import requests
import re
class spider(object):
def __init__(self):
print (u'开始爬取内容。。。')
# getsource用来获取网页源代码
def getsource(self,url):
html = requests.get(url)
return html.text
# changepage用来生产不同页数的链接
def changepage(self, url, total_page):
now_page = int(re.search('pageNum=(\d+)', url, re.S).group(1))
page_group = []
for i in range(now_page,total_page+1):
link = re.sub('pageNum=\d+', 'pageNum=%s'%i, url, re.S)
page_group.append(link)
return page_group
# geteveryclass用来抓取每个课程块的信息
def geteveryclass(self, source):
everyclass = re.findall('<li id="\d+" test="0" deg="0"(.*?)</li>', source, re.S)
return everyclass
# getinfo用来从每个课程块中提取出我们需要的信息
def getinfo(self, eachclass):
info = {}
info['title'] = re.search('title="(.*?)" alt="', eachclass, re.S).group(1)
info['content'] = re.search('<p style="height: 0px; opacity: 0; display: none;">\s*(.*?)\s*</p>',
eachclass,re.S).group(1)
info['classtime'] = re.findall('<dd class="mar-b8"><i class="time-icon"></i><em>(.*?)\s\t\t\t\t\t\t\t(.*?)</em>', eachclass, re.S)
info['classlevel'] = re.findall('<i class="xinhao-icon\d*"></i><em>(.*?)</em>', eachclass, re.S)
info['learnnum'] = re.search('<em class="learn-number">(.*?)</em>', eachclass, re.S).group(1)
return info
# saveinfo用来保存结果到info.txt文件中
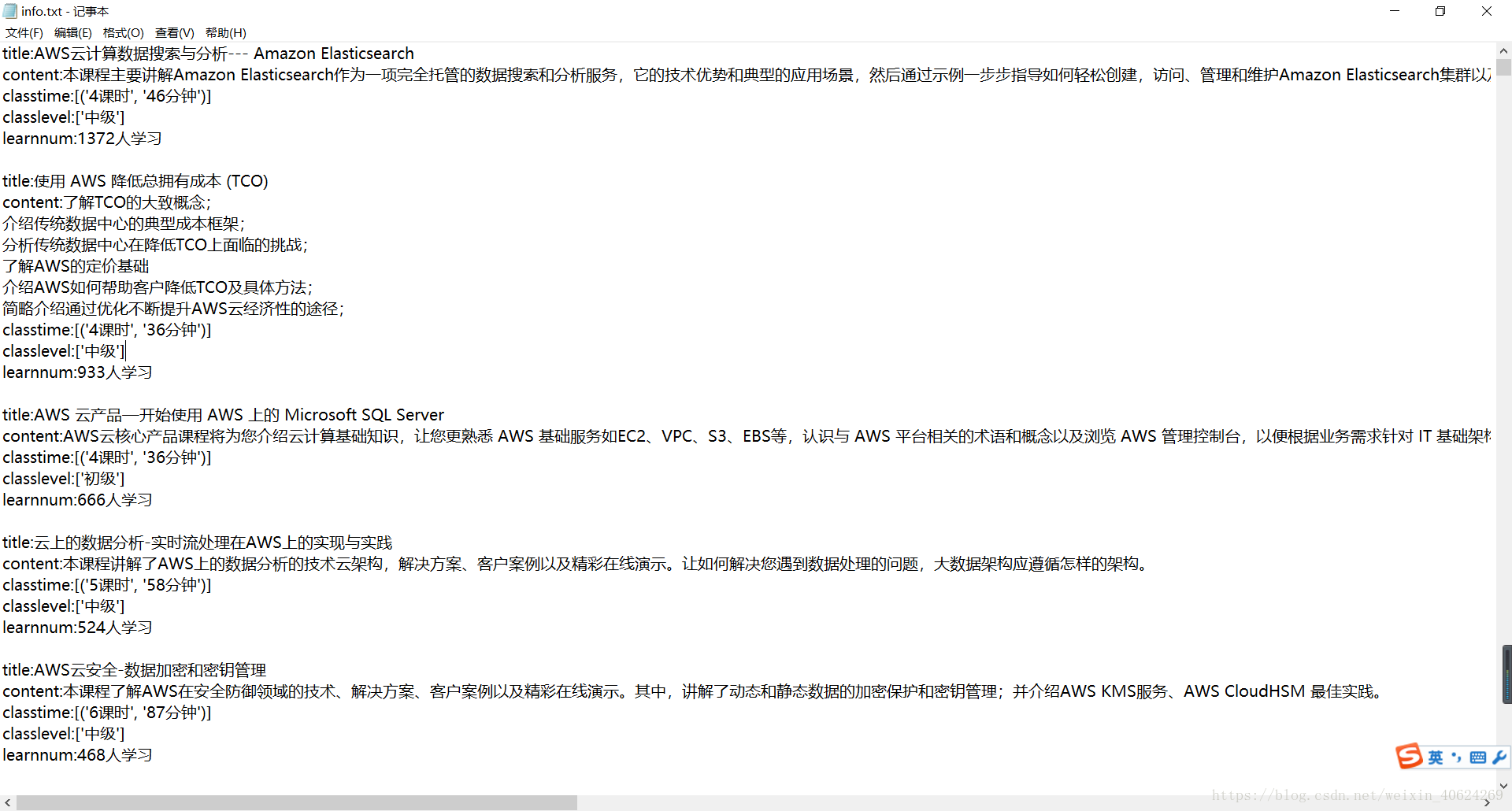
def saveinfo(self, classinfo):
with open('info.txt','w') as f:
for each in classinfo:
f.writelines('title:' + each['title'] + '\n')
f.writelines('content:' + each['content'] + '\n')
f.writelines('classtime:' + each['classtime'].__str__() + '\n')
f.writelines('classlevel:' + each['classlevel'].__str__() + '\n')
f.writelines('learnnum:' + each['learnnum'] +'\n\n')
if __name__ == '__main__':
classinfo = []
url = 'http://www.jikexueyuan.com/course/?pageNum=1'
jikespider = spider()
all_links = jikespider.changepage(url,20)
for link in all_links:
print (u'正在处理页面:' + link)
html = jikespider.getsource(link)
everyclass = jikespider.geteveryclass(html)
for each in everyclass:
info = jikespider.getinfo(each)
classinfo.append(info)
jikespider.saveinfo(classinfo)
结果如下