字符串是编程过程中最多的一种数据结构,对字符串的操作几乎无所不在
1、入门
实际上,就是字符匹配的问题, \d 匹配数字 \s 匹配空格 \w 匹配字母或者数字 ----------这种属于精准匹配,当然来说,我们还可以匹配多个,那么要怎么写那种匹配多个的呢??
\d{3}\s+\d{3,8}
我们来从左到右解读一下:
-
\d{3}表示匹配3个数字,例如'010'; -
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等; -
\d{3,8}表示3-8个数字,例如'1234567'。
2、进阶
(1)要做更精确地匹配,可以用[]表示范围,比如:
-
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线; -
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等; -
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量; -
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。
3、re
最常用的python的匹配就是 re 模块了
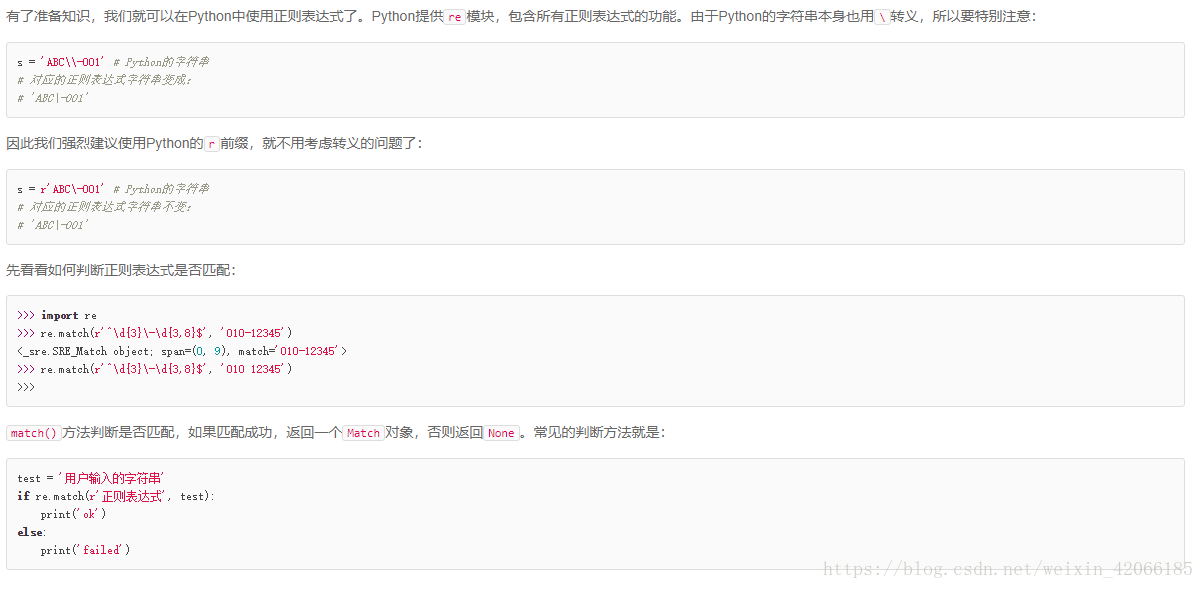
(2) 切分字符串
下面就是使用正则表达式的作用

(3)分组

(4)贪婪匹配
正则默认是贪婪匹配,也就是会自动默认的匹配尽可能多的字符串

