##1.驾驶视频数据集:
数据集地址:http://bair.berkeley.edu/blog/2018/05/30/bdd/
BDD100K,这是迄今为止最大的驾驶视频数据集。它包含100,000个视频,代表超过1000小时的驾驶体验,超过1亿帧。这些视频附带了用于轨迹信息的GPU / IMU数据。它们会手动标记天气,一天中的时间和场景类型。

##2. Cityscapes数据集
数据集地址:https://www.cityscapes-dataset.com
Cityscapes Dataset专注于对城市街景的语义理解,提供无人驾驶环境下的图像分割数据集,它包含50个城市不同场景、不同背景、不同季节的街景,提供5000张精细标注的图像、20000张粗略标注的图像、30类标注物体。

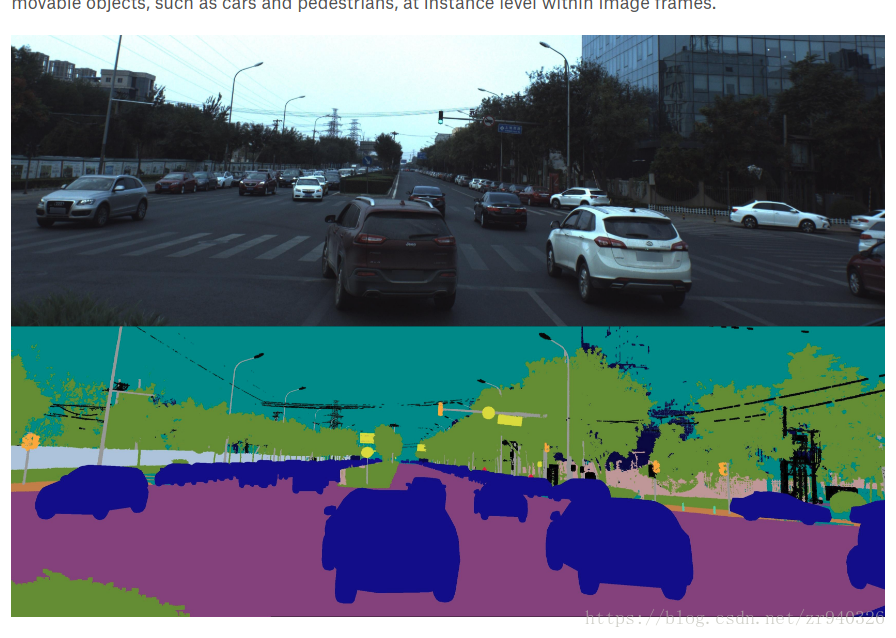
##3.KITTI 数据集
数据集地址:http://www.cvlibs.net/datasets/kitti/raw_data.php
http://www.cvlibs.net/publications/Geiger2013IJRR.pdf
KITTI数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成[1] ,以10Hz的频率采样及同步。总体上看,原始数据集被分类为’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’。对于3D物体检测,label细分为car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc组成。


##4.CamVid 数据集
数据集地址:http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
剑桥驾驶标签视频数据库(CamVid)是第一个具有对象类语义标签的视频集合,其中包含元数据。 数据库提供基础事实标签,将每个像素与32个语义类之一相关联。 该数据库解决了对实验数据的需求,以定量评估新兴算法。 虽然大多数视频都使用固定位置的闭路电视风格相机拍摄,但我们的数据是从驾驶汽车的角度拍摄的。 驾驶场景增加了观察对象类的数量和异质性。


##5.Caltech数据集
数据集地址:http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
加州理工学院行人数据集包括大约10小时的640x480 30Hz视频,这些视频来自在城市环境中通过常规交通的车辆。大约250,000个框架(137个近似分钟的长段)共有350,000个边界框和2300个独特的行人被注释。注释包括边界框和详细遮挡标签之间的时间对应。更多信息可以在我们的PAMI 2012和CVPR 2009基准测试文件中找到。

##6.Tusimple 数据集
数据集地址:http://benchmark.tusimple.ai/#/t/1/dataset