Facebook是目前世界上最著名的社交网站,月活跃用户已超过10亿,每日登陆网站的用户超过6亿。如果从数据抽象的角度来看,Facebook的社交图不仅包括好友之间的关系,还包括人和实体以及实体之间的关系,每个用户,每个页面,每张图片,每个应用,每个地点以及每个评论都可以作为独立实体,用户喜欢某个页面则建立了用户和页面之间的关系,用户在某个地点签到则建立了用户和地点之间的关系……如果将每个实体看作图中的节点,实体之间的关系看作是图中的有向边,则Facebook的所有数据会构成超过千亿条边的巨量实体图(Entity Graph)。实体图中的关系有些是双向的,比如朋友关系,有些则是单向的,比如用户在某个地点签到。同时实体还具有自己的属性,比如某个用户毕业于斯坦福大学,出生于1988年等,这些都是用户实体的属性。图1是Facebook实体图的一个示意片段。
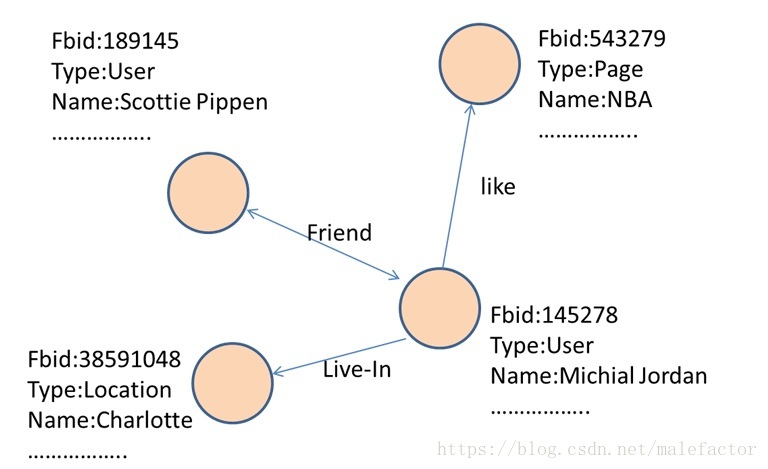
图1 Facebook实体图(Fbid是Facebook内部唯一ID编号)
对这个巨大实体图的搜索需求可以分为两类,一类是对于某类实体的搜索,常见的需求是根据实体名称搜索具体实体,实体图中的用户,图片,应用,地点等都可以成为被搜索的对象,比如搜索者搜索“Jordan”,搜索系统将所有名字里包含Jordan的其它用户搜索出来;另外一类搜索需求涉及到实体之间的关系,比如“Jordan都有哪些朋友”。
GraphSearch的定位就是成为能够让用户采用自然语言界面既能够搜索实体,也能够搜索实体关系的社交搜索引擎。这里需要强调的是:Graph Search不仅仅是传统的关键词搜索,还允许用户用自然语言来对结果进行搜索,即用户可以直接提问:”Facebook有哪些员工是华人”,而其可以通过自然语言处理技术理解用户真正想搜的内容,并给出精准的搜索结果。使用Graph Search,可以在这个巨量实体图上搜索类似以下复杂的自然语言查询:
a.Facebook的员工喜欢的餐馆有哪些;
b.毕业于斯坦福大学的人都喜欢看什么电影;
c.我的朋友喜欢去的旅游景点有哪些;
Facebook Graph Search是如何做到这一点的呢?为了理解其内部运行机制, 需要先了解Graph Search的倒排索引服务Unicorn系统。
Unicorn:Graph Search的基石
倒排索引是搜索引擎最重要的基础构件之一。对于通用的网页搜索引擎比如百度谷歌来说,倒排索引的功能是建立单词到出现过这个单词的网页列表之间的映射关系,这样,当用户输入某个查询词,搜索系统通过倒排索引找到出现过这个搜索词对应的网页列表,并按照若干排序因子对搜索结果排序,这样就完成了一次搜索过程。
Unicorn是建立在具有接近百亿节点的实体图上的倒排索引服务架构。与一般的网页搜索倒排索引不同,Unicorn具有几个独特的特性和挑战:
1. 不仅要对实体名称、评论内容等传统的文本内容进行索引,还需要对社交关系(朋友关系)用户行为(用户标记某个页面为liked)等建立索引。这里面临的技术挑战是:如何将社交关系这种涉及多实体关系的数据存入索引结构?
2. 为了能够快速响应用户查询,Unicorn会将几十亿节点以及千亿以上的边信息对应的索引结构保存在服务器内存中。传统的搜索引擎尽管也需要处理百亿级别的网页数据,但是索引结构往往是存储在磁盘中,通过外存索引加内存Cache的模式来加快查找速度。对于全内存的存储方式,如何设计整体架构来保存这种海量信息是非常有技术难度的。
3. 为了能够支持类似“Facebook的员工都喜欢什么餐馆”这种复杂查询,Unicorn定义了一套独具特色的集合操作符,通过操作符的嵌套与组合,不仅可以支持类似的复杂查询,还可以兼顾搜索的社交属性及搜索结果的多样性。
下面将从Unicorn的数据模型、整体架构及其定义的独具特色的集合操作符来讲解Facebook的技术人员是如何应对这些技术挑战的。
Unicorn的数据模型

图2. 社交关系倒排列表与内容倒排列表
作为实体图的倒排索引,Unicorn与常见的倒排索引有一定差异。通常的倒排索引由所有网页中出现的单词项Term及其对应的倒排列表(Posting List)构成。倒排列表往往由一系列倒排列表项(Posting)构成,每个倒排列表项包含网页ID,单词在网页中出现的次数以及单词在网页中出现的位置信息等构成。
Unicorn的倒排索引与传统倒排索引有三个主要不同点(参考图2):
首先,Unicorn的单词项不仅仅包含了传统的单词,也将社交关系或者用户行为引入。为了表达节点之间的关系,可以构造<edge-type>:<ID>作为单词项来表达某个节点通过社交形成的边或者用户行为边,这里<edge-type>代表了边的类型,<ID>代表了节点的内部唯一编号,比如friend:5作为单词项的含义是节点5的朋友关系,而likes:5则代表了节点5喜欢哪些页面这种用户行为。
其次,倒排列表中的倒排列表项(Posting)包含的内容也与传统倒排列表有很大差异。Unicorn的倒排列表项由(DocID,HitData)构成,其中DocID又由(Sort-Key,ID)两项元素组成。Sort-Key是整型数值,代表了这个索引项的全局重要性,倒排列表项按照Sort-Key大小降序排列,最重要的项目排在前列,这样有利于搜索时采取截断等操作来快速找到优质的满足搜索条件内容。如果两个索引项Sort-Key相同,则按照ID值由小到大升序排列。HitData保存的数据与具体应用相关,不同的应用可能会在这里存储不同的数据。HitData常见的应用场景是对搜索结果进行进一步的过滤,比如图2中所示的例子,单词项“MIT”中的倒排列表中列出了毕业于麻省理工学院的图节点ID列表,而对应的HitData中则存储了每个毕业于麻省理工人员对应的毕业日期和专业信息,这样可以对搜索结果进行进一步的过滤,比如可以指定毕业于计算机专业(CS)的MIT毕业生等复杂查询。
另外,Unicorn的特点是将所有倒排索引信息都存储在服务器内存中。这样可以快速响应用户查询,但是考虑到实体图数量以亿计,非常巨大,单机的内存远远没有足够资源对其进行存储,必然采取分布式集群的方式来对索引数据进行管理,至于如何对如此海量数据进行高效管理,本文的整体架构小节会对此有讲解。
上述内容描述了Unicorn的倒排索引数据模型,除此外,Unicorn还需要维护社交图节点的正向索引(Forward Index)。所谓正向索引,就是以(key,value)形式存在的数据,其中key是图节点的ID,value则会存储图节点的一些属性信息,这些信息可以用来对搜索结果内容展示或者进行一些条件过滤。
Unicorn的整体架构

图3 Unicorn整体架构图
Unicorn的整体架构分为树状的四层结构(图3):顶层聚集器,垂直聚集器,RACK聚集器以及索引服务器。顶层聚集器负责接收用户查询并根据搜索结果类型将查询分发到对应的垂直聚集器中(比如搜索结果是“用户“类型,则分发给”用户“类型垂直聚集器),同时从垂直聚集器接收返回结果做些优选返回给用户。垂直聚集器从顶层聚集器接收用户查询,并将查询分发到RACK聚集器。RACK聚集器同样将查询分发给RACK内所有索引服务器并合并截断索引服务器返回的结果,RACK聚集器的优势在于同一机柜内服务器通信效率高。索引服务器负责在内存维护社交图部分数据(Shard)的倒排索引,同时索引服务器负责and/or等集合操作来获得本部分数据的搜索结果,一般一个索引服务器能够索引几十亿条倒排列表信息。
不同垂直聚集器包含的RACK数量有很大差异,这是由该种类型数据在实体图中的数量决定的,比如“用户”类型的图节点以十亿计数,所以必然需要较多数量的机器,而“应用”类型的数据相比之下所需资源会少很多。
考虑到数据的可用性,Unicorn以垂直聚集器为单位进行数据冗余备份。如果某个索引服务器负责的数据发生故障,RACK聚集器负责将相应的请求转发到其它垂直聚集器里对应的备份数据中。
Unicorn的查询语言
为了能够支持复杂的应用查询逻辑,Unicorn定义了一些集合操作符,查询语言通过组合这些查询操作符可以表达复杂查询逻辑。
最常用和最简洁的操作符是Term操作符,其含义是直接读取某个Term的倒排列表,比如(Term friend:5)代表的语义是找出fbid为5的节点的所有朋友关系;
常见的集合操作符还包括And/Or/Difference操作,分别代表对两个集合的交集、并集及差集运算。比如(andfriend:5 friend:6)代表找出同时是节点5和节点6朋友的人员集合;(or friend:5 friend 6)代表找出节点5的朋友或者节点6的朋友集合;(difference friend:5 friend:6)代表找出是节点5的朋友而不是节点6的朋友集合。
除了上面提及的常见集合操作符号外,Unicorn另外定义了三个独具特色的集合操作符:Weak-And/Strong-Or/Apply。
Weak-And操作符
为了增加搜索结果排序的社交化效果,可以考虑将搜索结果限定在发出搜索查询词用户的朋友圈内。比如用户Jones(假设该用户内部Fbid=3)发出查询“Mark”,不考虑社交因素的方式可以直接将名字里包含Mark的用户列表找出(即查询:(Term Mark));如果考虑社交因素,可以将搜索结果范围限定在搜索者Jone的朋友圈内(即查询:(And Mark friend:3))。
但是如果所有查询都这样操作也会带来相应的问题:搜索范围限制得过于死板和严格。如果严格按照上述逻辑,可能存在质量较好的搜索结果,但其不在搜索用户的朋友圈内,这样就将这种高质量的搜索结果排除在外了。为了解决上述矛盾,Unicorn引入了Weak-And操作符,顾名思义,这是对And操作符的一种弱化和条件放松。Weak-And允许一定比例或者个数的搜索结果不需要满足所有条件也可以进入最终搜索结果队列。

图 4. Weak-and操作符
假设当前用户Jones(fbid=3)搜索“manlanie mars”,图4是内存中对应这个搜索的索引结构。如果Graph Search在内部施加了Weak-and操作符,其对应的内部查询语言为:(weak-and (termfriend:3 :optional-hits 2) (termmanlanie)(term mars))。对应这条查询语言,Graph Search返回给用户的结果是ID列表:15,20,7,57,其中,7和57属于同时满足三个条件的结果,而因为weak-and指出了friend:3的optional-hits条件为2,意思是结果中最多允许2个结果不在Jones的朋友圈中,Sort-Key较高的15和20不在Jones的朋友圈中,已经将这两个指标占满,所以75这个结果就不再展示给用户。Weak-and除了可以采用指定个数外,还可以用optional-weight的方式按照结果比例指定结果分布。
Strong-Or操作符
与Weak-And操作符相对应,Unicorn提出了针对Or操作符的改进Strong-Or操作符。这个操作符强制规定:满足某些搜索条件的搜索结果数目必须达到总体结果的指定比例。比如下面的例子:
(stong-or friend:3
(and friend:3 live-in:100 :optional-weight 0.2)
(and friend:3 live-in:101 :optional-weight 0.3) )
其语义代表了查找Jones的朋友,同时要求其中至少20%的朋友居住在北京(fbid=100),至少30%的朋友居住在洛杉矶(fbid=101)。至于其他50%的结果对其居住地不做任何限制。 通过这种方式可以采用灵活的方式强制搜索结果增加多样性。
Apply操作符
因为Facebook的所有信息构成了巨大的实体图,很多实际应用会有顺着图中节点沿着边进行游走遍历的操作。对于一度关系遍历,Unicorn已经通过索引将其建立到索引信息中,可以一次读取直接获得,但是对于二度遍历甚至更高度的遍历,则无法直接从索引中一次性读出。
假设某个用户希望找到:Jones的朋友喜欢哪些页面,这是一个典型的社交图上的二度遍历操作。一个很直接的解决方案如下:首先可以构造查询,找出Jones的朋友,即(friend:3 ),假设结果是fbid为5和6的人,Unicorn的顶层聚集器在接收到这个搜索结果后,构造另外一个查询就可以找出这些人喜欢的页面,即(or likes:5 likes:6)。这样,一个二度遍历操作可以转化为分别由and和or连续的两次查询来解决问题。
Apply就是直接使用单个表达符号来完成上述逻辑的操作符。如果一个二度遍历可以由第一步的and操作符,以及对第一步的搜索结果采用or操作符来构造,那么就可以使用Apply操作一步到位。比如上面的例子就可以用:(Apply likes:friend:3)来完成。
Graph Search
如何建立索引
Graph Search具有两种不同类型的索引建立通道,一条通道是批处理类型的,一次处理大批量待索引的数据;另外一条通道是为了保证信息更新的时效性而建立的接近实时的索引更新通道。
批处理索引通道的原始数据存储在数据库中,通过Hive可以对这些数据进行访问。在建立索引的时候,只需要程序员写少量代码将Hive中的每行数据转换为(term,sort-key,id,HitData)这种格式,系统提供了Hadoop例程来自动将这种格式的数据转换为Unicorn的索引,并将其拷贝到对应的索引服务器中。
近实时索引通道通过Scribe来作为连接更新数据和索引的联系通道。当实体图数据发生变化时,将这种数据变化写入Scribe系统,然后Scribe系统会以Thrift客户端形式将变化的数据写入索引系统。
搜索过程
用户利用GraphSearch完成一次完整的搜索涉及两个连续的过程:搜索建议阶段和搜索阶段。当用户输入查询内容时,GraphSearch会通过自然语言处理模块试图理解用户的搜索意图并给出若干搜索建议,当用户点击某个搜索建议后,系统进行真正的搜索并将搜索结果返回给用户。
在搜索建议阶段,自然语言处理模块试图将用户当前输入通过句法分析构建一颗句法树,同时这个模块将用户输入中的某些片段识别为可能的实体类型(地点,人名等),并将这些片段提交Unicorn系统,同时根据Unicorn的搜索结果来构建各种可能的句法分析树,并赋予每个句法分析树不同权重,然后选择得分较高的句法分析结果作为提示用户的内容。比如用户输入“friends at Facebook”,自然语言处理模块会建议:Friends whowork at Facebook,以此作为猜测的用户搜索意图。
当用户选择了某个搜索建议进行搜索时,Graph Search将对应的句法树和在上一阶段搜索获得的实体内部ID提交给Unicorn的顶层聚集器,自然语言解析的结果以用户可读的方式展示在对应的搜索URL中,比如用户搜索:restaurants liked by Facebook employees,其对应的URL包含:
273819889375819/places/20531316728/employees/places-liked/intersect
这里的273819889375819是系统内部中“餐馆”对应的类别ID,20531316728是“Facebook”实体对应的内部ID,这个URL已经能够在一定程度上以内部操作符的方式代表用户的搜索意图:求餐馆类型的地点实体和facebook员工喜欢的地点实体的交集。
当顶层聚集器收到上述URL,可以形成一个查询规划:首先在某个垂直聚集器进行查询,根据查询结果构建新的内部查询语言,将其提交给另外一个垂直聚集器,以此类推可以序列执行一系列查询并得到最终结果。以上面的例子来说明,首先向“用户”这个类别的垂直聚集器提交查询(term employee:20531316728),即查找Facebook的员工信息列表,假设返回n个结果fbid1,fbid2…..fbidn,那么形成新的查询:(andplace-kind:273819889375819 (or liked-by:fbid1 liked-by:fbid2 ... liked-by:fbidn)),并提交给“地点”类型的垂直聚集器,返回的结果就是用户希望获得的搜索结果。结合上文提到的Unicorn整体架构图,我们可以梳理出上述查询的整个执行流程如下:
Step 1:句法分析树及对应实体ID提交给顶层聚集器,聚集器形成查询规划;
Step 2:为“用户”类型的垂直聚集器准备好查询:(term employee:20531316728)
Step 3:顶层聚集器有时会根据用户个人信息改写上述查询,主要是加入社交因素并通过weak-and或者Strong-or来保证社交因素起作用的同时也能一定程度上保证搜索结果的多样性;
Step 4:”用户“类型垂直聚集器接收到查询并将其通过RACK聚集器分发给所有索引服务器;
Step 5:每个索引服务器从自己维护的索引中检索出部分用户实体的结果,对结果打分排序并将得分较高的部分用户实体返回给“用户“类型垂直聚集器;
Step 6:垂直聚集器收集各个索引服务器传回的结果并将其返回给顶层聚集器;
Step 7:顶层聚集器根据返回的结果fbid1,fbid2……fbidn,为“地点”类型垂直聚集器形成新的查询:(and place-kind:273819889375819 (orliked-by:fbid1 liked-by:fbid2 ... liked- by:fbidn)),并将其发送给“地点”垂直聚集器;
Step 8:“地点”垂直聚集器将接受到的查询通过RACK聚集器分发给所有索引服务器;
Step 9:索引服务器在自己维护的索引里搜索结果并将得分较高的地点实体返回给“地点”垂直聚集器;
Step 10:”地点“垂直聚集器接收各个索引服务器的返回结果,合并后提交给顶层聚集器;
Step 11:顶层聚集器对结果进行重新打分并将得分较高结果返回给用户作为搜索结果。
从以上查询的执行流程,可以看出整体架构图中各个构件的具体功能及其流程关系。
搜索结果排序
对于搜索引擎来说,搜索结果排序质量好坏直接关系到用户体验,对于网页搜索来说,最主要的两个排序因素是内容相关性以及通过网页之间的链接关系分析得出的网页重要性排名,除此外还会融合查询词出现位置等很多其它因素来最终人工拟合抑或通过机器学习算法来自动推导出搜索结果排序公式。
GraphSearch采用了简单的机器学习框架来对搜索结果进行排序,即采用对若干影响搜索排名的因子进行线性加权来计算获得最终搜索结果排名,而影响排名的因子包括:搜索用户和搜索结果地理位置的距离远近;搜索用户和搜索结果通过朋友关系推导出的亲密程度;查询串和搜索结果字符串的重叠程度等几十种排序特征。Facebook工程师认为这种简单的机器学习排序框架有利于整个系统的可理解性和可维护性。
除了上述简单机器学习框架外,Graph Search系统非常关注搜索结果的多样性(Diversity)。Unicorn本身提供的Wenk-And 和Srong-Or是保证搜索结果多样性的一种措施,除此外,Unicorn提供了对于同一类查询结果同时采纳多种不同侧重点的打分函数机制,这样每个搜索结果会同时得到多个不同维度的得分,在排序的时候可以考虑采用一定策略来融合不同打分函数的结果,以此来保证搜索结果的多样性。比如对于搜索附近地理位置的查询(Nearby),可以提供三种不同类型的打分函数,一种考虑搜索结果的热门程度,一种考虑搜索用户的社交关系,还有一种考虑距离远近。这样每个搜索结果会附带三个不同的得分,在排序时为了保证结果的多样性,可以按照一定比例将三种高得分结果进行混合输出。
结束语
社交化是当前很多互联网应用的发展趋势,而社交化数据往往比较适合采用实体图来建立数据模型。面对海量的实体图数据,如何构建其上的搜索系统,使得这个搜索系统能够回答各种涉及关系类型的复杂查询,这都是社交化互联网应用必须解决的技术问题。Facebook作为世界最大的社交网站,通过Graph Search为我们提供了一套行之有效的解决方案,本文对这套技术方案进行了技术讲解,期望国内同仁