思维导图
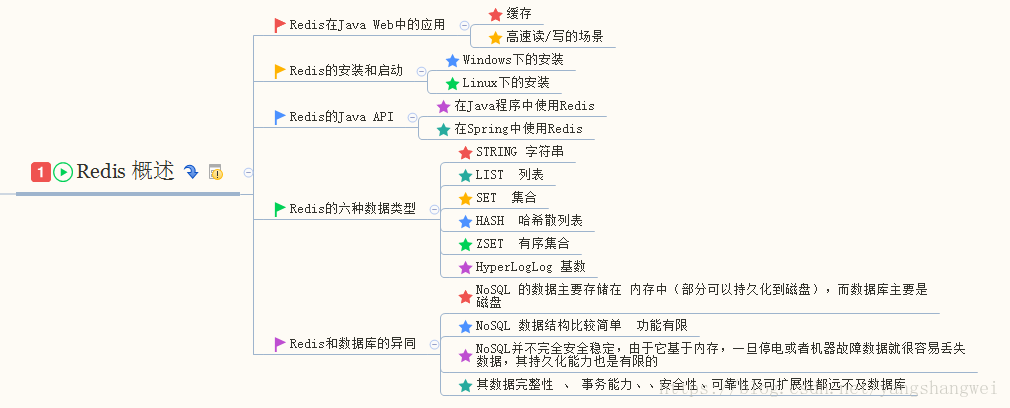
Redis概述
在传统的 Java Web 项目中, 使用数据库进行存储数据,弊端主要来自于性能方面。由于数据库持久化数据主要是面向磁盘,而磁盘的读/写比较慢.
如果不存在高并发,因此往往没有瞬间需要读/写大量数据的要求,这 个时候使用数据库进行读/写是没有太大的问题的,
在互联网中,往往存在大数据量的 需求 ,比如一些商品抢购的场景,或者是主页访问量瞬间较大的时候, 一瞬间成千上万的 请求就会到来 ,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是 数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务岩机的严重生产问题。
为了克服这些问题, Java Web 项目往往就引入了 NoSQL 技术, NoSQL 工具也是一种简易的数据库,它主要是一种基于内存的数据库,并提供一定的持久化功能。Redis 和MongoDB 是当前使用最广泛的 NoSQL。 我们这里来探讨Redis 。
Redis可以支持每秒十几万次的读/写操作,其性能远超数据库,并且支持集群、 分布式、 主从同步等配置,原则上可以无限扩展,让更多的数据存储在内存中,还能支持一定的事务能力,这在高并发访问的场景下保证数据安全和一致性非常重要。
Redis的优点
基于 ANSI C 语言编写的,接近于汇编语言的机器语言,运行十分快速
基于于内存的读/写,速度自然比数据库的磁盘读/写要快得多
数据库结构只有 6 种数据类型,数据结构比较简单,因此规则较少,而数据库则是范式,完整性、规范性需要考虑的规则比较多,处理业务会比较复杂
Redis 在 Java Web 中的应用
一般而言 Redis 在 Java Web 应用中存在两个主要的场景,
- 一个是缓存常用的数据
- 另一个是在需要高速读/写的场合使用它快速读/写, 比如一些需要进行商品抢购和抢红包的场合。
由于在高并发的情况下,需要对数据进行高速读/写 的场景, 一个最为核心的问题是数据一致性和访问控制,后续专门的章节来讨论。
缓存
一般而言在使用Redis 存储的时候,需要从 3 个方面进行考虑。
业务数据常用吗?命中率如何?如果命中率很低,就没有必要写入缓存。
该业务数据是读操作多,还是写操作多 ,如果写操作多 ,频繁需要写入数据库 ,也没有必要使用缓存。
业务数据大小如何?如果要存储几百兆字节的文件,会给缓存带来很大的压力,有没有必要?
在考虑过这些问题后,如果觉得有必要使用缓存,那么就使用它 。使用 Redis 作为缓 存的读取逻辑如下:

当第一次读取数据的时候,读取 Redis 的数据就会失败,此时会触发程序读取数据库,把数据读取出来,并且写入 Redis 。
当第二次及以后读取数据时,就直接读取 Redis , 读到数据后就结束了流程,速度就大大提高 。
从上面的分析可知,大部分的操作是读操作,使用 Redis 应对读操作,速度就会十分迅速,同时也降低了对数据库的依赖, 大大降低了数据库的负担。
分析了读操作的逻辑后,下面再来分析写操作的流程,
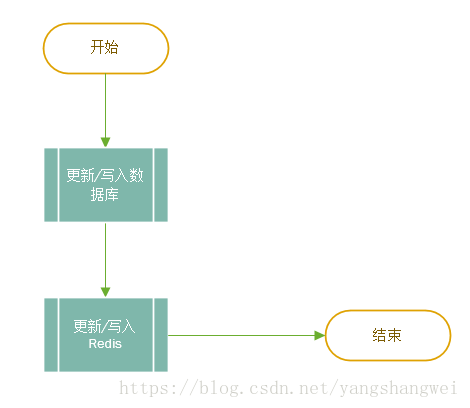
从上面的流程可以看出,更新或者写入的操作,需要多个 Redis 的操作 。 如果业务数据写次数远大于读次数没有必要使用 Redis。如果是读次数远大于写次数, 则使用 Redis 就有其价值了,因为写入 Redis 虽然要消耗一定的代价,但是其性能良好,相对数据库而言,几乎可以忽略不计 。
高速读/写
在互联网的应用中,往往存在一些需要高速读/写的场合,比如商品的秒杀,抢红包,淘宝、京东的双十一活动或者春运抢票等。这类场合在一个瞬间成千上万的请求就会达到服务器,如果使用的是数据库, 一个瞬间数据库就需要执行成千上万的 SQL,很容易造成数据库的瓶颈,严重的会导致数据库瘫痪,造成 Java Web 系统服务崩溃。
在这样的场合的应对办法往往是考虑异步写入数据库,而在高速读/写的场合中单单使用 Redis 去应对, 把这些需要高速读/写的数据 , 缓存到 Redis 中,而在满足一定的条件下,触发这些缓存的数据写入数据库中.
先看看一次请求操作的流程图 如下:
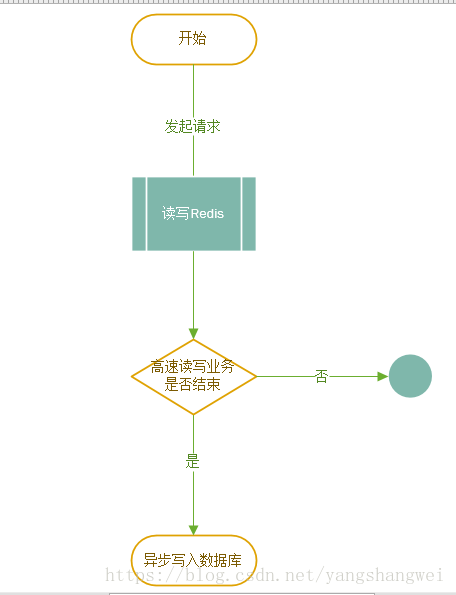
当一个请求达到服务器,只是把业务数据先在 Redi s 读/写,而没有进行任何对数据库的操作,换句话说系统仅仅是操作 Redis 缓存,而没有操作数据库,这个速度就比操作数据库要快得多,从而达到需要高速响应的效果。
但是一般缓存不能持久化,或者所持久化的数据不太规范,因此需要把这些数据存入数据库 ,所以在一个请求操作完 Redis 的读/写后,会去判断该高速读/写的业务是否结束。这个判断的条件往往就是秒杀商 品剩余个数为 0,抢红包金额为 0,如果不成立,则不会操作数据库;如果成立,则触发事件将 Redis 缓存的数据以批量的形式一次性写入数据库,从而完成持久化的工作。
假设面对的是一个商品秒杀的场景,从上面的流程看, 一个用户抢购商品,绝大部分的场合都是在操作内存数据库 Redis , 而不是磁盘数据库,所以其性能更为优越。只有在商品被抢购一空后才会触发系统把 Redis 缓存的数据写入数据库磁盘中 , 这样系统大部分的操作基于内存,就能够在秒杀的场合高速响应用户的请求,达到快速应答。
而现实中这种需要高速响应的系统会比上面的分析更复杂 , 因为这里没有讨论高并发下的数据安全和一致性问题,没有讨论有效请求和无效请求 、 事务一致性等诸多问题,这些后续独立讨论它 。
安装 Redis
Windows下安装Redis
请参考 实战SSM_O2O商铺_45【Redis缓存】配置Redis在Service层加入缓存
linux下安装Redis
在实际的工作中, Redis 往往安装在服务器端,服务器使用的是 Linux/Unix 系统.
在线安装的方式(前提主机可以联网),否则请选择离线安装
假设这里我们使用root用户将redis安装在/usr目录下
$ cd /usr/
$ mkdir redis
$ cd redis
$ wget http://download.redis.io/releases/redis-4.0.11.tar.gz
$ tar xzf redis-4.0.11.tar.gz
$ cd redis-4.0.11
$ make等待其执行完成, 然后在当前 目录下执行
src/redis-server这样就能够启动 Linux 的命令行窗口 了
6种数据类型
Redis 是 一种基于内存的数据库,并且提供 一定 的 持 久化功能,它 是一 种 键值( key-value )数据库,使用 key 作为索引找到 当前缓存的数据, 并且返回给程序调用 者。
当前的 Redis 支持 6 种数据类型,它们分别是字符串( String ) 、列表( List)、集合( set )、哈希结构( hash )、有序集合( zset)和基数( HyperLogLog )
| 数据类型 | 数据类型存储的值 | 说 明 |
|---|---|---|
| STRING (字符串) | 可以是保存字符串、整数和浮点数 | 可以对字符串进行操作 ,比如增加字符或在子串,如果是整数或者浮点数 , 可以实现计算,比如自增等 |
| LIST ( 列表) | 它是一个链表,它 的每一个节点都包 含一个字符串 | Redis支持从链表的两端插入或者弹出节点,或在通过偏移对它进行裁剪;还可以读取一个或者多个节点, 根据条件删除或者查找节点等 |
| SET (集合) | 它是一个收集器,但是是无序的,在它里面每一个元素都是一个字符串,而且是独一无二 , 各不相同的 | 可以新增、读取、删除单个元素 ; 检测一个元索是否在集合中,计算它和1其他集合的交集并集和差集等;随机从集合中读取元素 |
| HASH ( 哈希散列表) | 它类似于 Java 语言中的 Map,是一个键值对应的无序列表 | 可以附、删 、 查、改单个键值对, 也可以获取所有的键值对 |
| ZSET (有序集合〉 | 它是一个有序的集合 , 可以包含字符串、整数、浮点数、分值( score ) , 元素的排序是依据分值的大小来决定的 | 可以地、删、查、改元素,根据分值的泡因或者成员来获取对应的元素 |
| HyperLogLog (基数) | 它的作用是计算主复的值, 以确定存储的数量 | 只提供基数的运算,不提供返回的功能 |
如上表格粗略描述了 Redis 的 6 种数据类型 , 并简要说明了它们的作用,后面还会详细介绍它们的数据结构和常用 Redis 命令 。
此外, Red is 还支持一些事务 、 发布订阅消息模式、 主从复制、持久化等作为 Java 开发人员需要知道的功能。