版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/yerenyuan_pku/article/details/78245773
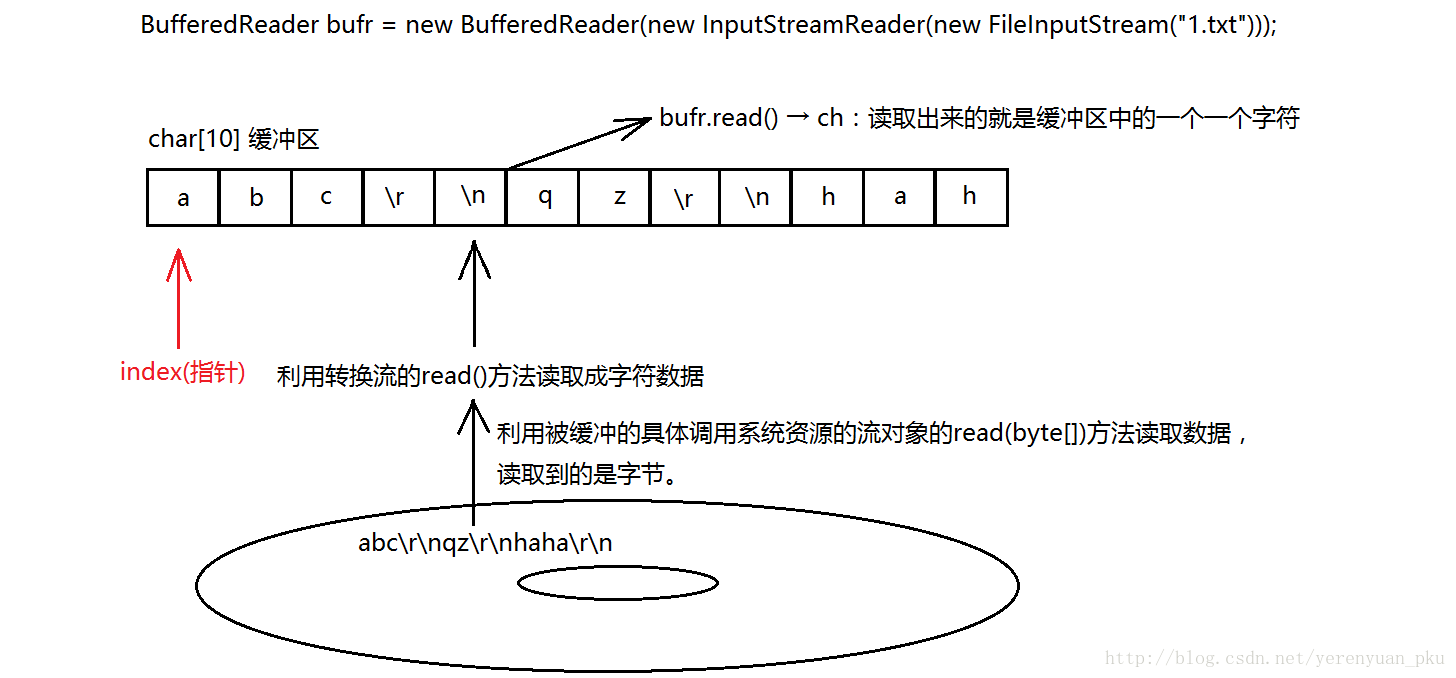
上一篇文章中已经介绍完了字符流的两个缓冲区对象——BufferedWriter和BufferedReader,而缓冲区的原理我们并没搞明白,本文就来揭示其正面目了。缓冲区的原理——临时存储数据的方式,减少了对设备操作的频率,提高了效率,其实就是将数据临时缓存到了内存(数组)中。下面我们就来分别模拟BufferReader类的read()方法缓冲区实现和其readLine()方法缓冲区实现。
BufferReader类的read()方法缓冲区实现
有这样一个需求:我们知道BufferReader类中有一个read()方法,现在要自定义一个类中包含一个功能和read()一致的方法,来模拟一下BufferReader。
下面我编写一个我自己的MyBufferedReader类,并在其中实现一个myRead()方法来模拟BufferReader类的read()方法,示例代码如下:
public class MyBufferedReader {
// 1、持有一个流对象。
private Reader r;
// 2、因为是缓冲区对象,所以内部必然维护了一个数组。
private char[] buffer = new char[1024];
// 3、定义一个角标。
private int index = 0;
// 4、定义变量,记录住数组中元素的个数。
private int count = 0;
// 一初始化,就必须明确被缓冲的对象。
public MyBufferedReader(Reader r) {
super();
this.r = r;
}
/**
* 读取一个字符的方法,而且是高效的。
* @throws IOException
*/
public int myRead() throws IOException {
if (count == 0) {
// 通过被缓冲的流对象的read方法,就可以将设备上的数据存储到数组中。
count = r.read(buffer);
index = 0;
}
if (count < 0) {
return -1;
}
char ch = buffer[index];
index++; // 角标每取一次都要自增。
count--; // 既然取出一个,数组的数量就要减少,一旦减到0,就从设备上获取一批数据存储到数组中。
return ch;
}
}不理解以上代码没关系,下面我会图解,如下: