一、概述
MP4文件封装格式,对应的标准为ISO/IEC 14496-12,
即信息技术 视听对象编码的第12部分:ISO 基本媒体文件格式(Information technology Coding of audio-visual objects Part 12: ISO base media file format)。
ISO/IEC组织指定的标准一般用数字表示,ISO/IEC 14496即MPEG-4标准。
MP4视频文件封装格式是基于QuickTime容器格式定义的,因此参考QuickTime的格式定义对理解MP4文件格式很有帮助。
MP4文件格式是一个十分开放的容器,几乎可以用来描述所有的媒体结构,
MP4文件中的媒体描述与媒体数据是分开的,并且媒体数据的组织也很自由,不一定要按照时间顺序排列,甚至媒体数据可以直接引用其他文件。
同时,MP4也支持流媒体。MP4目前被广泛用于封装h.264视频和AAC音频,是高清视频的代表。
MP4文件中的所有数据都装在box(QuickTime中为atom)中,
也就是说MP4文件由若干个box组成,每个box有类型和长度,可以将box理解为一个数据对象块。
box中可以包含另一个box,这种box称为container box。
box中存放小box,一级嵌套一级来存放媒体信息。box的基本结构是:
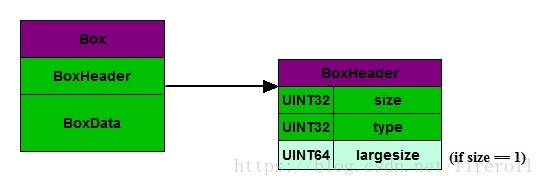
其中,size指明了整个box所占用的大小,包括header部分。
如果box很大(例如存放具体视频数据的mdat box),超过了uint32的最大数值,size就被设置为1,并用接下来的8位uint64来存放大小。
一个MP4文件首先会有且只有一个“ftyp”类型的box,作为MP4格式的标志并包含关于文件的一些信息;
之后会有且只有一个“moov”类型的box(Movie Box),它是一种container box,子box包含了媒体的metadata信息;
MP4文件的媒体数据包含在“mdat”类型的box(Midia Data Box)中,该类型的box也是container box,可以有多个,也可以没有(当媒体数据全部引用其他文件时),
媒体数据的结构由metadata进行描述。
下面是一些概念:
> track : 表示一些sample的集合,对于媒体数据来说,track表示一个视频或音频序列。
一个MP4文件可以由多个tracks组成。
有很多种类的track,其中有三个最重要:
video track包含了视频sample;
audio track包含了audiosample;
hint track
> hint track 这个特殊的track并不包含媒体数据,而是包含了一些将其他数据track打包成流媒体的指示信息。
> sample
对于非hint track来说,
video sample即为一帧视频,或一组连续视频帧,
audio sample即为一段连续的压缩音频,它们统称sample。
对于hint track,sample定义一个或多个流媒体包的格式。
它描述了一个流媒体服务器如何把文件中的媒体数据组成符合流媒体协议的数据包。
如果文件只是本地播放,可以忽略hint track,他们只与流媒体有关系。
sample table 指明sampe时序和物理布局的表。
chunk 一个track的几个sample组成的单元。
NOTE1:
一帧音频可以分解成多个音频sample,所以音频一般用sample作为单位,而不用帧。
NOTE2:
每个track会有一个或者多个sample descriptions。
track里面的每个sample通过引用关联到一个sample description。
这个sample descriptions定义了怎样解码这个sample,如使用什么解压缩
算法。
二、 结构
2.1 整体结构
首先需要说明的是,box中的字节序为网络字节序,也就是大端字节序(Big-Endian),
简单的说,就是一个32位的4字节整数存储方式为高位字节在内存的低端。
Box由header和body组成,其中,
header统一指明box的大小和类型,body根据类型有不同的意义和格式。
标准的box开头的4个字节(32位)为box size,该大小包括box header和box body整个box的大小,这样我们就可以在文件中定位各个box。
如果size为1,则表示这个box的大小为large size,真正的size值要在largesize域上得到。
(实际上只有“mdat”类型的box才有可能用到large size。)
如果size为0,表示该box为文件的最后一个box,文件结尾即为该box结尾。
(同样只存在于“mdat”类型的box中。)
size后面紧跟的32位为box type,一般是4个字符,如“ftyp”、“moov”等,这些box type都是已经预定义好的,分别表示固定的意义。
如果是“uuid”,表示该box为用户扩展类型。如果box type是未定义的,应该将其忽略。
下面这张图是常见的box的树结构图,可以用来大致了解MP4文件的构造。
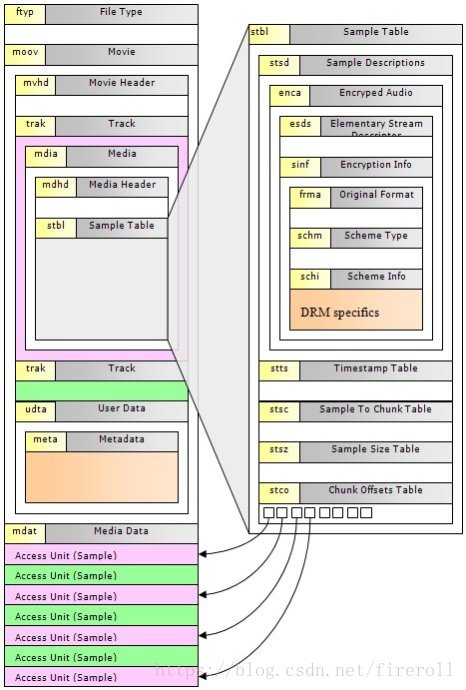
一个mp4文件有可能包含非常多的box,在很大程度上增加了解析的复杂性,
这个网页上
http://mp4ra.org/atoms.html记录了一些当前注册过的box类型。
看到这么多box,如果要全部支持,一个个解析,怕是头都要爆了。
还好,大部分mp4文件没有那么多的box类型,下图就是一个简化了的,常见的mp4文件结构:
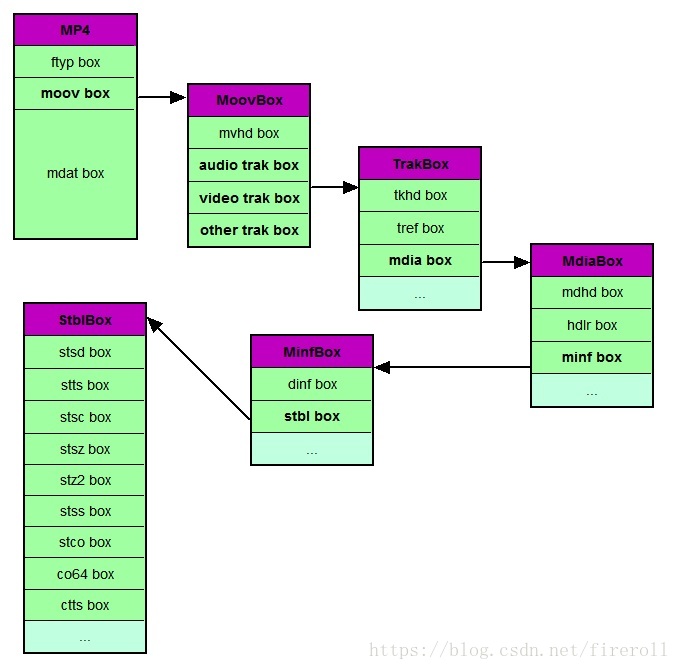
一般来说,解析媒体文件,最关心的部分是视频文件的宽高、时长、码率、编码格式、帧列表、关键帧列表,以及所对应的时戳和在文件中的位置,这些信息,
在mp4中,是以特定的算法分开存放在stbl box下属的几个box中的,需要解析stbl下面所有的box,来还原媒体信息。
下表是对于以上几个重要的box存放信息的说明:
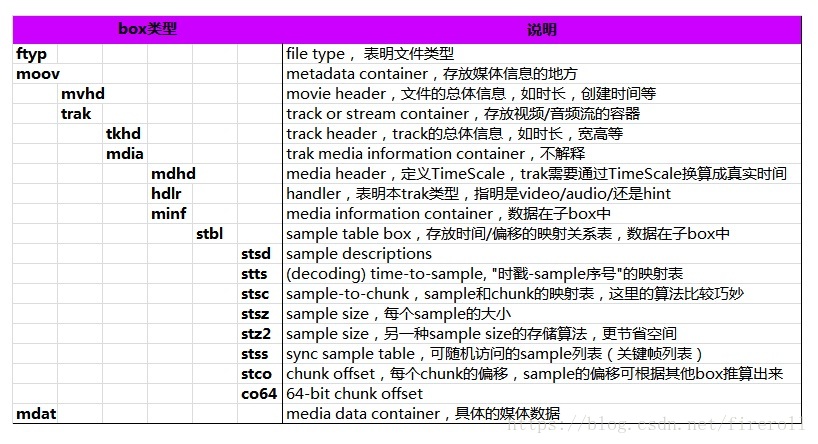
最重要的四个box是 ‘ftyp’, 'moov', 'mdat', 'mdia'。
实例如下:
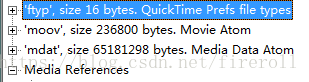
2.2 ftyp(File Type Box)
该box有且只有1个,并且只能被包含在文件层,而不能被其他box包含。
该box应该被放在文件的最开始,指示该MP4文件应用的相关信息。
“ftyp” body依次包括:
1个32位的major brand(4个字节),
1个32位的minor version(整数),
1个以32位(4个字节)为单位元素的数组compatible brands。
这些都是用来指示文件应用级别的信息。该box的字节实例如下:

size = 0x 00 00 00 18
ftype = 0x 66 74 79 70
data = 为蓝色部分
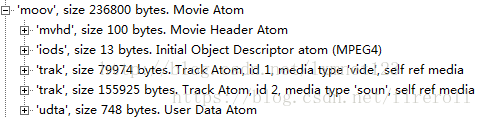
2.3 moov (Movie Box)
该box包含了文件媒体的metadata信息,
“moov”是一个container box,具体内容信息由子box诠释。
同File Type Box一样,该box有且只有一个,且只被包含在文件层。
一般情况下,“moov”会紧随“ftyp”出现。
一般情况下(限于篇幅,本文只讲解常见的MP4文件结构),
“moov”中会包含1个“mvhd”和若干个“trak”。
其中“mvhd”为header box,一般作为“moov”的第一个子box出现(对于其他container box来说,header box都应作为首个子box出现)。
“trak”包含了一个track的相关信息,是一个container box。
下图为部分“moov”的字节实例:
没有压缩的movie header box必须至少包含movie header box 和referencemovie box中的一种。
也可以包含其他的box,例如
一个clipping atom ('clip'),
一个或几个track atoms ('trak'),
一个colortable atom ('ctab'),
和一个userdata atom ('udta')。
其中movie header box定义了整部电影的time scale,duration信息以及display characteristics。track box定义了电影中一个track的信息。
Track就是电影中可以独立操作的媒体单位,例如一个声道就是一个track。
2.3.1
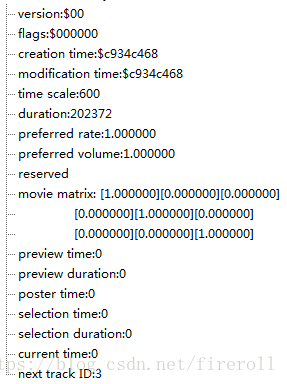
Movie Header Box(mvhd)
“mvhd”结构如下表。
|
字段
|
字节数
|
意义
|
|
box size
|
4
|
box大小
|
|
box type
|
4
|
box类型
|
|
version
|
1
|
box版本,0或1,一般为0。(以下字节数均按version=0)
|
|
flags
|
3
|
|
|
creation time
|
4
|
创建时间(相对于UTC时间1904-01-01零点的秒数)
|
|
modification time
|
4
|
修改时间
|
|
time scale
|
4
|
文件媒体在1秒时间内的刻度值,可以理解为1秒长度的时间单元数
|
|
duration
|
4
|
该track的时间长度,用duration和time scale值可以计算track时长,
track时长 = duration / time
比如, audio track:
time scale = 8000, duration = 560128,时长为70.016,
video track:
time scale = 600, duration = 42000,时长为70
|
|
rate
|
4
|
推荐播放速率,高16位和低16位分别为小数点整数部分和小数部分,即[16.16] 格式,该值为1.0(0x00010000)表示正常前向播放
|
|
volume
|
2
|
与rate类似,[8.8] 格式,1.0(0x0100)表示最大音量
|
|
reserved
|
10
|
保留位
|
|
matrix
|
36
|
视频变换矩阵;
该矩阵定义了此文件中两个坐标空间的映射关系;
|
|
preview time
|
4
|
预览时间;
开始预览此文件的时间
|
|
preview duration
|
4
|
以time scale为单位,预览的duration
|
|
poster time
|
4
|
The time value of the time of the movie poster
|
|
selection time
|
4
|
the time value for the start time of the current selection
|
|
selection duration
|
4
|
the duration of the current selection in movie time scale units
|
|
current time
|
4
|
当前时间
|
|
next track id
|
4
|
下一个track使用的id号
|
mvhd 实际数据示例:

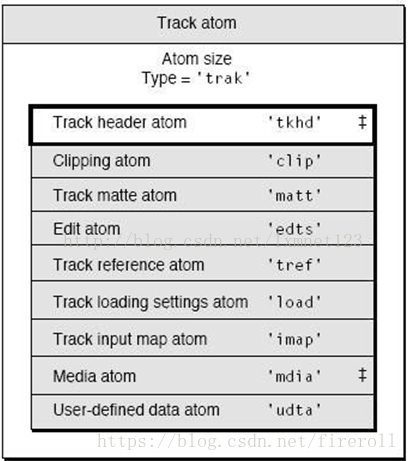
2.3.2 Track Box(trak)
“trak”也是一个container box,其子box包含了该track的媒体数据引用和描述(hint track除外)。
一个MP4文件中的媒体可以包含多个track,且至少有一个track,这些track之间彼此独立,有自己的时间和空间信息。
“trak”必须包含一个“tkhd”和一个“mdia”,其中
“tkhd”为track header box,
“mdia”为media box,该box是一个包含一些track媒体数据信息box的container box。
此外还有很多可选的box。如,
track clipping atom ('clip'),
track matte atom ('matt'),
edit atom ('edts'),
track reference atom ('tref'),
track load settings atom ('load'),
a track input map atom ('imap'),
user data atom ('udta')
都是可选的。
Track的类型定义如下
2.3.2.1
Track Header Box(tkhd)
每个trak都包含了一个track header box.
track header box定义了一个track的特性,例如时间,空间和音量信息,它的类型是('tkhd').
tkhd的结构如下表:
|
字段
|
字节数
|
意义
|
|
box size
|
4
|
box大小
|
|
box type
|
4
|
box类型
|
|
version
|
1
|
box版本,0或1,一般为0。(以下字节数均按version=0)
|
|
flags
|
3
|
按位或操作结果值,预定义如下:
0x000001 track_enabled,否则该track不被播放;
0x000002 track_in_movie,表示该track在播放中被引用;
0x000004 track_in_preview,表示该track在预览时被引用。
一般该值为7,如果一个媒体所有track均未设置track_in_movie和track_in_preview,将被理解为所有track均设置了这两项;对于hint track,该值为0
|
|
creation time
|
4
|
创建时间(相对于UTC时间1904-01-01零点的秒数)
|
|
modification time
|
4
|
修改时间
|
|
track id
|
4
|
id号,不能重复且不能为0
|
|
reserved
|
4
|
保留位
|
|
duration
|
4
|
track的时间长度
|
|
reserved
|
8
|
保留位
|
|
layer
|
2
|
视频层,默认为0,值小的在上层
|
|
alternate group
|
2
|
track分组信息,默认为0表示该track未与其他track有群组关系
|
|
volume
|
2
|
[8.8] 格式,如果为音频track,1.0(0x0100)表示最大音量;否则为0
|
|
reserved
|
2
|
保留位
|
|
matrix
|
36
|
视频变换矩阵
|
|
width
|
4
|
宽
|
|
height
|
4
|
高,均为 [16.16] 格式值,与sample描述中的实际画面大小比值,用于播放时的展示宽高
|
实际数据示例如下:


( video) 左边为video 解析出来的字段值
可以获取图像的宽、 高等信息

(audio) 右边为audio解析出来的字段值
2.3.2.2 Media Box(mdia)
“mdia”也是个container box,其子box的结构和种类还是比较复杂的。
先来看一个“mdia”的实例结构树图。
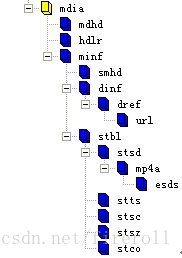
总体来说,“mdia”定义了track媒体类型以及sample数据(如音频或视频),
描述sample信息,包括有media handler component,media timescale and track duration, media-and-track-specific 等信息。
一般“mdia”包含:
一个“mdhd”,
一个“hdlr”,
一个“minf”,
一个“udta”
其中,
“mdhd”为media header box,
“hdlr”为handler reference box,
“minf”为media information box,
"udta"为 user data box。
下面依次看一下这几个box的结构
2.3.2.2.1 Media Header Box(mdhd)
“mdhd”结构如下表。 它定义了媒体的特性,例如time scale和duration。它的类型是'mdhd'.
|
字段
|
字节数
|
意义
|
|
box size
|
4
|
box大小
|
|
box type
|
4
|
box类型
|
|
version
|
1
|
box版本,0或1,一般为0。(以下字节数均按version=0)
|
|
flags
|
3
|
|
|
creation time
|
4
|
创建时间(相对于UTC时间1904-01-01零点的秒数)
|
|
modification time
|
4
|
修改时间
|
|
time scale
|
4
|
同前表
|
|
duration
|
4
|
track的时间长度
|
|
language
|
2
|
媒体语言码。最高位为0,后面15位为3个字符(见ISO 639-2/T标准中定义)
|
|
pre-defined
|
2
|
|
实际数据如下:上面的是视频track,下面的是音频track


video 的播放时长 = duration / time scale
audio 的播放时长计算方式相同。
2.3.2.2.2 Handler Reference Box(hdlr)
“hdlr”解释了媒体的播放过程信息,该box也可以被包含在meta box(meta)中。
例如,一个视频handler处理一个video track.
“hdlr”结构如下表:
|
字段
|
字节数
|
意义
|
|
box size
|
4
|
box大小
|
|
box type
|
4
|
box类型
|
|
version
|
1
|
box版本,0或1,一般为0。(以下字节数均按version=0)
|
|
flags
|
3
|
|
|
pre-defined
|
4
|
|
|
handler type
|
4
|
在media box中,该值为4个字符:
“vide”— video track
“soun”— audio track
“hint”— hint track
|
|
reserved
|
12
|
|
|
name
|
不定
|
track type name,以‘\0’结尾的字符串
|
实际数据示例如下:




可知 音视频 采用的压缩方法
2.3.2.2.3、Media Information Box(minf)
“minf”存储了解释track媒体数据的handler-specific信息,media handler用这些信息将媒体时间映射到媒体数据并进行处理。
“minf”中的信息格式和内容与媒体类型以及解释媒体数据的media handler密切相关,
其他media handler不知道如何解释这些信息。“minf”是一个container box,其实际内容由子box说明。
一般情况下,“minf”包含一个header box,一个“dinf”和一个“stbl”,其中,
header box 根据track type(即media handler type) 分为“vmhd”、“smhd”、“hmhd”和“nmhd”,
“dinf”为data information box,
“stbl”为sample table box。
实际数据如下:

Media Information Header Box(vmhd、smhd、hmhd、nmhd)
1) Video Media Header Box(vmhd)
Video media information atoms是视频媒体的第一层box,包含其他的定义视频媒体数据的特性。
|
字段
|
长度(字节)
|
描述
|
|
尺寸
|
4
|
这个atom的字节数
|
|
类型
|
4
|
vmhd
|
|
版本
|
1
|
这个box的版本, 0或1 ,一般为0
|
|
标志
|
3
|
这里总是0x000001
|
|
图形模式
|
4
|
视频合成模式,为0时拷贝原始图像,否则与opcolor进行合成
|
|
Opcolor
|
6
|
{red,green,blue}
|
实际数据:

2) Sound Media Header Box(smhd)
Sound media information atoms是音频媒体的第一层atoms,包含其他的定义音频媒体数据的特性。
|
字段
|
长度(字节)
|
描述
|
|
尺寸
|
4
|
这个box的字节数
|
|
类型
|
4
|
smhd
|
|
版本
|
1
|
这个box的版本
|
|
标志
|
3
|
这里为0
|
|
均衡
|
2
|
立体声平衡,[8.8] 格式值,一般为0,
-1.0表示全部左声道,1.0表示全部右声道
|
|
保留
|
2
|
保留字段,缺省为0
|
实际数据如下:

3) Hint Media Header Box(hmhd)
略
4) Null Media Header Box(nmhd)
非视音频媒体使用该box,略。
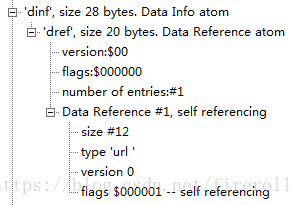
Data Information Box(dinf)
“dinf”解释如何定位媒体信息,是一个container box。
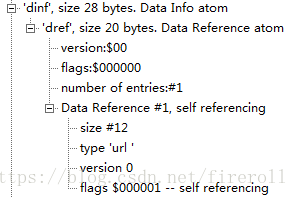
“dinf”一般包含一个“dref”,即data reference box;
“dref”下会包含若干个“url”或“urn”,这些box组成一个表,用来定位track数据。
简单的说,track可以被分成若干段,每一段都可以根据“url”或“urn”指向的地址来获取数据,
sample描述中会用这些片段的序号将这些片段组成一个完整的track。
一般情况下,当数据被完全包含在文件中时,“url”或“urn”中的定位字符串是空的。
“dref”的字节结构如下表。
|
字段
|
字节数
|
意义
|
|
box size
|
4
|
box大小
|
|
box type
|
4
|
box类型
|
|
version
|
1
|
box版本,0或1,一般为0。(以下字节数均按version=0)
|
|
flags
|
3
|
|
|
entry count
|
4
|
“url”或“urn”表的元素个数
|
|
“url”或“urn”列表
|
不定
|
|
“url”或“urn”都是box,“url”的内容为字符串(location string),“urn”的内容为一对字符串(name string and location string)。当“url”或“urn”的box flag为1时,字符串均为空。
Sample Table Box(stbl)
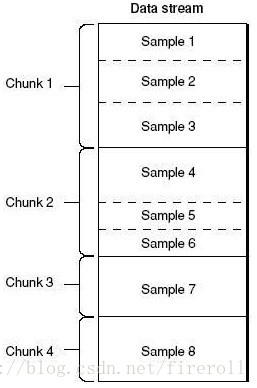
“stbl”几乎是普通的MP4文件中最复杂的一个box了,首先需要回忆一下sample的概念。
sample是媒体数据存储的单位,存储在media的chunk中,chunk和sample的长度均可互不相同,
例如如下图,
chunk 2和3不同的长度,
chunk 2内的sample5和6的长度一样,
但是sample 4和5,6的长度不同。
“stbl”包含了关于track中sample所有时间和位置的信息,以及sample的编解码等信息。
利用这个表,可以解释sample的时序、类型、大小以及在各自存储容器中的位置。
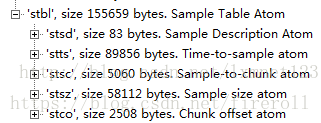
“stbl”是一个container box,其子box包括:
sample description box(stsd)、
time to sample box(stts)、
sample size box(stsz或stz2)、
sample to chunk box(stsc)、
chunk offset box(stco或co64)、
composition time to sample box(ctts)、
sync sample box(stss)等。
“stsd”必不可少,且至少包含一个条目,
该box包含了data reference box进行sample数据检索的信息。
没有“stsd”就无法计算media sample的存储位置。
“stsd”包含了编码的信息,其存储的信息随媒体类型不同而不同
。
1) Sample Description Box(stsd)
视频的编码类型、宽高、长度,音频的声道、采样等信息都会出现在这个box中。
sample description atom的类型是'stsd',包含了一个sample description表。
根据不同的编码方案和存储数据的文件数目,
box header和version字段后会有一个entry count字段,根据entry的个数,每个entry会有type信息,如“vide”、“sund”等,根据type不同sample description会提供不同的信息,
每个media可以有一个到多个sample description。sample-to-chunk box通过这个索引表,找到合适medai中每个sample的description。
例如
对于video track,会有“VisualSampleEntry”类型信息,
对于audio track会有“AudioSampleEntry”类型信息。
|
字段
|
长度(字节)
|
描述
|
|
尺寸
|
4
|
这个atom的字节数
|
|
类型
|
4
|
stsd
|
|
版本
|
1
|
这个atom的版本
|
|
标志
|
3
|
这里为0
|
|
条目数目
|
4
|
sample descriptions的数目
|
|
Sample description
|
|
不同的媒体类型有不同的sample description,但是每个sample description的前四个字段是相同的,包含以下的数据成员
|
|
尺寸
|
4
|
这个sample description的字节数
|
|
数据格式
|
4
|
存储数据的格式。
|
|
保留
|
6
|
|
|
数据引用索引
|
2
|
利用这个索引可以检索与当前sample description关联的数据。数据引用存储在data reference atoms。
|


可以看出这个sample只有一个description,对应得的数据格式是'mp4a',14496-12定义了这种结构,mp4解码器会识别此description。
2)Time To Sample Box(stts)
“stts”存储了sample的duration,描述了sample时序的映射方法,我们通过它可以找到任何时间的sample。
“stts”可以包含一个压缩的表来映射时间和sample序号,用其他的表来提供每个sample的长度和指针。
表中每个条目提供了在同一个时间偏移量里面连续的sample序号,以及samples的偏移量。
递增这些偏移量,就可以建立一个完整的time to sample表。
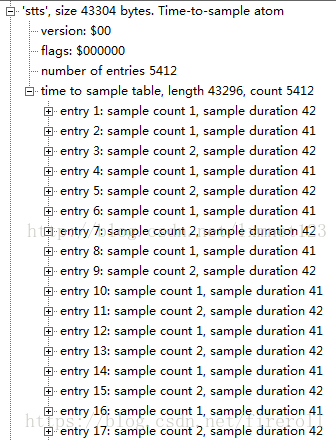
通过这个表,可以得知,任意时间所对应的第几个sample。
由 mdhd 知 timescale = 1000。 如计算0.2s所对应的sample为第几个时。
对应的duration = timescale * 0.2 s = 200
entry 4 所对应的sample 第 5 个sample
3) Sample To Chunk Box(stsc)
用chunk组织sample可以方便优化数据获取,一个thunk包含一个或多个sample。
“stsc”中用一个表描述了sample与chunk的映射关系,查看这张表就可以找到包含指定sample的thunk,从而找到这个sample。
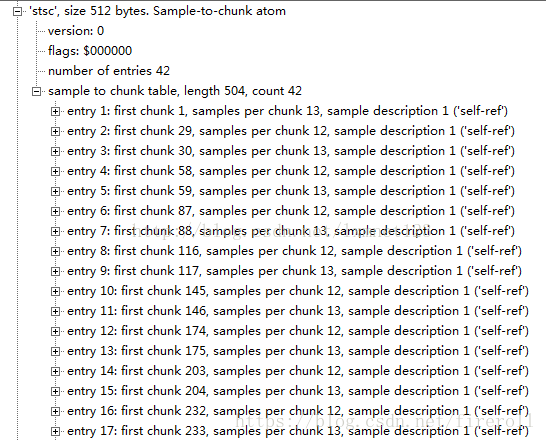
当添加samples到media时,用chunks组织这些sample,这样可以方便优化数据获取。
一个trunk包含一个或多个sample,chunk的长度可以不同,chunk内的sample的长度也可以不同。sample-to-chunk box存储sample与chunk的映射关系。
Sample-to-chunk box的类型是'stsc'。
它也有一个表来映射sample和trunk之间的关系,
查看这张表,就可以找到包含指定sample的trunk,从而找到这个sample。
第 500个sample 500 = 28*13 + 12 + 13*9 + 7
所以相当于在chunk = 39 的 第7个sample中,
这样 我们可以根据 stco 这个表找到 在chunk = 39位置所对应的偏移地址。
再根据 stsz 中找到第 494 至 496 中每个sample所占的大小。
这样我们就可以求得 第500个sample的偏移地址,这样可以 seek 快进 快退。
如果要快进到任意时间,先根据 stts 表获取是第几个sample。在根据上面步骤就可快进。
4)Sample Size Box(stsz)
“stsz” 定义了每个sample的大小,包含了媒体中全部sample的数目和一张给出每个sample大小的表。这个box相对来说体积是比较大的。
sample size atoms定义了每个sample的大小,它的类型是'stsz',
包含了媒体中全部sample的数目和一张给出每个sample大小的表。
这样,媒体数据自身就可以没有边框的限制。
|
字段
|
长度(字节)
|
描述
|
|
尺寸
|
4
|
这个atom的字节数
|
|
类型
|
4
|
stsz
|
|
版本
|
1
|
这个atom的版本
|
|
标志
|
3
|
这里为0
|
|
Sample size
|
4
|
全部sample的数目。如果所有的sample有相同的长度,这个字段就是这个值。否则,这个字段的值就是0。那些长度存在sample size表中
|
|
条目数目
|
4
|
sample size的数目
|
|
sample size
|
|
sample size表的结构。这个表根据sample number索引,第一项就是第一个sample,第二项就是第二个sample
|
|
大小
|
4
|
每个sample的大小
|
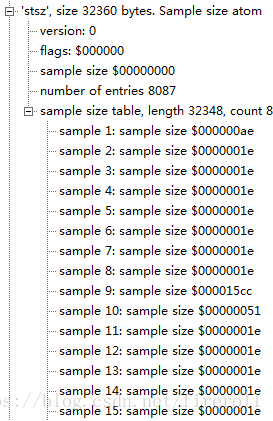
可以看到这个vedio track的sample的长度都不一样。
5) Chunk Offset Box(stco)
“stco”定义了每个thunk在媒体流中的位置。
位置有两种可能,32位的和64位的,后者对非常大的电影很有用。
在一个表中只会有一种可能,这个位置是在整个文件中的绝对位置,而不是在任何box中的,
这样做就可以直接在文件中找到媒体数据,而不用解释box。
需要注意的是一旦前面的box有了任何改变,这张表都要重新建立,因为位置信息已经改变了。
|
字段
|
长度(字节)
|
描述
|
|
尺寸
|
4
|
这个atom的字节数
|
|
类型
|
4
|
stco
|
|
版本
|
1
|
这个atom的版本
|
|
标志
|
3
|
这里为0
|
|
条目数目
|
4
|
chunk offset的数目
|
|
chunk offset
|
|
字节偏移量从文件开始到当前chunk。这个表根据chunk number索引,第一项就是第一个trunk,第二项就是第二个trunk
|
|
大小
|
4
|
每个sample的大小
|
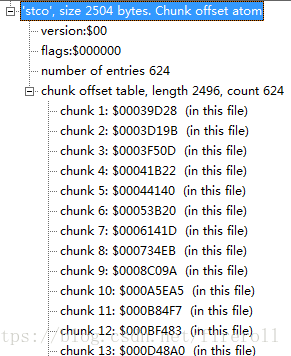
6) Sync Sample Box(stss)
“stss”确定media中的关键帧。
对于压缩媒体数据,关键帧是一系列压缩序列的开始帧,其解压缩时不依赖以前的帧,而后续帧的解压缩将依赖于这个关键帧。
“stss”可以非常紧凑的标记媒体内的随机存取点,它包含一个sample序号表,
表内的每一项严格按照sample的序号排列,说明了媒体中的哪一个sample是关键帧。
如果此表不存在,说明每一个sample都是一个关键帧,是一个随机存取点。
2.3.3 Free Space Box(free或skip)
“free”中的内容是无关紧要的,可以被忽略。该box被删除后,不会对播放产生任何影响。
2.3.4 Meida Data Box(mdat)
该box包含于文件层,可以有多个,也可以没有(当媒体数据全部为外部文件引用时),
用来存储媒体数据,数据直接跟在box type字段后面,
具体数据结构的意义需要参考metadata(主要在moov box中的sample table中描述)。
三、计算
3.1 计算电影时长
方法1
从mvhd - movie header atom中找到time scale和duration,
duration除以time scale即是整部电影的长度。
time scale相当于定义了标准的1秒在这部电影里面的刻度是多少。
例如
audio track的time scale = 8000, duration = 560128,所以总长度是70.016,
video track的timescale = 600, duration = 42000,所以总长度是70
方法2
首先,计算出共有多少个帧,也就是sample(从sample size atoms中得到),
然后,整部电影的duration = 每个帧的duration之和(从Time-to-sample atoms中得出)
例如,
audio track共有547个sample,每个sample的长度是1024,则总duration是560128,
电影长度是70.016;
video track共有1050个sample,每个sample的长度是40,则总duration是42000,
电影长度是70
3.2 计算图像的宽 高
从tkhd – track header atom中找到宽度和高度即是。
3.3 电影声音采样率
从tkhd – track header atom中找出audio track的timescale即是声音的采样频率。
3.4 计算视频帧率
首先,计算出整部电影的duration,和帧的数目,
然后,帧率 = 整部电影的duration / 帧的数目
3.5 计算电影的比特率
整部电影的尺寸除以长度,即是比特率,此电影的比特率为846623/70 = 12094 bps
3.6 查找sample
当播放一部电影或者一个track的时候,对应的media handler必须能够正确的解析数据流,对一定的时间获取对应的媒体数据。
如果是视频媒体,mediahandler可能会解析多个atom,才能找到给定时间的sample的大小和位置。具体步骤如下:
1.确定时间,相对于媒体时间坐标系统
2.检查time-to-sample atom来确定给定时间的sample序号。
3.检查sample-to-chunk atom来发现对应该sample的chunk。
4.从chunk offset atom中提取该trunk的偏移量。
5.利用sample size atom找到sample在trunk内的偏移量和sample的大小。
例如,如果要找第1秒的视频数据,过程如下:
1. 第1秒的视频数据相对于此电影的时间为600
2. 检查time-to-sampleatom,得出每个sample的duration是40,从而得出需要寻找第600/40 = 15 + 1 = 16个sample
3. 检查sample-to-chunkatom,得到该sample属于第5个chunk的第一个sample,该chunk共有4个sample
4. 检查chunkoffset atom找到第5个trunk的偏移量是20472
5. 由于第16个sample是第5个trunk的第一个sample,所以不用检查sample size atom,trunk的偏移量即是该sample的偏移量20472。如果是这个trunk的第二个sample,则从sample size atom中找到该trunk的前一个sample的大小,然后加上偏移量即可得到实际位置。
6. 得到位置后,即可取出相应数据进行解码,播放
3.7 查找关键帧
查找过程与查找sample的过程非常类似,只是需要利用sync sample atom来确定key frame的sample序号
- 确定给定时间的sample序号
- 检查sync sample atom来发现这个sample序号之后的key frame
- 检查sample-to-chunk atom来发现对应该sample的chunk
- 从chunk offset atom中提取该trunk的偏移量
- 利用sample size atom找到sample在trunk内的偏移量和sample的大小