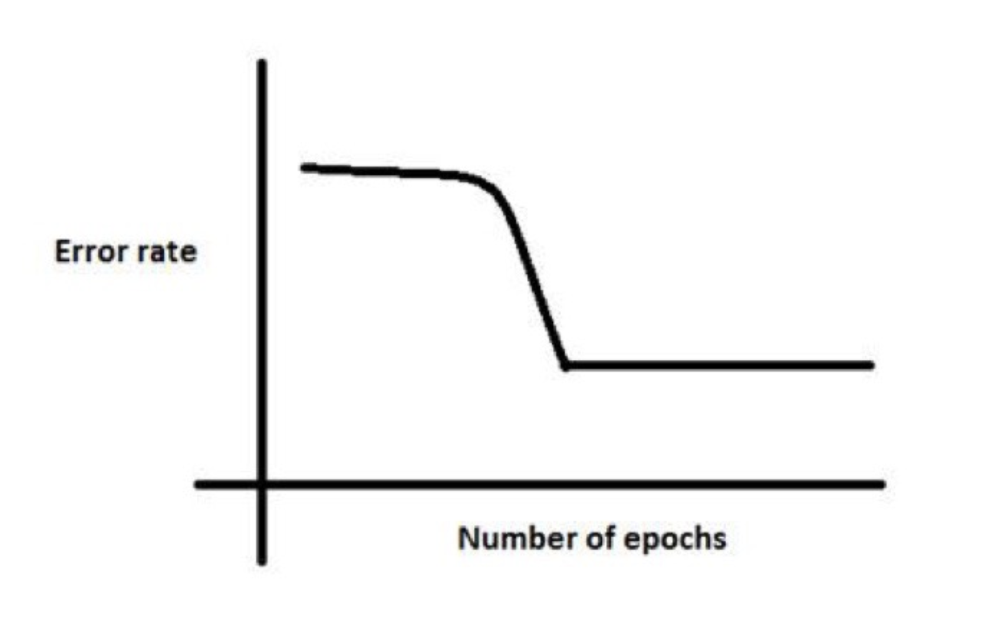
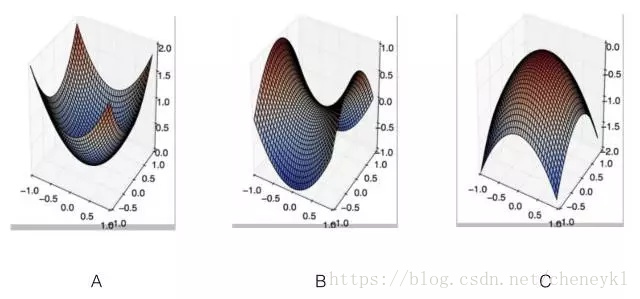
5、对于很多高维非凸函数而言,局部极小值(以及极大值)事实上都远少于另一类梯度为零的点:鞍点。鞍点附近的某些点比鞍点有更大的代价,而其他点则有更小的代价。
6、PCA(主成分分析)提取的是数据分布方差比较大的方向,也起到降维的作用。而神经网络中的隐藏藏如果能实现降维的话是提取了有预测能力的特征。
7、CNN和RNN都会发生权值共享。
8、神经网络中分批归一化(BN)处理过拟合原理,是因为同一数据在不同批中被归一化后的值有差别,相当于做了数据增强
9、输入图片大小为200×200,依次经过一层卷积(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一层卷积(kernel size 3×3,padding 1,stride 1)之后,输出特征图大小为?97
分析:
padding 是向外扩展的边缘大小,stride是每次移动的步长
输出尺寸 = (输入尺寸 + padding*2 - kernel尺寸)/stride + 1
第一层卷积:输出 =(200+2-5)/2 + 1 = 99.5 (取 99)
第二层池化:输出 = (99-3)/1 +1 = 97
第三层卷积:输出 = (97+2-3)/1 +1 = 97
卷积层向下取整,池化层向上取整:在卷积层公式直接使用了/号,去掉了余数,向下取整。而pool层中,使用了ceil函数,向上取整。
10、H-K算法,在最小均方误差准则下求权矢量,适用于线性可分和非线性可分的情况,对于线性可分情况给出最优权矢量,对于非线性可分的情况能够判别出来,退出迭代。
11、三个稠密矩阵A(m*n)、B(n*p)、C(p*q),m<n<p<q,要计算ABC,如何计算效率最高?(AB)C
(AB)C:m*n*p+m*p*q 次乘法运算
A(BC):n*p*q+m*n*p 次乘法运算
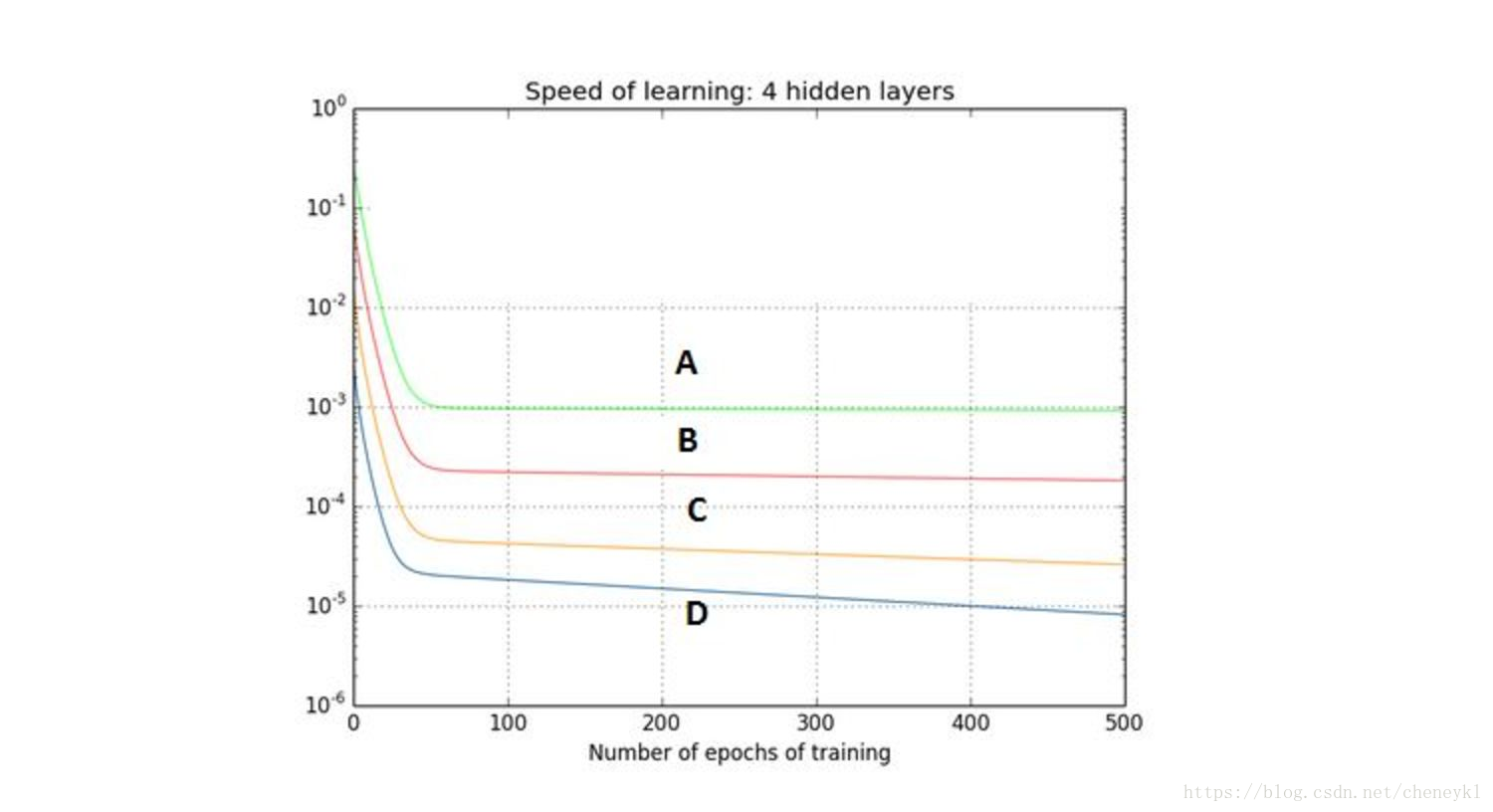
12、下图是一个利用sigmoid函数作为激活函数的含四个隐藏层的神经网络训练的梯度下降图。这个神经网络遇到了梯度消失的问题。 第一隐藏层对应D,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应A(A是反向传播的第一层,学习速度快)
13、假设在训练中我们突然遇到了一个问题,在几次循环之后,误差瞬间降低你认为数据有问题,于是你画出了数据并且发现也许是数据的偏度过大造成了这个问题,如何解决?

解决:对数据作主成分分析(PCA)和归一化。误差瞬间降低, 一般原因是多个数据样本有强相关性且突然被拟合命中, 或者含有较大方差数据样本突然被拟合命中. 所以对数据作主成分分析(PCA)和归一化能够改善这个问题。
14、我们可以观察到误差出现了许多小的"涨落"。 这种情况我们应该担心吗?
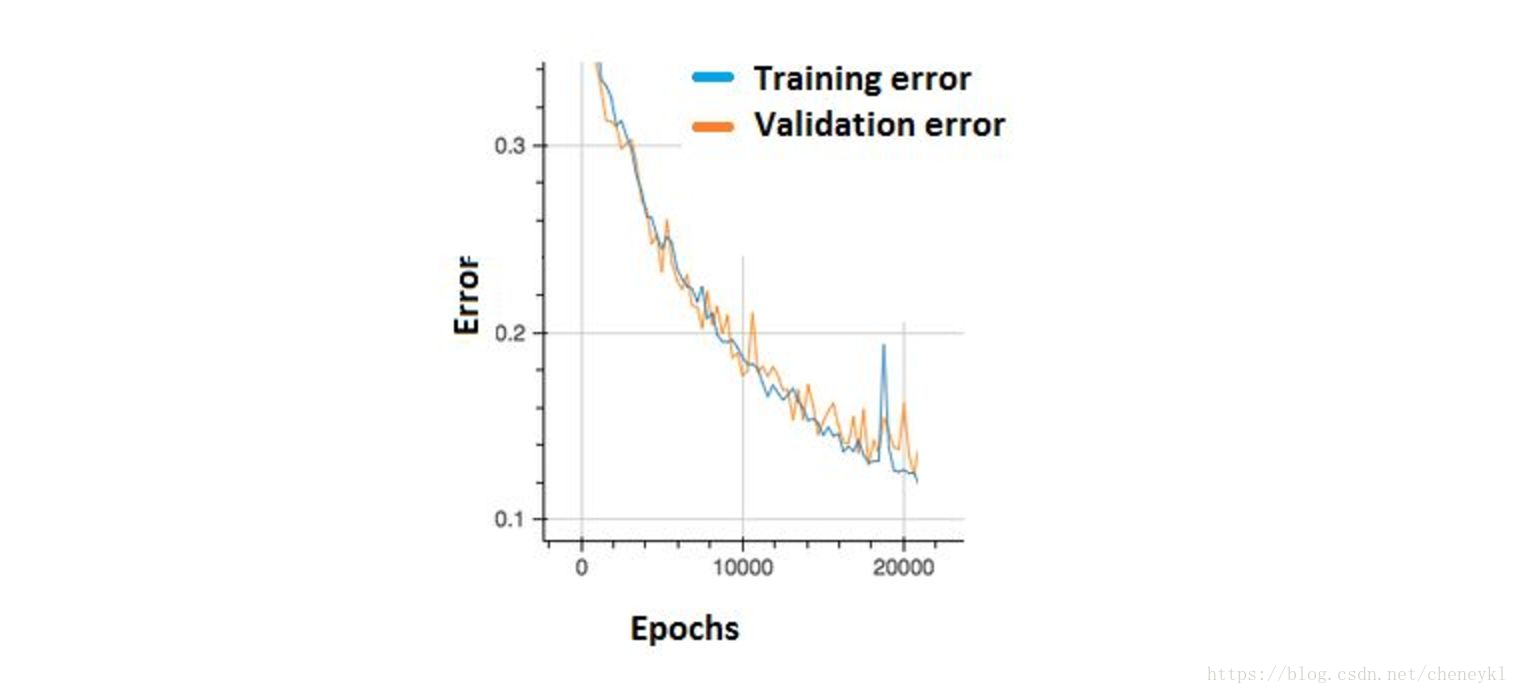
不需要,只要在训练集和交叉验证集上有累积的下降就可以了
为了减少这些“起伏”,可以尝试增加批尺寸(batch size)。具体来说,在曲线整体趋势为下降时, 为了减少这些“起伏”,可以尝试增加批尺寸(batch size)以缩小batch综合梯度方向摆动范围. 当整体曲线趋势为平缓时出现可观的“起伏”, 可以尝试降低学习率以进一步收敛. “起伏”不可观时应该提前终止训练以免过拟合。