首先得下载itextsharp
有两个dll, itextsharp.dll和itextsharp.xmlworker.dll
一、新建一个HtmlToPdfHelper类
namespace ClassLibrary1
{
/// <summary>
/// HTML转PDF帮助类
/// </summary>
public class HtmlToPdfHelper
{
/// <summary>
/// 准备好的html字符串
/// </summary>
private string m_HtmlString;
/// <summary>
/// PDF保存目录(绝对路径)
/// </summary>
private string m_PDFSaveFloder;
/// <summary>
/// 图片XY字典,例如 [{img1, 100,200},{img2,20,30}}
/// </summary>
private Dictionary<string, Tuple<float, float>> m_ImageXYDic = null;
public HtmlToPdfHelper(string htmlString, string pdfSaveFloder, Dictionary<string, Tuple<float, float>> imageXYDic)
{
m_HtmlString = htmlString;
m_PDFSaveFloder = pdfSaveFloder;
m_ImageXYDic = imageXYDic;
}
//生成PDF
public bool BuilderPDF()
{
try
{
string pdfSavePath = Path.Combine(m_PDFSaveFloder, Guid.NewGuid().ToString()+".pdf");
if (!Directory.Exists(m_PDFSaveFloder))
{
Directory.CreateDirectory(m_PDFSaveFloder);
}
using (FileStream fs = new FileStream(pdfSavePath, FileMode.OpenOrCreate))
{
byte[] htmlByte = ConvertHtmlTextToPDF(m_HtmlString);
fs.Write(htmlByte, 0, htmlByte.Length);
return true;
}
}
catch (Exception ex)
{
throw new ApplicationException("保存PDF到磁盘时异常", ex);
}
}
//将html字符串转为字节数组(代码来自百度)
private byte[] ConvertHtmlTextToPDF(string htmlText)
{
if (string.IsNullOrEmpty(htmlText))
{
return null;
}
//避免當htmlText無任何html tag標籤的純文字時,轉PDF時會掛掉,所以一律加上<p>標籤
//htmlText = "<p>" + htmlText + "</p>";
try
{
MemoryStream outputStream = new MemoryStream(); //要把PDF寫到哪個串流
byte[] data = Encoding.UTF8.GetBytes(htmlText); //字串轉成byte[]
MemoryStream msInput = new MemoryStream(data);
Document doc = new Document(); //要寫PDF的文件,建構子沒填的話預設直式A4
PdfWriter writer = PdfWriter.GetInstance(doc, outputStream);
//指定文件預設開檔時的縮放為100%
PdfDestination pdfDest = new PdfDestination(PdfDestination.XYZ, 0, doc.PageSize.Height, 1f);
//開啟Document文件
doc.Open();
#region 图片的处理
CssFilesImpl cssFiles = new CssFilesImpl();
cssFiles.Add(XMLWorkerHelper.GetInstance().GetDefaultCSS());
var cssResolver = new StyleAttrCSSResolver(cssFiles);
var tagProcessors = (DefaultTagProcessorFactory)Tags.GetHtmlTagProcessorFactory();
tagProcessors.RemoveProcessor(HTML.Tag.IMG); // remove the default processor
tagProcessors.AddProcessor(HTML.Tag.IMG, new CustomImageTagProcessor(m_ImageXYDic)); // use new processor
var hpc = new HtmlPipelineContext(new CssAppliersImpl(new XMLWorkerFontProvider()));
hpc.SetAcceptUnknown(true).AutoBookmark(true).SetTagFactory(tagProcessors); // inject the tagProcessors
var charset = Encoding.UTF8;
var htmlPipeline = new HtmlPipeline(hpc, new PdfWriterPipeline(doc, writer));
var pipeline = new CssResolverPipeline(cssResolver, htmlPipeline);
var worker = new XMLWorker(pipeline, true);
var xmlParser = new XMLParser(true, worker, charset);
xmlParser.Parse(new StringReader(htmlText));
#endregion
//使用XMLWorkerHelper把Html parse到PDF檔裡
XMLWorkerHelper.GetInstance().ParseXHtml(writer, doc, msInput, null, Encoding.UTF8, new UnicodeFontFactory());
//將pdfDest設定的資料寫到PDF檔
PdfAction action = PdfAction.GotoLocalPage(1, pdfDest, writer);
writer.SetOpenAction(action);
doc.Close();
msInput.Close();
outputStream.Close();
return outputStream.ToArray();
}
catch (Exception ex)
{
throw new ApplicationException("转PDF时异常", ex);
}
}
//字体工厂(代码来自百度)
public class UnicodeFontFactory : FontFactoryImp
{
private static readonly string arialFontPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory
, "Content/arialuni.ttf");//arial unicode MS是完整的unicode字型。
public override Font GetFont(string fontname, string encoding, bool embedded, float size, int style, BaseColor color,
bool cached)
{
BaseFont baseFont = BaseFont.CreateFont(arialFontPath, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
return new Font(baseFont, size, style, color);
}
}
//自定义的图片处理类(代码来自百度)
public class CustomImageTagProcessor : iTextSharp.tool.xml.html.Image
{
//个人加入的图片位置处理代码
private float _offsetX=0;
private float _offsetY=0;
private Dictionary<string, Tuple<float, float>> _imageXYDict;//个人加入的图片位置处理代码
public CustomImageTagProcessor(Dictionary<string, Tuple<float, float>> imageXYDict)//个人加入的图片位置处理代码
{
_imageXYDict = imageXYDict;
}
protected void SetImageXY(string imageId)//个人加入的图片位置处理代码
{
if (_imageXYDict == null)
{
return;
}
Tuple<float, float> xyTuple = null;
_imageXYDict.TryGetValue(imageId, out xyTuple);
if (xyTuple != null)
{
_offsetX = xyTuple.Item1;
_offsetY = xyTuple.Item2;
}
}
public override IList<IElement> End(IWorkerContext ctx, Tag tag, IList<IElement> currentContent)
{
IDictionary<string, string> attributes = tag.Attributes;
string src;
if (!attributes.TryGetValue(HTML.Attribute.SRC, out src))
return new List<IElement>(1);
if (string.IsNullOrEmpty(src))
return new List<IElement>(1);
string imageId;//个人加入的图片位置处理代码
if (!attributes.TryGetValue(HTML.Attribute.ID, out imageId))//个人加入的图片位置处理代码
return new List<IElement>(1);
if (string.IsNullOrEmpty(imageId))
return new List<IElement>(1);
SetImageXY(imageId);//个人加入的图片位置处理代码
if (src.StartsWith("data:image/", StringComparison.InvariantCultureIgnoreCase))
{
// data:[][;charset=][;base64],
var base64Data = src.Substring(src.IndexOf(",") + 1);
var imagedata = Convert.FromBase64String(base64Data);
var image = iTextSharp.text.Image.GetInstance(imagedata);
var list = new List<IElement>();
var htmlPipelineContext = GetHtmlPipelineContext(ctx);
list.Add(GetCssAppliers().Apply(new Chunk((iTextSharp.text.Image)GetCssAppliers().Apply(image, tag, htmlPipelineContext), _offsetX, _offsetY, true), tag, htmlPipelineContext));
return list;
}
else
{
return base.End(ctx, tag, currentContent);
}
}
}
}
}二、新建一个测式类
namespace ClassLibrary1
{
/// <summary>
/// 测试类
/// </summary>
public class PersonEntity
{
/// <summary>
/// html模版绝对路径
/// </summary>
public string m_HtmlTemplatePath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "Scripts/person.html");
/// <summary>
/// PDF生成的目录(绝对路径)
/// </summary>
public string m_PdfSaveFolder = Path.Combine(AppDomain.CurrentDomain.BaseDirectory,"PDFFolder");
public PersonEntity()
{
}
/// <summary>
/// 生成PDF
/// </summary>
public void BuildPDF()
{
using (StreamReader reader = new StreamReader(m_HtmlTemplatePath))
{
string htmlStr = reader.ReadToEnd();//读取html模版
string iamgeBase64Str1 = ImageToBase64String(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "Scripts/img1.jpg"));
string iamgeBase64Str2 = ImageToBase64String(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "Scripts/img2.jpg"));
htmlStr = htmlStr.Replace("@PersonName", "张三");
htmlStr = htmlStr.Replace("@PersonImage1", iamgeBase64Str1);
htmlStr = htmlStr.Replace("@PersonImage2", iamgeBase64Str2);
Dictionary<string, Tuple<float, float>> imageXYDic = new Dictionary<string, Tuple<float, float>>();
imageXYDic.Add("img1", new Tuple<float,float>(10,20));
imageXYDic.Add("img2", new Tuple<float, float>(200, 300));
HtmlToPdfHelper pdfHelper = new HtmlToPdfHelper(htmlStr, m_PdfSaveFolder, imageXYDic);
pdfHelper.BuilderPDF();//生成PDF
}
}
//图片转为base64字符串
public string ImageToBase64String(string imagePath)
{
try
{
Bitmap bitmap = new Bitmap(imagePath);
MemoryStream ms = new MemoryStream();
bitmap.Save(ms, ImageFormat.Jpeg);
byte[] bytes = new byte[ms.Length];
ms.Position = 0;
ms.Read(bytes, 0, (int) ms.Length);
ms.Close();
return Convert.ToBase64String(bytes);
}
catch (Exception ex)
{
throw new ApplicationException("图片转base64字符串时异常", ex);
}
}
}
}三、在网站的Scripts目录下添加person.htm 模版
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title></title>
</head>
<body>
<p>@PersonName</p>
<table border="1px">
<tr>
<td>
<img id="img1" src="data:image/jpeg;base64,@PersonImage1" style="width: 50px; height: 50px;"/>
</td>
</tr>
</table>
<img id="img2" src="data:image/jpeg;base64,@PersonImage2" style="width: 50px; height: 50px;" />
</body>
</html>四、在网站的Scripts目录下添加img1.jpg和imag2.jpg两张图片,在Content目录下添加从百度找的字体arialuni.ttf
五、在Default.aspx界面写入调用代码
public partial class _Default : Page
{
protected void Page_Load(object sender, EventArgs e)
{
PersonEntity personEntity = new PersonEntity();
personEntity.BuildPDF();
}
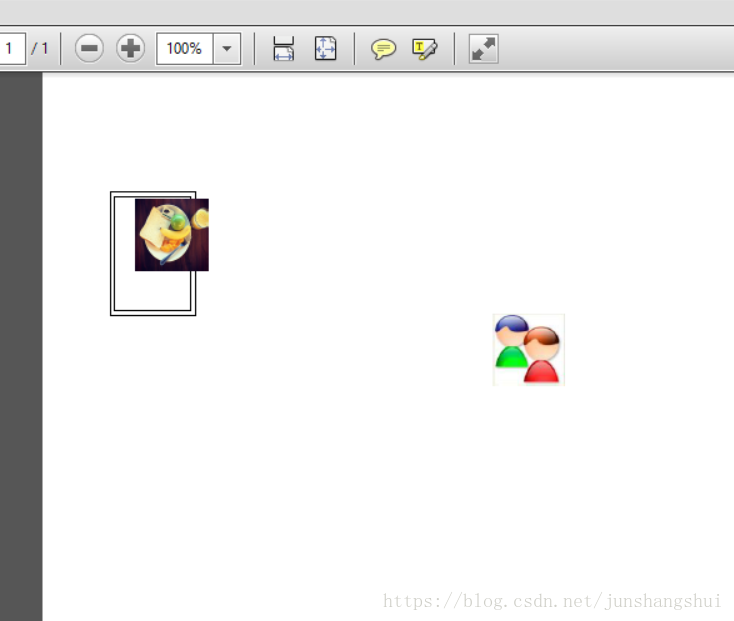
}六、运行Default.aspx页面后,将在网站目录PDFFolder中生成了一个PDF,效果如下图
七、源码在我上传的CSDN资源中 https://download.csdn.net/download/junshangshui/10561974