本来是昨晚上发表的,但是今早还没发,我一看一直再待审核。。。有点懵,刚好今晚重新完善一下吧
我在Windows上使用了一个第三方软件,用来连接虚拟机的mysql服务端,只不过方便的就是有了图形化界面,但是也可以通过代码命令进行操作,只不过这样好截图一点,和Linux直接敲代码没有差别。下面就让我们开始吧!
第三方软件图
数据的增删改
增
整列插入insert into 表名 values(…..)
缺省插入insert into 表名 (列名1,….)values(值1,…..)
同时插入多条数据:insert into 表名 values(….)(….)….
修改
update 表名 set 列1=值1,。。。where 条件;
删除
delete from 表名 where 条件
数据的查询
查询的基本语法
select * from 表名;
from关键字后面写表名,表示数据来源于是这张表
select后面写表中的列名,如果是*表示在结果中显示表中所有列
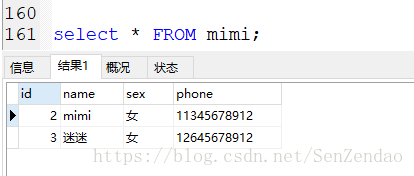
查询是最基础的操作,也是最常用的一个操作
进行数据查询加条件查询 where
使用where子句对表中的数据筛选,结果为true的行会出现在结果集中
语法如下:
select * from 表名 where 条件;
比较运算符(和我们python中的比较运算符一样)
等于=
大于>
大于等于>=
小于<
小于等于<=
不等于!=
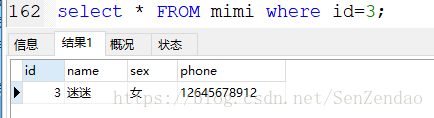
我们加了一个简单的条件,id=3的信息,当然这是最简单的,复杂的我们就不说了,只要语法熟记在心,在复杂的也难不倒我们。
逻辑运算符这些都可以在条件里面使用,
and
or
not
模糊查询
like
%表示任意多个任意字符
_表示一个任意字符
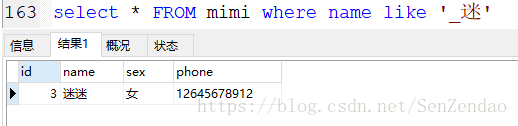
意思就是我们如果不知道全部信息,但是知道姓名的第二个字为‘迷’,我们加入_就可以了,和正则表达式里面的‘.‘有点相同,而‘%‘和‘*’相似
范围查询
in表示在一个非连续的范围内
between … and …表示在一个连续的范围内

sql语句就是如图,因为我表中的数据不充足,所以就没有运行,掌握语法就好。
空判断
判空is null

优先级
小括号,not,比较运算符,逻辑运算符
and比or先运算,如果同时出现并希望先算or,需要结合()使用
聚合
为了快速得到统计数据,提供了5个聚合函数
count(*)表示计算总行数,括号中写星与列名,结果是相同的
查询学生总数
select count(*) from students;
max(列)表示求此列的最大值
查询女生的编号最大值
select max(id) from students where gender=0;
min(列)表示求此列的最小值
查询未删除的学生最小编号
select min(id) from students where isdelete=0;
sum(列)表示求此列的和
查询男生的编号之后
select sum(id) from students where gender=1;
avg(列)表示求此列的平均值
查询未删除女生的编号平均值
select avg(id) from students where isdelete=0 and gender=0;
聚合这些东西就是换了个名字,python中的这些方法大家肯定都会,统计,求和,最大值,最小值,平均值。
今天补充一下分组,排序和分页,数据库的基本操作就算结束了,后面的就是高级用法和python的交互了。
分组
#数据库语句的规范(关键词左对齐,条件等等TAB键再写,但是很多人都直接把sql语句写成一行,这样也行只是不符合mysql的规范,看起来了不清晰明了)
select (要查询的东西)
from (从哪里查)
where 分组之前的过滤
group by(分组)
having 分组之后的过滤
order by (排序)
limit (分页)
按照字段分组,表示此字段相同的数据会被放到一个组中
分组后,只能查询被分组的列和聚合函数
可以对分组后的数据进行统计,做聚合运算
下面举两个分组的小例子
1:查询男女生总数
select gender as 性别,count(*)
from students
group by gender;
2:查询各城市人数
select hometown as 家乡,count(*)
from students
group by hometown;
分组前后的过滤
group by 前的where就是分组前的过滤,直接加条件就可以
group by 后的having就是分组后的过滤,直接加条件就可以
排序就是order by
后跟条件 或者 某列中的某条信息,比如说按照学生的身高,
就是 order by hight(当然你表中得有hight学生的身高信息);
正序:asc 倒序:desc
默认就是正序 asc可以省略不写,如果要倒序就在条件信息后面加上desc就OK了。
分页
为什么要分页呢,就是因为如果信息量过大的话,查询一次要在一页中显示这么多信息,可能有很多信息都是无效的,这样会造成不必要的资源浪费,所以我们就要使用分页,就是前面语法中最后一行的limit
limit start,count
后面有两个参数一共就两种情况,第一种是只写第一个参数,第二种是两个参数都写。
第一种 limit start
比如说 start=3,这样就会列出3个(行)信息
第二种 limit start,count
比如说 start=3 count=3 这意思就是从第四行开始往下再列出三行信息。你可以把start的3当作从0开始数,相当于列表的下标就是从0开始的,我是这样理解的,但是也不准确,每个人都有自己的理解方式,看你自己是如何理解的把。