Link of the Paper: https://arxiv.org/abs/1806.06422
Innovations:
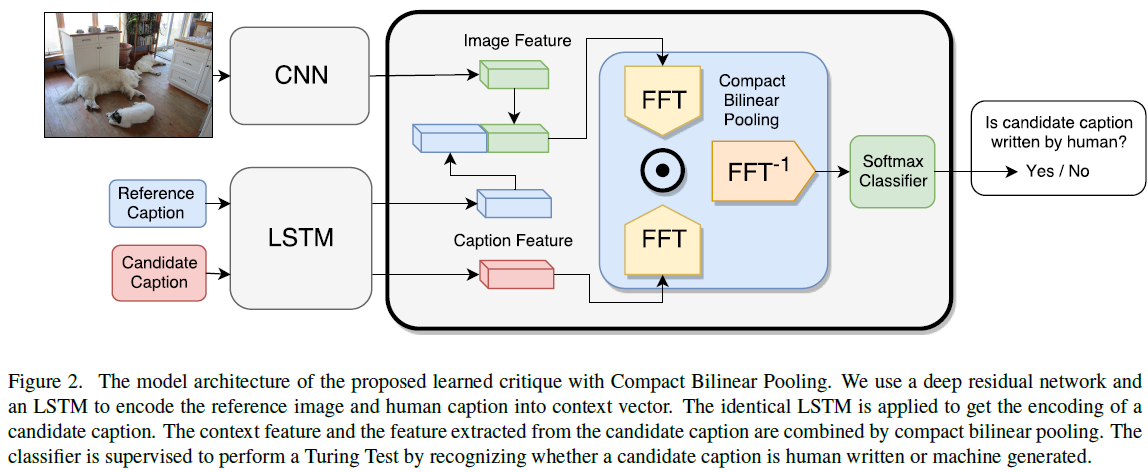
- The authors propose a novel learning based discriminative evaluation metric that is directly trained to distinguish between human and machine-generated captions. They train an automatic critique to distinguish generated captions from human-written ones, and then score candidate captions by how successful they are in fooling the critique. Formally, given a critique parametrized by Θ, a reference image i, and a generated caption c, the score is defined as the probability for the caption of being human-written, as assigned by the critique: scoreΘ(c, i) = P(c is human written | i, Θ). More generally, the reference image represents the context in which the generated caption is evaluated. To provide further information about the relevance and salience of the image content, a reference caption can additionally be supplied to the context. Let C(i) denotes the context of image i, then reference caption c could be included as part of context, i.e. c∈C(i). The score with context becomes scoreΘ(c, i) = P(c is human written | C(i), Θ).
- To systematically create pathological sentences, the authors define several transformations to generate unnatural sentences that might get high scores in an evaluation metric. Their proposed data augmentation scheme uses these transformations to generate large number of negative examples. Formally, a transformation Τ takes an image-caption dataset and generates a new one: Τ({(c, i) ∈ D}; γ) = {(c1', i1'), ..., (cn', in')}, where i, ii' are images, c, ci' are captions, D is a list of caption-image tuples representing the original dataset, and γ is a hyper-parameter that controls the strength of the transformation. Specifically, authors define following three transformations to generate pathological image-captions pairs:
- Random Captions ( RC ): To ensure the metric pays attention to the image content, they randomly sample human written captions from other images in the training set: TRC(D; γ) = {(c', i) | (c, i), (c', i') ∈ D, i'∈Nγ(i)}, where Nγ(i) represents the set of images that are top γ percent nearest neighbors to image i.
- Word Permutation ( WP ): To make sure that their metric pays attention to sentence structure, authors randomly permute at least 2 words in the reference caption: TWP(D; γ) = {(c', i) | (c, i) ∈ D, c' ∈ Pγ(c) \ {c}}, where Pγ(c) represents all sentences generated by permuting γ percent of words in caption c.
- Random Word ( RW ): To explore rare words authors replace from 2 to all words of the reference caption with random words from the vocabulary: TRW(D; γ) = {(c', i) | (c, i) ∈ D, c' ∈ Wγ(c) \ {c}}, where Wγ(c) represents all sentences generated by randomly replacing γ percent words from caption c.

- The authors propose a systematic approach to measure the robustness of an evaluation metric to a given pathological transformation.
General Points:
- Commonly used evaluation metrics of Image Captioning face two challenges. Firstly, many metrics fail to correlate well with human judgments. Metrics based on measuring word overlap between candidate and reference captions find it difficult to capture semantic meaning of a sentence, therefore often lead to bad correlation with human judgments. Secondly, each evaluation metric has its well-known blind spot, and rule-based metrics are often inflexible to be responsive to new pathological cases.
- Compact Bilinear Pooling ( CBP ) has been demonstrated in Multimodal compact bilinear pooling for visual question answering and visual grounding to be very effective in combining heterogeneous information of image and text.