如果你是一名谨慎的项目开发者,就必定会用到版本管理软件,现有市场上成熟的版本管理软件有cvs,svn,clearcase和更加灵活敏捷的git。相比传统的重量级中央版本管理软件svn,clearcase等,git更像是一个轻盈的分布式版本管理系统,它不需要架设中央服务器来时时同步版本信息,个人只需要在自己的电脑上创建一个git版本管理库,就拥有一个完整项目开发历史的分支集合,最大程度支持自由软件开发者的离线工作,同时git又提供了方便的同步接口协同其他人的并行开发。
在实际的项目开发过程中,我们采用了双系统来进行版本管理,svn管理项目正式版本和预发布版本,而git管理子功能模块开发和个人在服务器和客户端之间的协同开发,在保证功能稳定之后再将git上的内容merge到svn主干上。
这篇文章将主要结合真实的使用环境介绍git的各种基本操作,多人如何协同开发客户端和服务端大功能模块,避免频繁提交svn来进行版本管理。
- git基本操作
git安装
debian系统可以用apt-get install git直接安装
windows系统中可以到http://code.google.com/p/msysgit/下载git for windows的版本,通过git的命令行进行操作,不建议使用tortoisegit等图形化工具。
git 配置
使用git的第一件事就是设置你的名字和email,这些就是你在提交commit时的签名。
$ git config --global user.name "usrname"
$ git config --global user.email " [email protected]"
执行了上面的命令后,会在你的主目录(home directory)建立一个叫 ~/.gitconfig 的文件。 内容如以下格式:
[user]
name = usrname
email = usrname @gmail.com
这些属性都是全局设置,会影响该用户建立的每个项目。如果你想使项目里的属性与前面的全局设置有区别(例如把私人邮箱地址改为工作邮箱);你可以在项目中使用git config 命令不带 --global 选项来设置. 这会在你项目目录下的 .git/config 文件增加一节[user]内容(如上所示)。
设置中文字符集为gbk
$ git config --global i18n.commitencoding gbk
$ git config --global i18n.logoutputencoding gbk
初始化一个新的仓库
首先创建一个目录,在这个目录下进行版本管理
$ mkdir hellogit
在这个目录下创建空git版本库
$git init
执行完这个命令之后,会在这个目录下面产生一个.git目录,所有的版本信息会保存在这个目录之下。.git目录下的文件显示如下:

其中branches目录下面保存着所有已经建立的branch信息;
config描述了这个版本库的所有属性配置;
HEAD描述了当前的版本库指向了哪个branch;
info中包含exclude文件描述了整个版本库中有哪些文件不需要版本控制;
refs中保存了开发过程中所打的tag和各个tag相关联的版本信息;
objects中保存了各个版本信息,并且以各个版本的hash值为文件名。
配置例外(ignore)
项目中经常会生成一些Git系统不需要追踪(track)的文件。典型的是在编译生成过程中产生的文件或是编程器生成的临时备份文件。当然,你不追踪这些文件,可以平时不用"git add"去把它们加到索引中。但是这样会很快变成一件烦人的事,你发现项目中到处有未追踪(untracked)的文件; 这样也使"git add ." 和"git commit -a" 变得实际上没有用处,同时"git status"命令的输出也会有它们的信息。
你可以在你的顶层工作目录中添加一个叫".gitignore"的文件,来告诉Git系统要忽略掉哪些文件,下面是文件内容的示例:
# 以'#' 开始的行,被视为注释.
# 忽略掉所有文件名是 foo.txt 的文件.
foo.txt
# 忽略所有生成的 html 文件,
*.html
# foo.html是手工维护的,所以例外.
!foo.html
# 忽略所有.o 和 .a文件.
*.[oa]
# 忽略svn目录
.svn/
你可以把".gitignore" 这个文件放到工作树(working tree)里的其它目录中,这就会在它和它的子目录起忽略(ignore) 指定文件的作用。. gitignore文件同样可以像其它文件一样加到项目仓库里( 直接用git add .gitignore和git commit等命令), 这样项目里的其它开发者也能共享同一套忽略文件规则。
如果你想忽略规则只对特定的仓库起作用,你可以把这些忽略规则写到你的仓库下 .git/info/exclude文件中,或是写在Git配置变量core.excludesfile中指定的文件里。有些Git命令也可在命令行参数中指定忽略规则,你可以在这里:gitignore查看详细的用法。
Clone一个仓库
我们也可以在已知一个项目版本库的地址(Git URL)情况下,拷贝这个版本库到本地开发环境。Git能够支持很多链接协议的拷贝, Git URL可以是ssh://, http(s)://, git://,或是包含有.git目录的本地路径。在一个新的目录下需要拷贝刚才版本库,可以使用:
$git clone ~/hellogit
对于远程的版本库,可以通过不只一种协议来访问,例如,Git本身的源代码你既可以用 git:// 协议来访问:
$ git clone git://git.kernel.org/pub/scm/git/git.git
也可以通过http 协议来访问:
$ git clone http://www.kernel.org/pub/scm/git/git.git
git://协议较为快速和有效,但是有时必须使用http协议或者ssh协议,以ssh协议为例,你首先需要在当前用户目录下的.ssh文件夹中放有链接对方ssh服务器的公钥和私钥,然后通过命令
$ git clone ssh://usrname@IP:PORT/home/szh/hellogit
在实际应用中,为了方便可以添加以下命令
$ git remote add alias_hellogit_path ssh://name@ip:port/<gitpath>
上面的命令就会增加ssh地址别名为alias_hellogit_path的远程服务器,以后提交代码的时候只需要使用 alias_hellogit_path别名即可,此时在.git/config会有如下内容出现:
[remote " alias_hellogit_path"]
ssh://name@ip:port/<gitpath>
fetch = +refs/heads/*:refs/remotes/ alias_hellogit_path /*
经过alias设置,可以直接通过一下命令进行clone
$ git clone alias_hellogit_path
追踪更新
建立了版本仓库之后,就可以跟踪这个仓库下面的所有改动。首先创建三个文件file1, file2, file3,对其中文件进行修改。
如果需要将更新的内容添进行跟踪,使用如下指令将它们更新的内容添加到索引中.
$ git add file1 file2 file3
你现在为commit做好了准备,你可以使用git diff命令再加上 --cached 参数 ,看看哪些文件将被提交(commit)。
$ git diff --cached
(如果没有--cached参数,git diff 会显示当前你所有已做的但没有加入到索引里的修改.) 你也可以用git status命令来获得当前项目的一个状况:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: file1
# modified: file2
# modified: file3
如果你要做进一步的修改, 那就继续做, 做完后就把新修改的文件通过add加入到索引中. 最后把他们提交:
$ git commit
这会提示你输入本次修改的注释,完成后就会记录一个新的项目版本.
除了用git add命令,我还可以用
$ git commit -a
这会自动把所有内容被修改的文件(不包括新创建的文件)都添加到索引中,并且同时把它们提交。
hint: commit注释最好以#issue_id为开头,再附上这个issue的简要描述;然后空一行再把详细的注释写清楚。这样就可以很方便的用工具来检索工程中每个开发单的进度.
Git跟踪的是内容不是文件
很多版本控制系统都提供了一个 "add" 命令:告诉系统开始去跟踪某一个文件的改动。但是Git里的 ”add” 命令从某种程度上讲更为简单和强大. git add不但是用来添加不在版本控制中的新文件,也用于添加已在版本控制中但是刚修改过的文件; 在这两种情况下, Git都会获得当前文件的快照并且把内容暂存(stage)到索引中,为下一次commit做好准备。
撒销操作
在项目的开发过程中,误操作或者需求临时变更都会要求撤销之前的提交,Git提供了多种方法来实现这些操作。git对add和commit的撤销也是不相同的。
1)对未跟踪内容的撤销
如果你修改了test1这个文件,但未将这些改动跟踪到了版本库(未进行add操作),这时只需要输入以下命令,就可以回退:
$git checkout test1
如果需要回退所有文件,可以直接输入:
$git checkout .
2)add 撤销
如果你修改了test1这个文件,并且将这些改动跟踪到了版本库(只进行了add操作,没有进行commit操作),最简单的操作就是先 删除这个文件,然后输入以下命令:
$ git checkout test1
如果跟踪的文件比较多,删除文件比较繁琐,则可以选择以下命令
$ git reset --hard HEAD
这里的HEAD指该分支中最新的一次commit内容,该命令将工程里的所有文件恢复到版本库里最近一次提交的内容。
3) commit的撤销
如果想撤销已经commit的内容,可以使用的git的revert或者reset命令。假设版本库里面有3次版本提交,分别为c1, c2, c3;有了一次版本跟踪,为a1;还有一些本地未跟踪的修改,为m1,版本库信息如下图所示。

下面将讲述如何使用reset和revert来撤销c2的提交.
revert撤销
revert命令不允许用户的本地版本库中有任何未提交的修改,所以如果强行输入revert命令,git将提示如下信息:
error: Your local changes would be overwritten by revert.
hint: Commit your changes or stash them to proceed.
fatal: revert failed
所以在revert之前,你必须将a1和m1进行提交或者撤销。假使我们撤销了a1和m1之后使用命令:
$ git revert HEAD~2
其中命令最后的数字表示在版本仓库中向后回退版本的个数。你也可以指定具体的版本id进行回退,如
$git revert $COMMIT _CODE
此时git会将撤销的c2内容与最新c3内容进行merge,并产生版本号c4', 此时版本库信息如下图所示: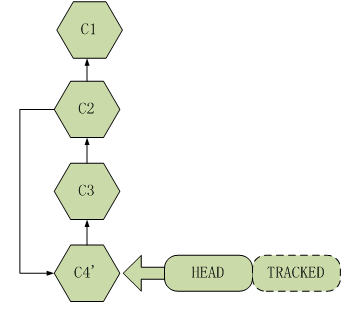
reset撤销
$ git reset --soft HEAD~2
这时在版本库中已经没有了c2,c3两次提交的内容,但是原文件test1的内容与撤销之前的内容一致,a1的跟踪信息和m1的修改内容还都存在,reset之后的版本信息如图所示:

$git reset --mixed HEAD~2
这也是reset命令在没有参数情况下的默认操作,这个命令之后版本库中已经没有了c2,c3两次提交的内容,a1的跟踪信息也被撤销,但是原文件test1的内容与撤销之前的内容一致,a1和m1的修改内容还都存在,reset之后的版本信息如图所示: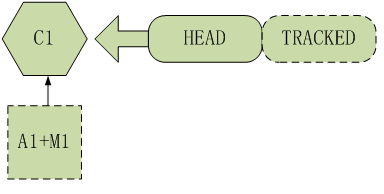
$git reset --hard HEAD~2
这个命令之后版本库中已经没有了c2,c3两次提交的内容,原文件test1的内容也变回了与c1版本一致,a1的跟踪信息和m1的修改内容都丢失,reset之后的版本信息如图所示:
比较(diff)
你可以用git diff来比较项目中任意两个版本的差异。
$ git diff master..test
上面这条命令只显示两个分支间的差异,如果你想找出‘master’,‘test’的共有父分支和'test'分支之间的差异,你用3个‘.'来取代前面的两个'.' 。
$ git diff master...test
git diff是一个难以置信的有用的工具,可以找出你项目上任意两点间的改动,或是用来查看别人提交进来的新分支。
哪些内容会被提交(commit)
你通常用git diff来找你当前工作目录中上次提交与本地索引间的差异。
$ git diff
上面的命令会显示在当前的工作目录里没有被追踪,且在下次提交时不会被提交的修改。
$ git diff HEAD~$NUM HEAD~$NUM
上面的命令会显示在当前的工作目录中两个版本号之间的差别。
如果你要看在下次提交时要提交的内容),你可以运行:
$ git diff --cached
上面的命令会显示你当前的索引和上次提交间的差异;这些内容在不带"-a"参数运行 "git commit"命令时就会被提交。
$ git diff HEAD
上面这条命令会显示你工作目录与上次提交时之间的所有差别,这条命令所显示的内容都会在执行"git commit -a"命令时被提交。
$ git diff HEAD -- ./lib
上面这条命令会显示你当前工作目录下的lib目录与上次提交之间的差别(或者更准确的说是在当前分支)。
如果不是查看每个文件的详细差别,而是统计一下有哪些文件被改动,有多少行被改动,就可以使用‘--stat' 参数。
$>git diff --stat
layout/book_index_template.html | 8 ++-
text/05_Installing_Git/0_Source.markdown | 14 ++++++
text/05_Installing_Git/1_Linux.markdown | 17 +++++++
text/05_Installing_Git/2_Mac_104.markdown | 11 +++++
text/05_Installing_Git/3_Mac_105.markdown | 8 ++++
text/05_Installing_Git/4_Windows.markdown | 7 +++
.../1_Getting_a_Git_Repo.markdown | 7 +++-
.../0_ Comparing_Commits_Git_Diff.markdown | 45 +++++++++++++++++++-
.../0_ Hosting_Git_gitweb_repoorcz_github.markdown | 4 +-
9 files changed, 115 insertions(+), 6 deletions(-)
有时这样全局性的查看哪些文件被修改,能让你更轻轻一点。
- 分支和合并
创建分支
一个Git仓库可以维护很多开发分支。现在我们来创建一个新的叫”experimental”的分支:
$ git branch experimental
此时你运行下面这条命令:
$ git branch
你会得到当前仓库中存在的所有分支列表:
experimental
* master
“experimental” 分支是你刚才创建的,“master”分支是Git系统默认创建的主分支。星号(“*”)标识了你当工作在哪个分支下,
切换分支
$ git checkout experimental
切换到”experimental”分支,先编辑里面的一个文件,再提交(commit)改动,最后切换回 “master”分支。
$ git commit -a
$ git checkout master
你现在可以看一下你原来在“experimental”分支下所作的修改还在不在;因为你现在切换回了“master”分支,所以原来那些修改就不存在了。
你现在可以在“master”分支下再作一些不同的修改:
$ git commit -a
这时,两个分支就有了各自不同的修改(diverged);我们可以通过下面的命令来合并“experimental”和“master”两个分支:
$ git merge -no-ff experimental
默认情况下,Git执行”快进式合并”(fast-farward merge),会直接将Master分支指向Develop分支。
使用–no–ff参数后,会执行正常合并,在Master分支上生成一个新节点。为了保证版本log的清晰,推荐采用这种做法。
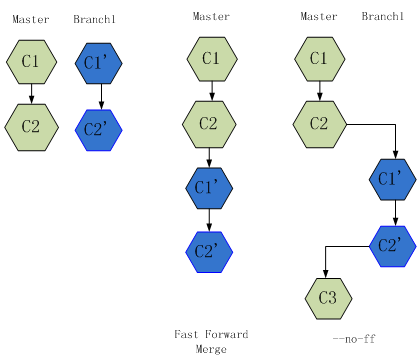
如果这个两个分支间的修改没有冲突(conflict), 那么合并就完成了。如有有冲突,会有如下类似的信息显示
100% (4/4) done
Auto-merged file.txt
CONFLICT (content): Merge conflict in file.txt
Automatic merge failed; fix conflicts and then commit the result.
输入下面的命令就可以查看当前有哪些文件产生了冲突:
$ git diff
如果执行自动合并没有成功的话,git会在索引和工作树里设置一个特殊的状态,提示你如何解决合并中出现的冲突。
有冲突(conflicts)的文件会保存在索引中,除非你解决了问题了并且更新了索引,否则执行git commit都会失败:
$ git commit
file.txt: needs merge
如果执行git status会显示这些文件没有合并(unmerged),这些有冲突的文件里面会添加像下面的冲突标识符:
<<<<<<< HEAD:file.txt
Hello world
=======
Goodbye
>>>>>>> 77976da35a11db4580b80ae27e8d65caf5208086:file.txt
你所需要的做是就是编辑解决冲突,(接着把冲突标识符删掉),再执行下面的命令:
$ git add file.txt
$ git commit
注意:提交注释里已经有一些关于合并的信息了,通常是用这些默认信息,但是你可以添加一些你想要的注释。
这时你就可以删除掉你的 “experimental” 分支了(如果愿意):
$ git branch -d experimental
git branch -d只能删除那些已经被当前分支合并的分支. 如果你要强制删除某个分支的话就用git branch –D;下面假设你要强制删除一个叫”crazy-idea”的分支:
$ git branch -D crazy-idea
- 分布式协同开发
假设Alice现在开始了一个新项目,在/home/alice/project建了一个新的git 仓库(repository);另一个叫Bob的工作目录也在同一台机器,他要提交代码。
Bob 执行了这样的命令:
$ git clone /home/alice/project myrepo
这就建了一个新的叫"myrepo"的目录,这个目录里包含了一份Alice的仓库的克隆(clone). 这份克隆和原始的项目一模一样,并且拥有原始项目的历史记录。
Bob 做了一些修改并且提交(commit)它们:
$ git commit -a
(repeat as necessary)
当他准备好了,他告诉Alice从仓库/home/bob/myrepo中把他的修改给拉 (pull)下来。她执行了下面几条命令:
$ cd /home/alice/project
$ git pull /home/bob/myrepo master
这就把Bob的主(master)分支合并到了Alice的当前分支里了。如果Alice在 Bob修改文件内容的同时也做了修改的话,她可能需要手工去修复冲突. (注意:"master"参数在上面的命令中并不一定是必须的,因为这是一个默认参数)
git pull命令执行两个操作: 它从远程分支(remote branch)抓取修改的内容,然后把它合并进当前的分支。
如果你要经常操作远程分支(remote branch),你可以定义它们的缩写:
$ git remote add bob /home/bob/myrepo
这样,Alic可以用"git fetch"" 来执行"git pull"前半部分的工作,但是这条命令并不会把抓下来的修改合并到当前分支里。
$ git fetch bob
我们用git remote命令建立了Bob的运程仓库的缩写,用这个(缩写) 名字我从Bob那得到所有远程分支的历史记录。在这里远程分支的名字就叫bob/master.
$ git log -p master..bob/master
上面的命令把Bob从Alice的主分支(master)中签出后所做的修改全部显示出来。
当检查完修改后,Alice就可以把修改合并到她的主分支中。
$ git merge bob/master
这种合并(merge)也可以用pull来完成,就像下面的命令一样:
$ git pull . remotes/bob/master
注意:git pull 会把远程分支合并进当前的分支里,而不管你在命令行里指定什么。
其后,Bob可以更新它的本地仓库--把Alice做的修改拉过来(pull):
$ git pull
如果Bob从Alice的仓库克隆(clone),那么他就不需要指定Alice仓库的地址;因为Git把Alice仓库的地址存储到Bob的仓库配库文件,这个地址就是在git pull时使用:
$ git config --get remote.origin.url
/home/alice/project
(如果要查看git clone创建的所有配置参数,可以使用"git config -l", git config的帮助文件里解释了每个参数的含义.)
Git同时也保存了一份最初(pristine)的Alice主分支(master),在 "origin/master"下面。
$ git branch -r
origin/master
如果Bob打算在另外一台主机上工作,他可以通过ssh协议来执行"clone" 和"pull"操作:
$ git clone alice.org:/home/alice/project myrepo
- 集中式Git仓库
一旦涉及多人在不同的工作目录下协同开发时,需要建立一个中央版本仓库,因为分布式的版本仓库一旦checkout之后,就不能被其他开发者主动执行push操作。下图就是一个多系统下多人合作协同开发的工作目录示意图,user1和user2需要一起合作开发一个功能,为了避免在开发完成之前就提交svn主版本库,可以运用git来进行小规模的代码同步,同时user1和user2又需要在linux和windows下面进行开发,也需要时时同步代码。为了完成这个需求,可以在windows和linux下各建立一个git工作目录,然后在任一台机子建立一个git中央版本仓库,将所有工作目录指向这个中央版本仓库。具体步骤如下: 
你还是每天在你的本地私人仓库里工作,但是会定期的把本地的修改push到你的公开仓库中;其它开发者就可以从这个公开仓库pull最新的代码。
在linux系统中创建中央版本仓库(repository),在一个空的文件夹下,输入命令:
$git --bare init
--bare 在这里是产生一个干净的中央版本仓库,仅包含版本历史记录不包含工作代码和工作目录,类似于svn服务器,这样的版本仓库可以被开发者主动push修改。
创建私有版本仓库,在个人文件夹下,输入命令:
$ git init
这样就为我们需要版本管理的代码创建了一个私有的分布式版本仓库,这个版本仓库跟我们平时在用版本仓库没有两样,你可以通过命令add,commit和reset进行版本管理。
在本地仓库添加远程仓库路径,输入命令:
$git remote add origin $CENTER_REPOSITORY_PATH
其中origin是版本库路径的别名,$CENTER_REPOSITORY_PATH
是中央版本仓库的路径,在以后的操作中可以用origin来代替。
$git push origin $BRANCH_NAME
这个命令将私有版本中的工作代码和版本历史记录添加到中央版本仓库中,其中包括这个私有版本仓库中所有的修改提交记录。
这个命令之后本地目录下的 .git/config会发生改变。
windows端checkout出代码,在msysGit的bash中,输入命令:
$ git clone origin
因为我们的服务器上的ssh协议只允许公钥/私钥远程登入,所以在执行这个命令之前需要将公私钥放到~/.ssh的目录下面。
在完成这个步骤之后,在windows和linux下已经各有一个独立的私有版本仓库,它们的地位是相同的,两者通过中央版本仓库进行代码同步。
此刻对各自私有版本仓库的commit,add和revert等操作只是对本私有版本仓库可见,修改历史对其他版本库不可见。
多人协同
user1做了些修改,然后提交修改到中央版本库
$git push origin $BRANCH_NAME
其中$BRANCH_NAME指代功能开发的分支。
user2要同步user1的修改
$ git fetch origin $BRANCH_NAME
这个是抓取一个远程的版本库中的信息到一个私有版本库中,但不更新代码。经过这个操作可以通过命令git log看到远程版本库中的所有操作。
$ git pull origin $BRANCH_NAME
这个命令真正将将user1的修改merge到当前的版本库。
经过这个操,user2已经有了user1的所有修改和提交记录。