版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_40178464/article/details/82082656
SequenceInputStream:几个输入流的逻辑串联,从第一个流的开始一直读到最后一个流的末尾,可以操作多个数据源,可用于碎片文件的合并
构造函数:
|- SequenceInputStream(Enumeration<? extends InputStream> e),可以用Vector(效率较低),Collections.enumeration实现枚举。
|- SequenceInputStream(InputStream s1, InputStream s2)
应用:实现文件的切割与合并
1.利用Vector和Collections实现枚举及耗时比较
public class SequenceInputStreamTest {
public static void main(String[] args) throws IOException {
long l1 = System.currentTimeMillis();
vectorShow();
long l2 = System.currentTimeMillis();
System.out.println("Vector耗时:" + (l2 - l1));
l1 = System.currentTimeMillis();
collectionShow();
l2 = System.currentTimeMillis();
System.out.println("Collection耗时:" + (l2 - l1));
}
/**
* 利用Vector实现枚举
* @throws IOException
*/
public static void vectorShow() throws IOException {
Vector<FileInputStream> v = new Vector<>();
v.add(new FileInputStream("a.txt"));
v.add(new FileInputStream("buf.txt"));
v.add(new FileInputStream("info.txt"));
Enumeration<FileInputStream> en = v.elements();
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream("demo1.txt");
byte[] buf = new byte[1024];
int len;
while ((len = sis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
fos.close();
sis.close();
}
/**
* 利用Collection实现枚举
* @throws IOException
*/
public static void collectionShow() throws IOException {
ArrayList<FileInputStream> arrayList = new ArrayList<>();
arrayList.add(new FileInputStream("a.txt"));
arrayList.add(new FileInputStream("buf.txt"));
arrayList.add(new FileInputStream("info.txt"));
Enumeration<FileInputStream> en = Collections.enumeration(arrayList);
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream("demo2.txt");
byte[] buf = new byte[1024];
int len;
while ((len = sis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
fos.close();
sis.close();
}
}结果:
Vector耗时:50
Collection耗时:122.实现文件切割:原文件大小为3.31 MB (3,471,366 字节)
public class FileSplit {
/**
* 定义碎片文件的大小
*/
private static final int SIZE = 1024 * 1024;
public static void main(String[] args) throws Exception {
File file = new File("d:\\往南.mp3");
splitFile(file);
}
private static void splitFile(File file) throws IOException {
// 读取源文件。
FileInputStream fis = new FileInputStream(file);
// 定义一个1M的缓冲区。
byte[] buf = new byte[SIZE];
FileOutputStream fos;
int len;
int count = 1;
/*
* 切割文件时,必须记录住被切割文件的名称,以及切割出来碎片文件的个数。 以方便于合并。
*/
Properties prop = new Properties();
// 碎片文件的存储地址
File dir = new File("g:\\partfiles");
if (!dir.exists()) {
dir.mkdirs();
}
while ((len = fis.read(buf)) != -1) {
fos = new FileOutputStream(new File(dir, (count++) + ".part"));
fos.write(buf, 0, len);
fos.close();
}
// 将被切割文件的信息保存到prop集合中。
prop.setProperty("partcount", String.valueOf(count));
prop.setProperty("filename", file.getName());
fos = new FileOutputStream(new File(dir, "split.properties"));
// 将prop集合中的数据生成配置文件
prop.store(fos, "split info");
fos.close();
fis.close();
}
}
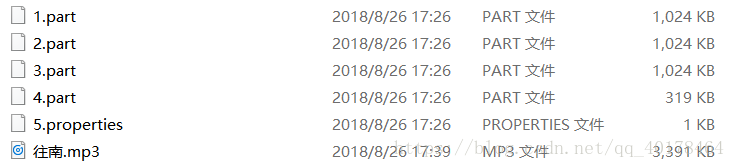
对应目录下的文件为:
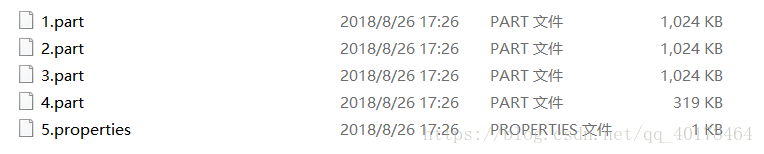
其中配置文件的内容为:
#split info
#Sun Aug 26 17:26:09 GMT+08:00 2018
filename=\u5F80\u5357.mp3
partcount=53.利用序列流实现碎片文件合并
public class FileMerge {
public static void main(String[] args) throws IOException {
File dir = new File("g:\\partfiles");
mergeFile(dir);
}
public static void mergeFile(File dir) throws IOException {
// 获取指定目录下的配置文件对象。
File[] files = dir.listFiles(new SuffixFilter(".properties"));
// 若有多个配置文件,则利用Properties读取时会出错
if (files.length != 1) {
throw new RuntimeException(dir + "目录下配置文件错误");
}
// 记录配置文件对象。
File confile = files[0];
// 获取该文件中的信息
Properties prop = new Properties();
FileInputStream fis = new FileInputStream(confile);
prop.load(fis);
// 还原原文件名
String filename = prop.getProperty("filename");
int count = Integer.parseInt(prop.getProperty("partcount"));
// 获取该目录下的所有碎片文件。
File[] partFiles = dir.listFiles(new SuffixFilter(".part"));
// 判断配置文件中的信息与文件夹中的碎片文件数量是否对应,这里的文件数量不包含配置文件
if (partFiles.length != (count - 1)) {
throw new RuntimeException("碎片文件不符合要求");
}
// 将碎片文件和流对象关联,并存储到集合中。
ArrayList<FileInputStream> al = new ArrayList<>();
for (int x = 0; x < partFiles.length; x++) {
al.add(new FileInputStream(partFiles[x]));
}
// 将多个流合并成一个序列流。
Enumeration<FileInputStream> en = Collections.enumeration(al);
SequenceInputStream sis = new SequenceInputStream(en);
// 输出到原目录
FileOutputStream fos = new FileOutputStream(new File(dir, filename));
byte[] buf = new byte[1024];
int len;
while ((len = sis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
fos.close();
sis.close();
}
}结果: