在文章NLP入门实例推荐中提到,对话系统有两种形式:
基于检索的对话系统 模式:s1,s2–>R,即字符串s1和s2符合一定的规则。
基于生成的对话系统 模式:s1–>s2,即由字符串s1得到s2。
两者各有优势与不足。首先基于检索的对话系统,将回复使用的数据预先存储,那么优点就是回复的内容不会有语法和语义的错误,但因为不会像基于生成的对话系统那样创造出新的回答,因此也无法对未训练的问题作出回答。
本篇是聊天系统的第一篇文章,参考博客deep-learning-for-chatbots-part-1和deep-learning-for-chatbots-part-1,另外附上中文翻译。该博客是由WILDML所写,就是那个实现TextCNN的博主,因此以这篇文章入手对话系统,希望能在对话系统方向养成良好的代码风格和研究主线。
原文的github地址为tensorflow v0.9,有部分的函数已经更改。在实际的运行当中使用的TensorFlow的版本为v1.2,因此做了一些修改,并将修改后的代码上传到github地址,欢迎fork和start。按照以往的惯例,本篇文章依然分为数据处理、模型构建、模型训练、结果分析四部分。
数据处理
原文中使用Ubuntu对话数据集(论文来源 github地址)。这个数据集(Ubuntu Dialog Corpus, UDC)是目前最大的公开对话数据集之一,它是来自Ubuntu的IRC网络上的对话日志。这篇论文介绍了该数据集生成的具体细节。下面简单介绍一下数据的格式。
训练数据有1,000,000条实例,其中一半是正例(label为1),一半是负例(label为0,负例为随机生成)。每条实例包括一段上下文信息(context),即Query;和一段可能的回复内容(utterance),即Response;Label为1表示该Response确实是Query的回复,Label为0则表示不是。下面是数据示例:
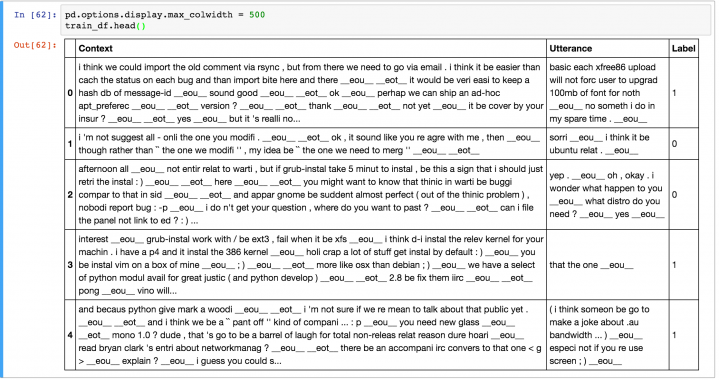
数据集的生成使用了NLTK工具,包括分词、stemmed、lemmatized等文本预处理步骤;同时还使用了NER技术,将文本中的实体,如姓名、地点、组织、URL等替换成特殊字符。这些文本预处理并不是必须的,但是能够提升一些模型的性能。据统计,query的平均长度为86个word,而response的平均长度为17个word,更多的数据统计信息见Jupyter notebook。
数据集也包括了测试和验证集,但这两部分的数据和训练数据在格式上不太一样。在测试集和验证集中,对于每一条实例,有一个正例和九个负例数据(也称为干扰数据)。模型的目标在于给正例的得分尽可能的高,而给负例的得分尽可能的低。下面是数据示例:
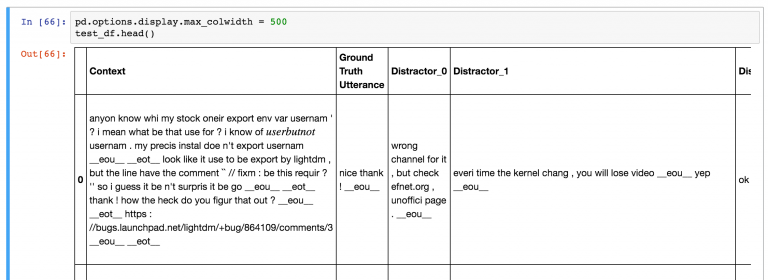
模型的评测方式有很多种。其中最常用到的是recall@k,即经模型对候选的response排序后,前k个候选中存在正例数据(正确的那个)的占比;显然k值越大,该指标会越高,因为这对模型性能的要求越松。
在Ubuntu数据集中,负例数据都是随机生成的;然而在现实中,想要从全部的数据中随机生成负例是不可能的。谷歌的Smart Reply则使用了聚类技术,然后将每个类的中取一些作为负例,这样生成负例的方式显得更加合理(考虑了负例数据的多样性,同时减少时间开销)。
数据集的原始格式为csv格式,我们需要先将其转为TensorFlow专有的格式,这种格式的好处在于能够直接从输入文件中load tensors,并让TensorFlow来处理洗牌(shuffling)、批量(batching)和队列化(queuing)等操作。预处理中还包括创建一个字典库,将词进行标号,TFRecord文件将直接存储这些词的标号。
每个实例包括如下几个字段:
Query:表示为一串词标号的序列,如[231, 2190, 737, 0, 912];
Query的长度;
Response:同样是一串词标号的序列;
Response的长度;
Label;
Distractor_[N]:表示负例干扰数据,仅在验证集和测试集中有,N的取值为0-8;
Distractor_[N]的长度;
数据预处理的Python脚本见这里,生成了3个文件:train.tfrecords, validation.tfrecords 和 test.tfrecords。你可以尝试自己运行程序,或者直接下载和使用预处理后的数据。
为了使用TensoFlow内置的训练和评测模块,我们需要创建一个输入函数:这个函数返回输入数据的batch。因为训练数据和测试数据的格式不同,我们需要创建不同的输入函数。输入函数需要返回批量(batch)的特征和标签值(如果有的话)。类似于如下:
def input_fn():
# TODO Load and preprocess data here
return batched_features, labels因为我们需要在模型训练和评测过程中使用不同的输入函数,为了防止重复书写代码,我们创建一个包装器(wrapper),名称为create_input_fn,针对不同的mode使用相应的code,如下:
def create_input_fn(mode, input_files, batch_size, num_epochs=None):
def input_fn():
# TODO Load and preprocess data here
return batched_features, labels
return input_fn完整的code见udc_inputs.py。整体上,这个函数做了如下的事情:
(1) 定义了示例文件中的feature字段;
(2) 使用tf.TFRecordReader来读取input_files中的数据;
(3) 根据feature字段的定义对数据进行解析;
(4) 提取训练数据的标签;
(5) 产生批量化的训练数据;
(6) 返回批量的特征数据及对应标签;
模型构建
这篇博文将建立的NN模型为两层Encoder的LSTM模型(Dual Encoder LSTM Network),这种形式的网络被广泛应用在chatbot中(尽管可能效果并不是最佳的那个,你可以尽可能地尝试其他的NN模型)。seq2seq模型常用于机器翻译领域,并取得了较大的效果。使用Dual LSTM模型的原因在于这个模型被证明在这个数据集有较好的效果(详情见这里),这可以作为我们后续模型效果的验证。
两层Encoder的LSTM模型的结构图如下(论文来源):
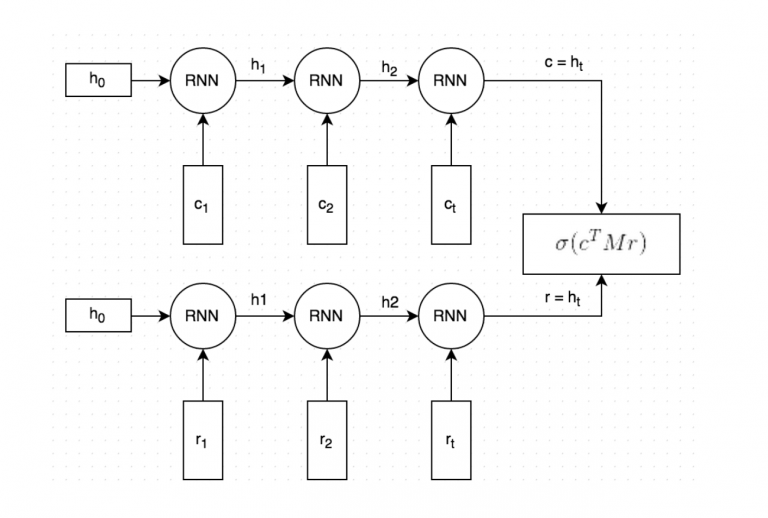
大致的流程如下:
(1) Query和Response都是经过分词的,分词后每个词embedded为向量形式。初始的词向量使用GloVe vectors,之后词向量随着模型的训练会进行fine-tuned(实验发现,初始的词向量使用GloVe并没有在性能上带来显著的提升)。
(2) 分词且向量化的Query和Response经过相同的RNN(word by word)。RNN最终生成一个向量表示,捕捉了Query和Response之间的[语义联系](图中的c和r);这个向量的维度是可以指定的,这里指定为256维。
(3) 将向量c与一个矩阵M相乘,来预测一个可能的回复r’。如果c为一个256维的向量,M维256*256的矩阵,两者相乘的结果为另一个256维的向量,我们可以将其解释为[一个生成式的回复向量]。矩阵M是需要训练的参数。
(4) 通过点乘的方式来预测生成的回复r’和候选的回复r之间的相似程度,点乘结果越大表示候选回复作为回复的可信度越高;之后通过sigmoid函数归一化,转成概率形式。图中把第(3)步和第(4)步结合在一起了。
为了训练模型,我们还需要一个损失函数(loss function)。这里使用二元的交叉熵(binary cross-entropy)作为损失函数。我们已知实例的真实label y,值为0或1;通过上面的第(4)步可以得到一个概率值 y’;因此,交叉熵损失值为L = -y * ln(y’) - (1 - y) * ln(1 - y’)。这个公式的意义是直观的,即当y=1时,L = -ln(y’),我们期望y’尽量地接近1使得损失函数的值越小;反之亦然。
因此这基本上是一个最简单的LSTM模型实现基于检索的对话系统了,模型构建具体见dual_encoder.py:
# Build the RNN
with tf.variable_scope("rnn") as vs:
# We use an LSTM Cell
cell = tf.nn.rnn_cell.LSTMCell(
hparams.rnn_dim,
forget_bias=2.0,
use_peepholes=True,
state_is_tuple=True)
# Run the utterance and context through the RNN
rnn_outputs, rnn_states = tf.nn.dynamic_rnn(
cell,
tf.concat(0, [context_embedded, utterance_embedded]),
sequence_length=tf.concat(0, [context_len, utterance_len]),
dtype=tf.float32)
# the shape of encoding_context and encoding_utterance: [batch_size, rnn_size]
encoding_context, encoding_utterance = tf.split(0, 2, rnn_states.h)
with tf.variable_scope("prediction") as vs:
M = tf.get_variable("M",
shape=[hparams.rnn_dim, hparams.rnn_dim],
initializer=tf.truncated_normal_initializer())
# "Predict" a response: c * M
generated_response = tf.matmul(encoding_context, M)
generated_response = tf.expand_dims(generated_response, 2)
encoding_utterance = tf.expand_dims(encoding_utterance, 2)
# Dot product between generated response and actual response
# (c * M) * r
logits = tf.batch_matmul(generated_response, encoding_utterance, True)
logits = tf.squeeze(logits, [2])
# Apply sigmoid to convert logits to probabilities
probs = tf.sigmoid(logits)
if mode == tf.contrib.learn.ModeKeys.INFER:
return probs, None
# Calculate the binary cross-entropy loss
losses = tf.nn.sigmoid_cross_entropy_with_logits(logits, tf.to_float(targets))模型训练
首先,给一个模型训练和测试的程序样例,这之后你可以参照程序中所用到的标准函数,来快速切换和使用其他的网络模型。假设我们有一个函数model_fn,函数的输入参数有batched features,label和mode(train/evaluation),函数的输出为预测值。程序样例如下:
estimator = tf.contrib.learn.Estimator(
model_fn=model_fn,
model_dir=MODEL_DIR,
config=tf.contrib.learn.RunConfig())
input_fn_train = udc_inputs.create_input_fn(
mode=tf.contrib.learn.ModeKeys.TRAIN,
input_files=[TRAIN_FILE],
batch_size=hparams.batch_size)
input_fn_eval = udc_inputs.create_input_fn(
mode=tf.contrib.learn.ModeKeys.EVAL,
input_files=[VALIDATION_FILE],
batch_size=hparams.eval_batch_size,
num_epochs=1)
eval_metrics = udc_metrics.create_evaluation_metrics()
# We need to subclass theis manually for now. The next TF version will
# have support ValidationMonitors with metrics built-in.
# It's already on the master branch.
class EvaluationMonitor(tf.contrib.learn.monitors.EveryN):
def every_n_step_end(self, step, outputs):
self._estimator.evaluate(
input_fn=input_fn_eval,
metrics=eval_metrics,
steps=None)
eval_monitor = EvaluationMonitor(every_n_steps=FLAGS.eval_every)
estimator.fit(input_fn=input_fn_train, steps=None, monitors=[eval_monitor])结果分析
在训练完模型后,你可以将其应用在测试集上,使用:
python udc_test.py --model_dir=$MODEL_DIR_FROM_TRAINING 例如:
python udc_test.py --model_dir=~/github/chatbot-retrieval/runs/1467389151这将得到模型在测试集上的recall@k的结果,注意在使用udc_test.py文件时,需要使用与训练时相同的参数。
在训练模型的次数大约2w次时(在GPU上大约花费1小时,在64G的CPU服务器上大约花费20个小时),模型在测试集上得到如下的结果:
recall_at_1 = 0.507581018519
recall_at_2 = 0.689699074074
recall_at_5 = 0.913020833333原文中将该模型得到的结果与两外两种方式做了对比分析。
一种是随机得到结果:
Recall @ (1, 10): 0.0937632
Recall @ (2, 10): 0.194503
Recall @ (5, 10): 0.49297
Recall @ (10, 10): 1这与理论预期相符,基本上就是随机得到的结果。
另一种是采用TF-IDF的方式,即将Q与R的TF-IDF值进行比对,对于一个QR pair,它们语义上接近的词共现的越多,也将越可能是一个正确的QR pair。
Recall @ (1, 10): 0.495032
Recall @ (2, 10): 0.596882
Recall @ (5, 10): 0.766121
Recall @ (10, 10): 1其中,dual LSTM模型recall@1的值与tfidf模型的差不多,但是recall@2和recall@5的值则比tfidf模型的结果好太多。原论文中的结果依次是0.55,0.72和0.92,可能通过模型调参或者预处理能够达到这个结果。
使用模型进行预测:
对于新的数据,你可以使用udc_predict.py来进行预测;例如:
python udc_predict.py --model_dir=./runs/1467576365/结果如下:
Context: Example context
Response 1: 0.44806
Response 2: 0.481638总结
这篇博文中,我们实现了一个基于检索的NN模型,它能够对候选的回复进行预测和打分,通过输出分值最高(或者满足一定阈值)的候选回复已完成聊天的过程。后续可以尝试其他更好的模型,或者通过调参来取得更好的实验结果。