深入浅出:Java线程池(二)
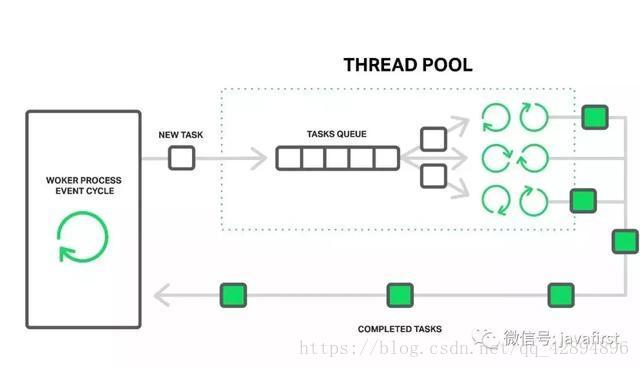
线程池是多线程编程中的核心概念,简单来说就是一组可以执行任务的空闲线程。
首先,我们了解一下多线程框架模型,明白为什么需要线程池。
线程是在一个进程中可以执行一系列指令的执行环境,或称运行程序。多线程编程指的是用多个线程并行执行多个任务。当然,JVM 对多线程有良好的支持。
尽管这带来了诸多优势,首当其冲的就是程序性能提高,但多线程编程也有缺点 —— 增加了代码复杂度、同步问题、非预期结果和增加创建线程的开销。
在这篇文章中,我们来了解一下如何使用 Java 线程池来缓解这些问题。
为什么使用线程池?
创建并开启一个线程开销很大。如果我们每次需要执行任务时重复这个步骤,那将会是一笔巨大的性能开销,这也是我们希望通过多线程解决的问题。
为了更好理解创建和开启一个线程的开销,让我们来看一看 JVM 在后台做了哪些事:
- 1.为线程栈分配内存,保存每个线程方法调用的栈帧。
2.每个栈帧包括本地变量数组、返回值、操作栈和常量池
3.一些 JVM 支持本地方法,也将分配本地方法栈
4.每个线程获得一个程序计数器,标识处理器正在执行哪条指令
5.系统创建本地线程,与 Java 线程对应
6.和线程相关的描述符被添加到 JVM 内部数据结构
7.线程共享堆和方法区
当然,这些步骤的具体细节取决于 JVM 和操作系统。
另外,更多的线程意味着更多工作量,系统需要调度和决定哪个线程接下来可以访问资源。
线程池通过减少需要的线程数量并管理线程生命周期,来帮助我们缓解性能问题。
本质上,线程在我们使用前一直保存在线程池中,在执行完任务之后,线程会返回线程池等待下次使用。这种机制在执行很多小任务的系统中十分有用。
Java 线程池
Java 通过 executor 对象来实现自己的线程池模型。可以使用 executor 接口或其他线程池的实现,它们都允许细粒度的控制。
java.util.concurrent 包中有以下接口:
- 1.Executor —— 执行任务的简单接口
2.ExecutorService —— 一个较复杂的接口,包含额外方法来管理任务和 executor 本身
3.ScheduledExecutorService —— 扩展自 ExecutorService,增加了执行任务的调度方法
除了这些接口,这个包中也提供了 Executors 类直接获取实现了这些接口的 executor 实例
一般来说,一个 Java 线程池包含以下部分:
- 1.工作线程的池子,负责管理线程
2.线程工厂,负责创建新线程
3.等待执行的任务队列
在下面的章节,让我们仔细看一看 Java 类和接口如何为线程池提供支持。
Executors 类和 Executor 接口
Executors 类包含工厂方法创建不同类型的线程池,Executor 是个简单的线程池接口,只有一个 execute() 方法。
我们通过一个例子来结合使用这两个类(接口),首先创建一个单线程的线程池,然后用它执行一个简单的语句:
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Single thread pool test"));注意语句写成了 lambda 表达式,会被自动推断成 Runnable 类型。
如果有工作线程可用,execute() 方法将执行语句,否则就把 Runnable 任务放进队列,等待线程可用。
基本上,executor 代替了显式创建和管理线程。
Executors 类里的工厂方法可以创建很多类型的线程池:
- 1.newSingleThreadExecutor():包含单个线程和无界队列的线程池,同一时间只能执行一个任务
2.newFixedThreadPool():包含固定数量线程并共享无界队列的线程池;当所有线程处于工作状态,有新任务提交时,任务在队列中等待,直到一个线程变为可用状态
3.newCachedThreadPool():只有需要时创建新线程的线程池
3.newWorkStealingThreadPool():基于工作窃取(work-stealing)算法的线程池,后面章节详细说明
接下来,让我们看一下 ExecutorService 接口提供了哪些新功能
ExecutorService
创建 ExecutorService 方式之一便是通过 Excutors 类的工厂方
ExecutorService executor = Executors.newFixedThreadPool(10);
Besides the execute() method, this interface also defines a similar submit() method that can return a Future object:
execute() 方法,接口也定义了相似的 submit() 方法,这个方法可以返回一个 Future 对象。
Callable<Double> callableTask = () -> {
return employeeService.calculateBonus(employee);
};
Future<Double> future = executor.submit(callableTask);
// execute other operations
try {
if (future.isDone()) {
double result = future.get();
}
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}从上面的例子可以看到,Future 接口可以返回 Callable 类型任务的结果,而且能显示任务的执行状态。
当没有任务等待执行时,ExecutorService 并不会自动销毁,所以你可以使用 shutdown() 或 shutdownNow() 来显式关闭它。
executor.shutdown()
ScheduledExecutorService
这是 ExecutorService 的一个子接口,增加了调度任务的方法。
ScheduledExecutorService executor = Executors.newScheduledThreadPool(10);schedule() 方法的参数指定执行的方法、延时和 TimeUnit
Future<Double> future = executor.schedule(callableTask, 2, TimeUnit.MILLISECONDS);另外,这个接口定义了其他两个方法:
executor.scheduleAtFixedRate(
() -> System.out.println("Fixed Rate Scheduled"), 2, 2000, TimeUnit.MILLISECONDS);
executor.scheduleWithFixedDelay(
() -> System.out.println("Fixed Delay Scheduled"), 2, 2000, TimeUnit.MILLISECONDS);scheduleAtFixedRate() 方法延时 2 毫秒执行任务,然后每 2 秒重复一次。相似的,scheduleWithFixedDelay() 方法延时 2 毫秒后执行第一次,然后在上一次执行完成 2 秒后再次重复执行。
在下面的章节,我们来看一下 ExecutorService 接口的两个实现:ThreadPoolExecutor 和 ForkJoinPool。
ThreadPoolExecutor
这个线程池的实现增加了配置参数的能力。创建 ThreadPoolExecutor 对象最方便的方式就是通过 Executors 工厂方法:
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(10);这种情况下,线程池按照默认值预配置了参数。线程数量由以下参数控制:
- 1.corePoolSize 和 maximumPoolSize:表示线程数量的范围
2.keepAliveTime:决定了额外线程存活时间
我们深入了解一下这些参数如何使用。
当一个任务被提交时,如果执行中的线程数量小于 corePoolSize,一个新的线程被创建。如果运行的线程数量大于 corePoolSize,但小于 maximumPoolSize,并且任务队列已满时,依然会创建新的线程。如果多于 corePoolSize 的线程空闲时间超过 keepAliveTime,它们会被终止。
上面那个例子中,newFixedThreadPool() 方法创建的线程池,corePoolSize=maximumPoolSize=10 并且 keepAliveTime 为 0 秒。
如果你使用 newCachedThreadPool() 方法,创建的线程池 maximumPoolSize 为 Integer.MAX_VALUE,并且 keepAliveTime 为 60 秒。
ThreadPoolExecutor cachedPoolExecutor
= (ThreadPoolExecutor) Executors.newCachedThreadPool();
The parameters can also be set through a constructor or through setter methods:这些参数也可以通过构造函数或setter方法设置:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
4, 6, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>()
);
executor.setMaximumPoolSize(8);ThreadPoolExecutor 的一个子类便是 ScheduledThreadPoolExecutor,它实现了 ScheduledExecutorService 接口。你可以通过 newScheduledThreadPool() 工厂方法来创建这种类型的线程池。
ScheduledThreadPoolExecutor executor
= (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(5);上面语句创建了一个线程池,corePoolSize 为 5,maximumPoolSize 无限制,keepAliveTime 为 0 秒。
ForkJoinPool
另一个线程池的实现是 ForkJoinPool 类。它实现了 ExecutorService 接口,并且是 Java 7 中 fork/join 框架的重要组件。
fork/join 框架基于“工作窃取算法”。简而言之,意思就是执行完任务的线程可以从其他运行中的线程“窃取”工作。
ForkJoinPool 适用于任务创建子任务的情况,或者外部客户端创建大量小任务到线程池。
这种线程池的工作流程如下:
- 1.创建 ForkJoinTask 子类
2.根据某种条件将任务切分成子任务
3.调用执行任务
4.将任务结果合并
5.实例化对象并添加到池中
创建一个 ForkJoinTask,你可以选择 RecursiveAction 或 RecursiveTask 这两个子类,后者有返回值。
我们来实现一个继承 RecursiveTask 的类,计算阶乘,并把任务根据阈值划分成子任务。
public class FactorialTask extends RecursiveTask<BigInteger> {
private int start = 1;
private int n;
private static final int THRESHOLD = 20;
// standard constructors
@Override
protected BigInteger compute() {
if ((n - start) >= THRESHOLD) {
return ForkJoinTask.invokeAll(createSubtasks())
.stream()
.map(ForkJoinTask::join)
.reduce(BigInteger.ONE, BigInteger::multiply);
} else {
return calculate(start, n);
}
}
}这个类需要实现的主要方法就是重写 compute() 方法,用于合并每个子任务的结果。
具体划分任务逻辑在 createSubtasks() 方法中:
private Collection<FactorialTask> createSubtasks() {
List<FactorialTask> dividedTasks = new ArrayList<>();
int mid = (start + n) / 2;
dividedTasks.add(new FactorialTask(start, mid));
dividedTasks.add(new FactorialTask(mid + 1, n));
return dividedTasks;
}最后,calculate() 方法包含一定范围内的乘数。
private BigInteger calculate(int start, int n) {
return IntStream.rangeClosed(start, n)
.mapToObj(BigInteger::valueOf)
.reduce(BigInteger.ONE, BigInteger::multiply);
}接下来,任务可以添加到线程池:
ForkJoinPool pool = ForkJoinPool.commonPool();
BigInteger result = pool.invoke(new FactorialTask(100));eadPoolExecutor 与 ForkJoinPool 对比
初看上去,似乎 fork/join 框架带来性能提升。但是这取决于你所解决问题的类型。
当选择线程池时,非常重要的一点是牢记创建、管理线程以及线程间切换执行会带来的开销。
ThreadPoolExecutor 可以控制线程数量和每个线程执行的任务。这很适合你需要在不同的线程上执行少量巨大的任务。
相比较而言,ForkJoinPool 基于线程从其他线程“窃取”任务。正因如此,当任务可以分割成小任务时可以提高效率。
为了实现工作窃取算法,fork/join 框架使用两种队列:
- 1.包含所有任务的主要队列
2.每个线程的任务队列
当线程执行完自己任务队列中的任务,它们试图从其他队列获取任务。为了使这一过程更加高效,线程任务队列使用双端队列(double ended queue)数据结构,一端与线程交互,另一端用于“窃取”任务。
来自The H Developer的图很好的表现出了这一过程:
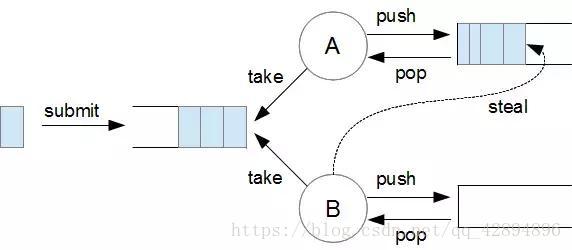
和这种模型相比,ThreadPoolExecutor 只使用一个主要队列。
最后要注意的一点 ForkJoinPool 只适用于任务可以创建子任务。否则它和 ThreadPoolExecutor 没区别,甚至开销更大。
跟踪线程池的执行
现在我们对 Java 线程池生态系统有了基本的了解,让我们通过一个使用了线程池的应用,来看一看执行中到底发生了什么。
通过在 FactorialTask 的构造函数和 calculate() 方法中加入日志语句,你可以看到下面调用序列:
13:07:33.123 [main] INFO ROOT - New FactorialTask Created
13:07:33.123 [main] INFO ROOT - New FactorialTask Created
13:07:33.123 [main] INFO ROOT - New FactorialTask Created
13:07:33.123 [main] INFO ROOT - New FactorialTask Created
13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created
13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created
13:07:33.123 [main] INFO ROOT - New FactorialTask Created
13:07:33.123 [main] INFO ROOT - New FactorialTask Created
13:07:33.123 [main] INFO ROOT - Calculate factorial from 1 to 13
13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created
13:07:33.123 [ForkJoinPool.commonPool-worker-2] INFO ROOT - New FactorialTask Created
13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - New FactorialTask Created
13:07:33.123 [ForkJoinPool.commonPool-worker-2] INFO ROOT - New FactorialTask Created
13:07:33.123 [ForkJoinPool.commonPool-worker-1] INFO ROOT - Calculate factorial from 51 to 63
13:07:33.123 [ForkJoinPool.commonPool-worker-2] INFO ROOT - Calculate factorial from 76 to 88
13:07:33.123 [ForkJoinPool.commonPool-worker-3] INFO ROOT - Calculate factorial from 64 to 75
13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - New FactorialTask Created
13:07:33.163 [main] INFO ROOT - Calculate factorial from 14 to 25
13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - New FactorialTask Created
13:07:33.163 [ForkJoinPool.commonPool-worker-2] INFO ROOT - Calculate factorial from 89 to 100
13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - Calculate factorial from 26 to 38
13:07:33.163 [ForkJoinPool.commonPool-worker-3] INFO ROOT - Calculate factorial from 39 to 50你可以看到创建了很多任务,但只有 3 个工作线程 —— 所以任务通过线程池被可用线程处理。
也可以看到在放到执行池之前,主线程中对象如何被创建。
使用 Prefix 这一类可视化的日志工具是一个很棒的方式来探索和理解运行时的线程池。
记录线程池日志的核心便是保证在日志信息中方便辨识线程名字。Log4J2 通过使用布局能够很好完成这种工作。
使用线程池的潜在风险
尽管线程池有巨大优势,你在使用中仍会遇到一些问题,比如:
用的线程池过大或过小:如果线程池包含太多线程,会明显的影响应用的性能;另一方面,线程池太小并不能带来所期待的性能提升。
正如其他多线程情形一样,死锁也会发生。举个例子,一个任务可能等待另一个任务完成,而后者并没有可用线程处理执行。所以说避免任务之间的依赖是个好习惯。
等待执行时间很长的任务:为了避免长时间阻塞线程,你可以指定最大等待时间,并决定过期任务是拒绝处理还是重新加入队列。
为了降低风险,你必须根据要处理的任务,来谨慎选择线程池的类型和参数。对你的系统进行压力测试也是值得的,它可以帮你获取真实环境下的系统行为数据。
结论
线程池有很大优势,简单来说就是可以将任务的执行从线程的创建和管理中分离。另外,如果使用得当,它们可以极大提高应用的性能。
如果你学会充分利用线程池,Java 生态系统好处便是其中有很多成熟稳定的线程池实现。
那如何学习才能快速入门并精通呢?
当真正开始学习时难免不知从何入手,从而导致效率低下影响继续学习的信心。
但最重要的是不知道需要重点掌握哪些技术,学习时频繁踩坑,最终浪费大量时间。
为了让学习变得轻松高效, 现在给大家提供一个学习平台,让你在实践中积累经验掌握原理。主要方向是JAVA架构师,在这里你可以学习Java工程化、高性能及分布式、深入浅出、性能调优、Spring,MyBatis,Netty源码分析和大数据等知识点。可以加QQ:3136292260,或是关注微信公众号:Java资讯库,免费的大型互联网Java技术视频分享给大家。