前言:
继:《天猫双11爬虫(福利:212万条商品数据免费下载)》。
程序:Github-Tmall1212。
本爬虫主要抓取参与天猫双12的商品数据,之前已经抓过双11的数据了,有兴趣做分析等研究用途的,可以拿去用。
本来这种活动数据时效性是比较高的,今天早上也已经把数据抓取完毕,但双12恰逢公司新品发布会。白天一直没空,晚上吃完饭回来就赶紧整理数据了。另外京东的数据不像天猫,参与活动的商品和未参与活动的商品是混在一起的,所以京东就没有抓了,望见谅。
数据说明:
数据和双11那份数据类似,也是主要有原始数据、活动数据、参数数据和图片数据。
天猫双12商品原始数据:
数据量:230801条、227356条。
说明:里面包括两份原始数据,是从网页中初步解析下来后的json文件,它是接下来三份数据的原始数据,信息最全,但也包含的很多无用字段。商品原始数据1.json主要是商品分类信息(例如一个手机商品,有内存、颜色、套餐等分类),商品原始数据2.json主要是双12活动的数据(例如内存A+颜色B+套餐C的手机,原价、现价、双12优惠信息等)。两个文件的每一条json都有个_id,它是商品ID,可以对照着网页上显示的数据查看各字段代表的意义。(商品链接形如:https://detail.tmall.com/item.htm?id=538420191509)
天猫双12商品活动数据:
数据量:2660485条。
说明:爬下来的商品ID总共是23万条,但是每一个商品,例如手机,它有内存、颜色、套餐等分类,选择不同的内存或者颜色,它们的价格和优惠活动都可能不同。所以选择不同的套餐,都会产生一条独立的活动数据。
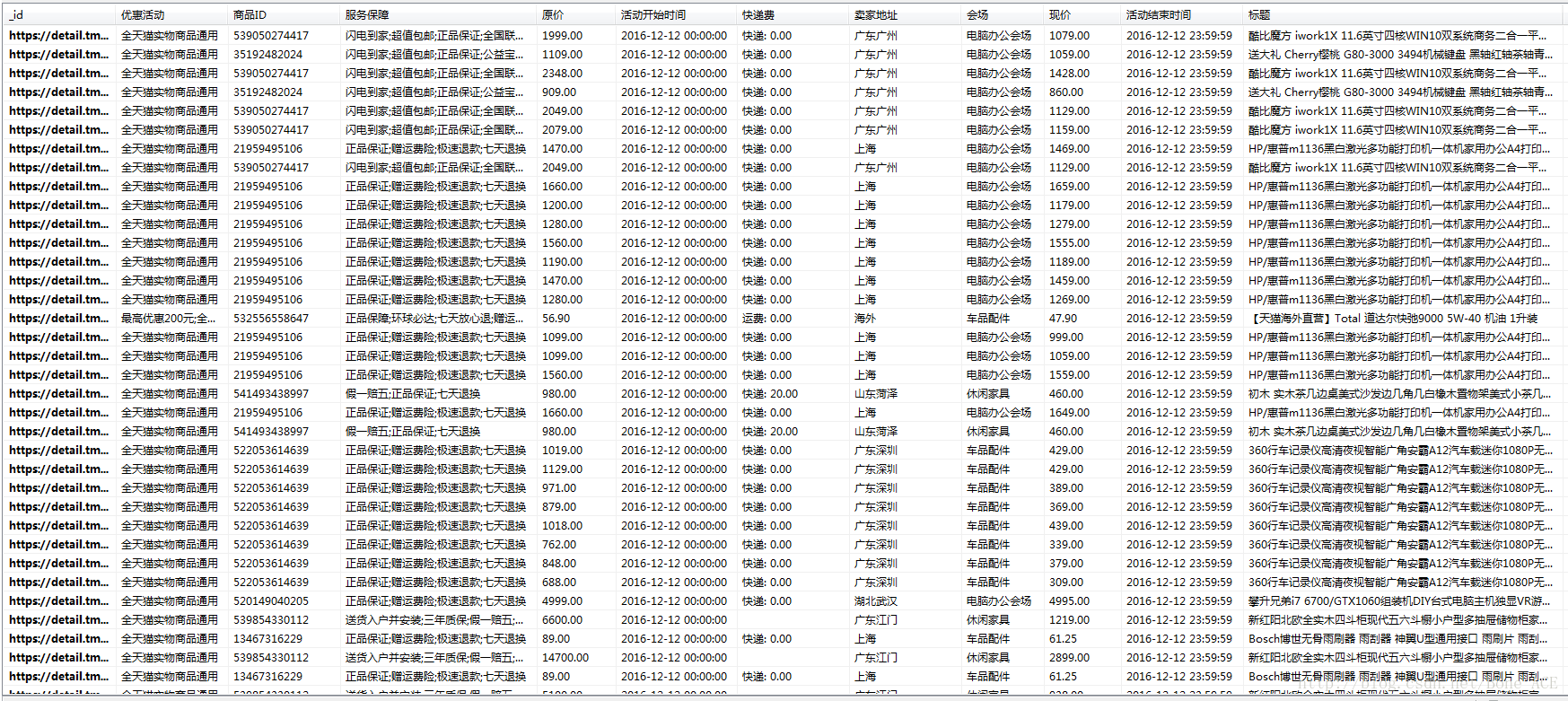
天猫双12商品参数数据:
数据量:230154条。
说明:在天猫或淘宝商品页面中,套餐和详细介绍之间,有一个“商品参数”,此为该参数数据。

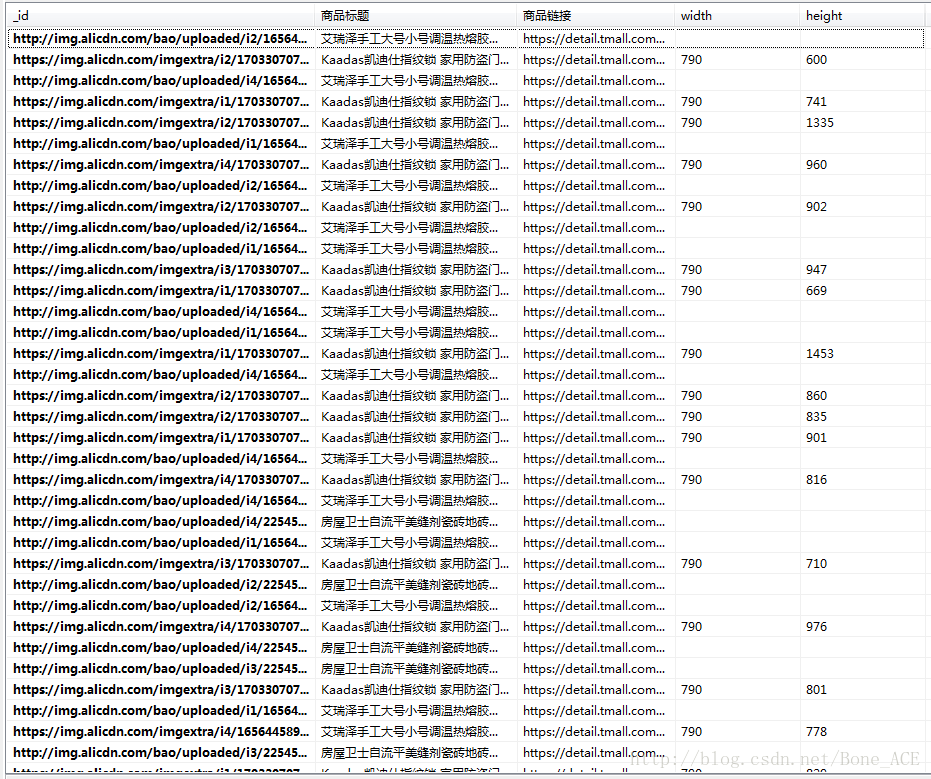
天猫双12商品图片数据:
数据量:3182177条。
说明:在商品介绍中有各种图片,此为该图片数据。
代码说明:
上面给出的是双12爬虫的代码,双11的爬虫代码大部分类似,可能平时也照样能够抓取数据。下面逐步解释:
- 程序主要分为两个步骤:从活动主页面入手,抓取到所有商品ID;根据商品ID抓取并解析商品信息。
- 双12活动主页面,里面有35个分会场,将链接解析放在 urldict.py。程序从分会场开始抓。
- 分会场的页面中,有些可点击进入商品详情页,有些可点击进入商店主页。进入商店主页以后可点击进入商品详情页。所以我们从分会场的主页可解析到部分商品ID,以及部分商店URL,进入商店URL再获取其他商品ID。汇总起来就是所有商品ID了。
- 但是天猫加载数据的方式有几种,一个是直接放在html中,一个是通过json加载,或者两者都用。所以在解析各分会场主页也好,解析商店住而已也好,几种情况都要做解析。
- step1.py解析各个分会场,step2.py解析appids(appids可构造json的请求URL,即处理step1.py里面的json调用),step3.py解析商店数据(从里面解析出商品ID,或json的url),step4.py处理商店中的json调用。4个步骤获取完所有商品ID。
- crawl_detail.py根据商品ID抓取商品页面,未解析。crawl_property根据商品ID抓取商品的参数数据,带解析。
- parser.py解析crawl_detail.py拿到的页面。至此,任务完成。
- crawl_img.py可根据图片数据去下载图片,一般人都不需要下这些图片吧。
代码时效性比较高,未作特别详细的介绍,有兴趣的可以跑一下,有疑问请留言。
注:我的CSDN博客正在评选“CSDN2016博客之星”,希望可以投我一票,谢谢!(投票链接:http://blog.csdn.net/vote/candidate.html?username=Bone_ACE)