版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_38208401/article/details/78220802
1、Python获取指定目录下所有页面的表格数据并写入CSV
BeautifulSoup官方文档
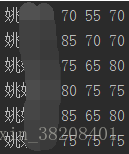
背景:获取绩效目录下所有人的分数
1)BeautifulSoup安装:pip install –upgrade beautifulsoup4
2)查看指定目录(空间)接口:空间管理—-概览—-内容工具—-点击展开,即可查看到对应接口
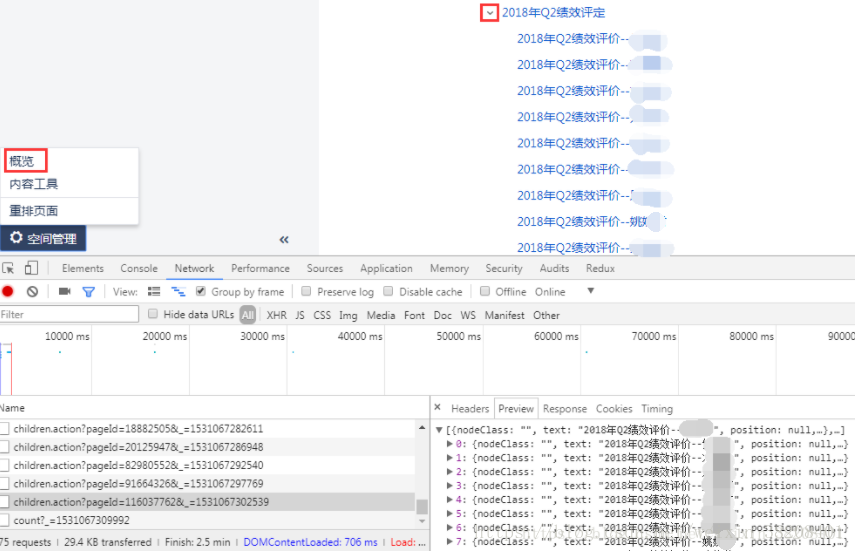
3)获取指定目录的子目录页面Id
(注:KB页面只是pageId不一样)
tree = json.loads(self.loginreqsession.get(self.treeURL).content.decode('utf-8'))
for i in range(len(tree)):
alllist = []
alllist.append(tree[i]['text'].split('--')[1])
alllist.append(tree[i]['pageId'])
self.lists.append(alllist)
得到对应人员对应的评分页面Id
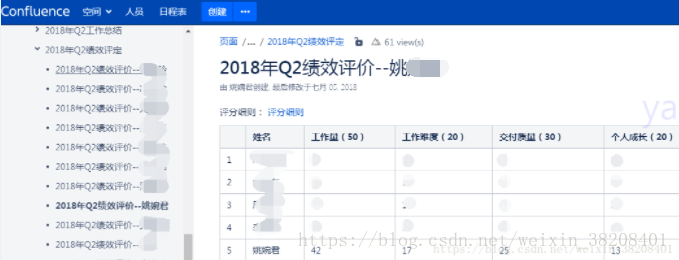
4、beautifulsoup解析html获取分数写入表格
for i in range(len(self.lists)):
pageURL = 'https://kb.cvte.com/pages/viewpage.action?pageId=%s' % self.lists[i][1]
response = self.loginreqsession.get(pageURL)
soup = BeautifulSoup(response.content,'html.parser', from_encoding='utf-8')
scorelist = {}
if self.lists[i][0] in ('姚xx',...):
for idx, tr in enumerate(soup.find_all('tr')):
if idx != 0:
tds = tr.find_all('td')
sum = int(tds[2].text.strip()) + int(tds[3].text.strip()) + int(tds[4].text.strip()) + int(tds[5].text.strip())
scorelist[''] = self.lists[i][0]
scorelist[str(tds[1].text.strip())] = sum
csvfile = open('scorecsv.csv','a', newline='')
csv_write = csv.writer(csvfile)
for key in scorelist:
csv_write.writerow([key, scorelist[key]])
csvfile.close()
得到对应打分人给组内人员的总分

查看写入的execl
2、Python获取指定页面的表格数据
之前的格式背景:我们每个季度都会绩效评定,数据需要从kb上拷贝至execl,现尝试python获取
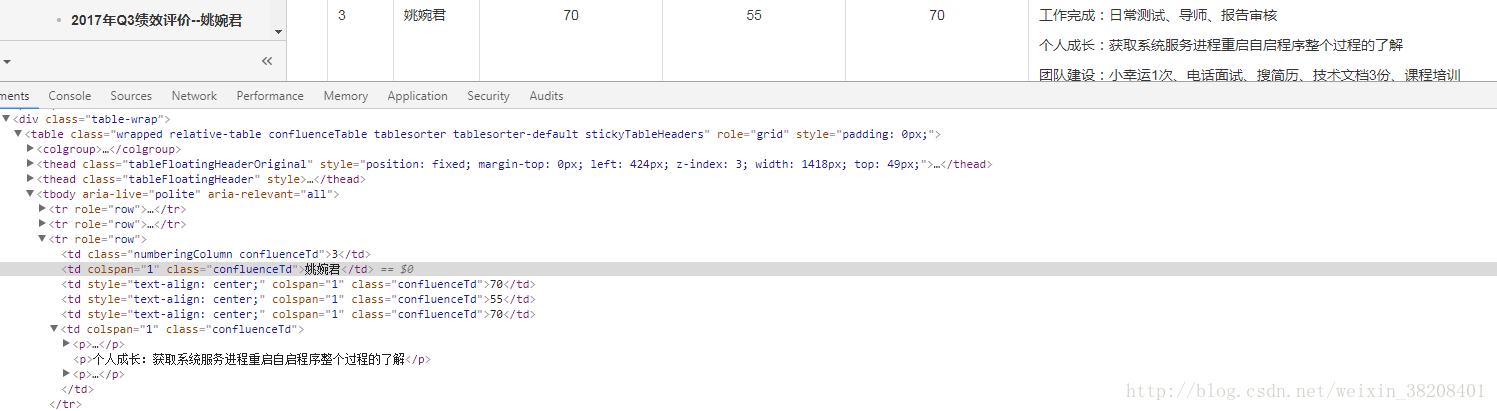
先看看网页:
1)正则表达式直接提取
#coding=utf-8
import requests
import re
kb_url = 'https://kb.cvte.com'
login_data = {
'os_username': '账号',
'os_password': '密码',
'login':'登录',
'os_destination':'',
}
loginreqsession = requests.session()#创建session对象保存所有登录会话请求
logincontent = loginreqsession.post(kb_url,login_data).content.decode('utf-8')
testone = ['66800270','66800282','66800144','66800323','66799742','66800313']
for i in testone:
testonescore = loginreqsession.get('https://kb.cvte.com/pages/viewpage.action?pageId='+i).content.decode('utf-8')
#print(testonescore)
namelist = re.findall(r'meta name="ajs-page-title" content=\"(.*?)\"',testonescore,re.S)
s = re.findall(r'<td .*?>(.*?)</td>',testonescore,re.M)
#print(s)
print(s[16],s[17],s[18],re.sub('<[^>]+>','',s[19]))#过滤html标签执行结果: