“2018中国人工智能开源软件发展白皮书”是新手了解人工智能技术原理和技术现状的好文档,读完之后有再读几遍的冲动,学到了很多东西,做了笔记分享给大家共同学习,有不对的地方多多指出。
“2018中国人工智能开源软件发展白皮书”笔记
一,人工智能发展史
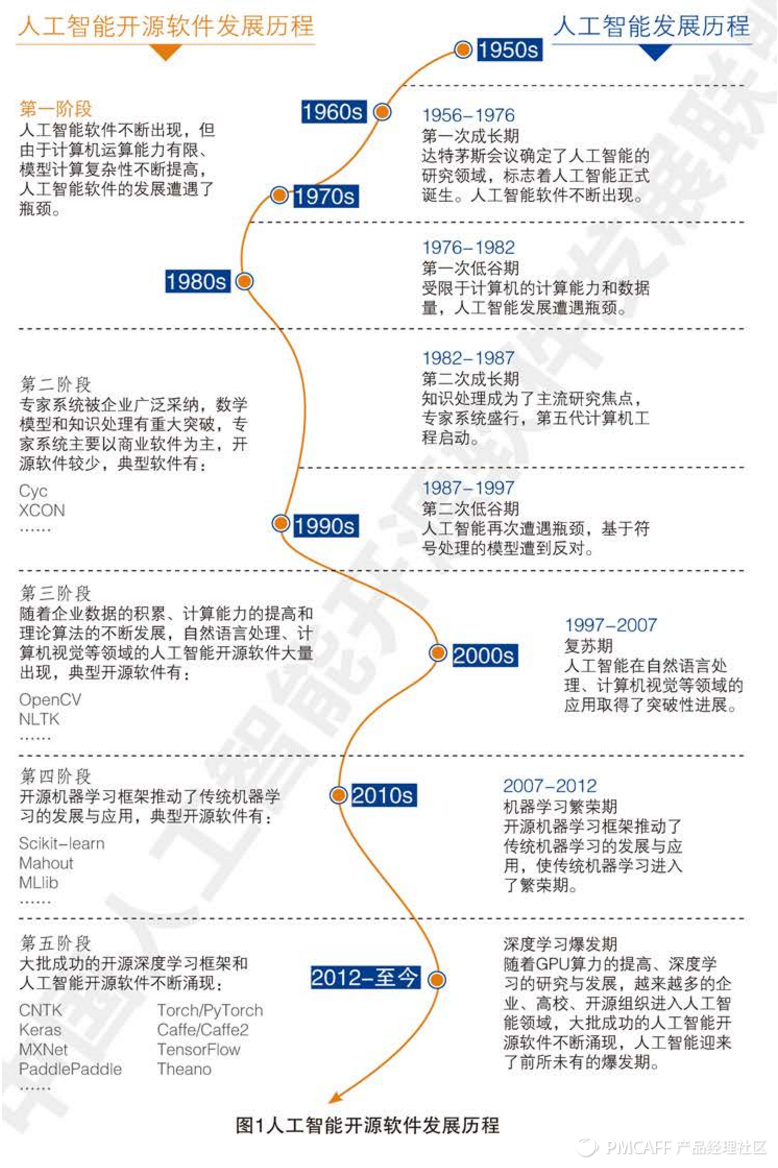
1,1956年达特茅斯会议正式确定了人工智能的研究领域,标志人工智能正式诞生。
2,达特茅斯会议后,开启了人工智能大发现时代,以推理为核心,后因计算能力和数据量进入寒冬。
3,80年代,第二次成长期,以“知识处理”为核心,在专家系统方面取得一定成就,后因迟迟达不到预期,再次进入寒冬。
4,90年代末,随着计算能力增强和内存的增加,人工智能开始复苏。97年IBM深蓝战胜国际象棋冠军,2000年的OpenCV问世,2001年NLTK问世。
5,机器学习繁荣期从07年开始,各种机器学习算法愈加完善,
6,12年人工智能深度学习算法的崛起,以及深度学习开源框架的崛起。
二,人工智能开源软件发展现状
人工智能开源计算平台,开源机器学习框架,应用领域相关的开源软件。
1,人工智能开源计算平台
计算平台由硬件和软件两部分组成,硬件加速计算能力,如GPU,FPGA,TPU,定制人工智能芯片等;软件即加速计算平台,用来匹配硬件使用,为了能够跟上硬件迭代速度,大厂商都会拥有自己的计算平台,如NVIDIA的CUDA,AMD的ROCm用于不断更新的GPU,Google的Tensorflow对应的是TPU。
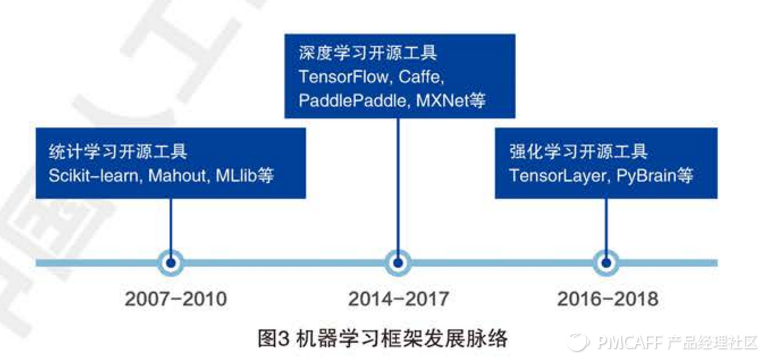
2,开源机器学习框架
Scikit-learn Mahout MLlib TensorFlow Caffe CNTK MXNet Torch PyTorch Theano PaddlePaddle
3,应用领域相关开源软件
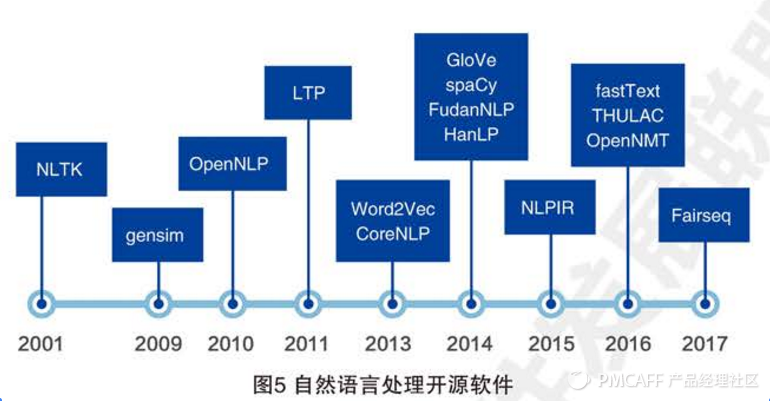
(1)自然语言处理的开源软件:
NLTK OpenNLP LTP斯坦福CoreNLP Gensim spaCy FudanNLP NLPIR THULAC
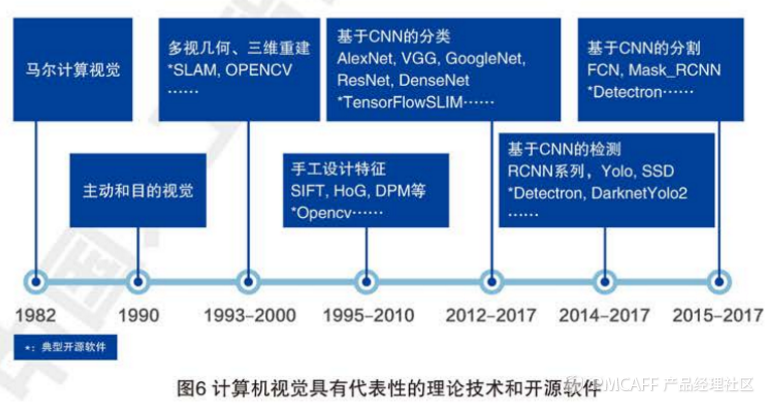
(2)计算机视觉的开源软件
OpenCV TensorFlow对象Ddtection API Detectron InsightFace Tesserac
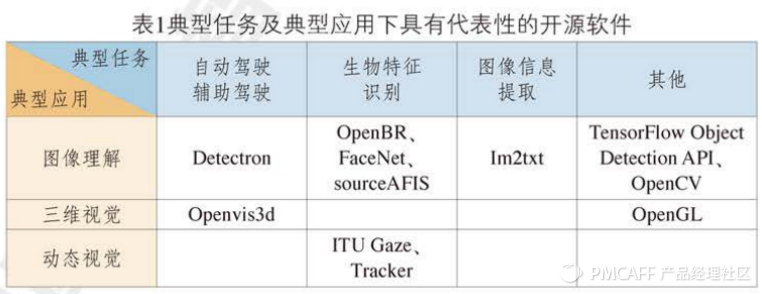
(3)智能语音:包含语音识别和语音合成
语音识别开源软件:ISIP Julius HTK CMU sphinx Kladi
语音合成开源软件:MARY Festival eSpeak Filte HTS Merlin
开源数据集:TIMIT 2000HUB5英文Libri演讲VoxForge CHIME CMU_ARCTIC
(4)无人系统:机器人,无人驾驶
(5)其他应用领域:
- 知识图谱:开放领域知识图谱(百科类和搜索引擎类的知识基础)和垂直领域知识图谱(教育,金融等行业数据积累)
- 虚拟现实与增强现实
- 游戏智能
- 信息安全
三,人工智能开源软件特性分析
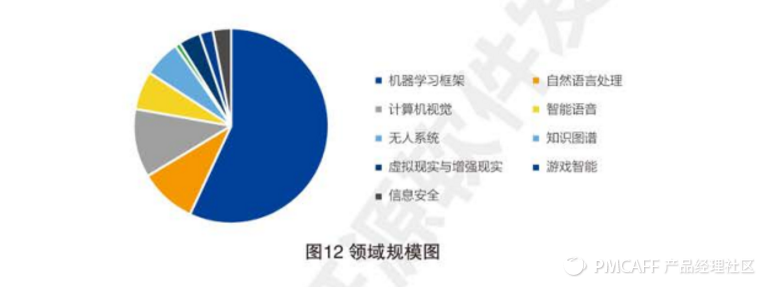
1,如下图,当前开源软件的规模,机器学习框架的发展规模最大,参与的开发者最多,自然语言处理和计算机视觉其次,详细开源软件信息见附录A.
2,编程语言特性,在人工各职能开源软件中,Python和C / C ++和Java的是主流的编程语言。
Python的:具备开发效率高,学习难度低,数据在计算方面功能强大等优势,迅速成为了数据科学家的工具,大部分人工智能开源软件也都提供了Python的借口。
C / C ++:运行速度快,成为了许多开源机器学习框架的底层开发语言。
Java的:历史悠久,功能全面,阿帕奇软件基金会的开源软件就是用的Java的。
3,框架特性:TensorFlow是所有开源机器框架中用户最多,应用最广泛的一个,大量的人工智能开源软件基于TensorFlow进行开发,且遍布各个领域,如图像分类的TensorFlow Slim,用于自标检测的TensorFlow对象检测API等。此外,Keras,Scikit-learn,Caffe,PyTorch,CNTK.MXNet,Theano等也在人工智能开源软件的发展中占据了重要地位。
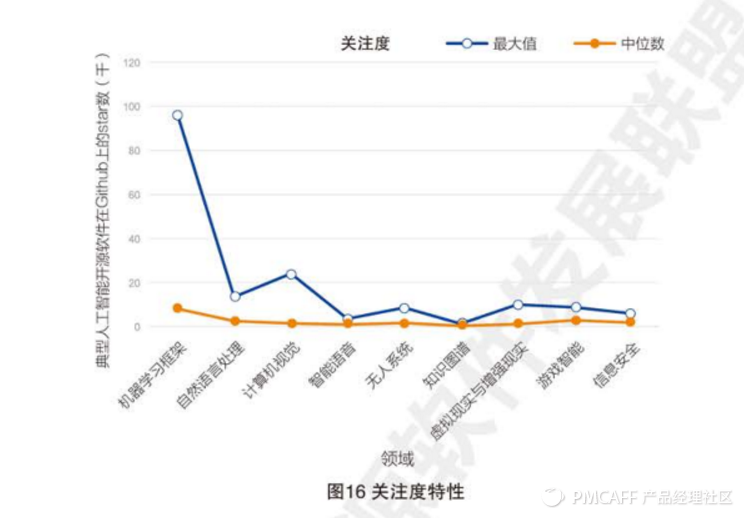
4,关注度特性:GitHub的是目前最大的开源项目托管平台,开源项目的星级数可以衡量项目的受关注程度如下图在机器学习框架领域中TensorFlow获得了近10W个星,计算机视觉领域的OpenCV的获得了2W多个明星,而知识图谱领域受关注度相对较低,最热门的项目也只获得了约1K个明星。
5,典型人工智能开发数据集特性统计:详尽附录乙
四,基于开源软件的人工智能技术典型解决方案
典型解决方案主要由四个模块构成:计算机管理,数据管理,基于机器学习的算法,领域构件 ;前两者是人工智能开源软件的基础,后两者是核心。
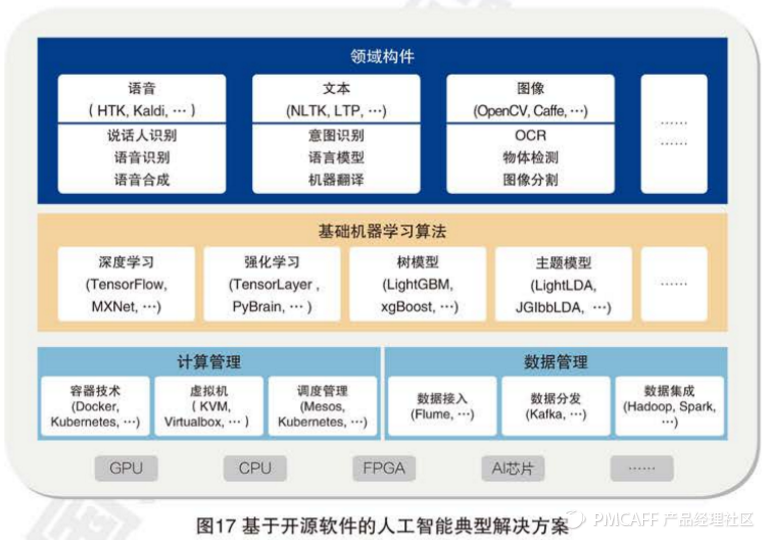
如图1所示,数据管理:包括主要数据接入,分发,集成等关键环节。
(1)数据接入:负责从数据源头采集和同步数据; Flume
(2)数据分发:负责为各接入点的数据建立高效的数据总线,将数据正确路由到正确目的地,并建立灵活的消息队列,满足数据处理时效性和准确性需求;卡夫卡
(3)数据集成:解决对各种数据源进行数据对齐,关联合并,然后对数据进行规范统一处理,并保证数据的一致性,完整性; Hadoop的,火花
2,计算管理:人工智能技术对计算资源的需求量越来越大,上客观需要灵活的弹性计算能力,虚拟机,容器成为弹性计算的两种典型基本计算单元。
(1)虚拟机技术:其基础是将一台计算机硬件资源虚拟为多台逻辑计算单元,并各自拥有可独立运行的操作系统,可以独立调度管理,实现资源的动态分配,扩容和回收,从而提高硬件资源的利用率; KVM,VirtualBox的,VMware的
(2)容器技术:是一种更轻量级的虚拟化技术,在同一个操作系统空间中,对软硬件资源进行隔离分组成许多独立安全的运行环境,这样容器分配启动动态扩容的速度更快,消耗的资源更少,以提升系统效率;泊坞
(3)调度管理:计算资源调度管理需要实时监控了解资源状态,并根据业务优先级和调度侧率,为计算任务动态分布可用的计算集群组员; Kuberneres
3,基础机器学习算法
人工智能场景中解决问题的核心是算法,这些算法包括并不限于特征抽取,分类,聚类,动态决策等;向量机(SVM),逻辑回归,贝叶斯方法,K-均值聚类,主题模型(Tapic Model),决策树,决策树的集成模型(比如随机森林和梯度提升树),(深度)神经网络,强化学习工具等。
4,领域构件
领域构件实现了基础机器学习算法从理论走向应用的关键一步,领域构件更加侧重于针对某一场景问题解决。基础学习算法和领域构件的相互促进。共同发展实现了人工智能算法在理论基础到实际应用的完整闭环。目前领域构件通常可以分为图像,语音,文本等多个领域。这些领域构件针对相关的任务进行组件化的解决方案,比如多种算法组件的结合形成了机器翻译的领域构建。
5,建立解决方案
当前开源软件比较组件化和零散化,在构建解决方案的角度往往需要将多个层次的开源环境结合起来。
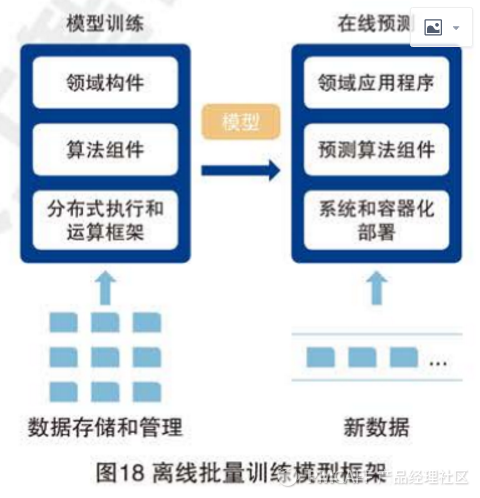
(1) 离线批量训练模型解决方案:
在行业应用中绝大部分AI模型的训练都是离线机型的,解决这些方案的整个流水线涉及数据存储管理状语从句:,模型批量训练及模型用英语预测三个部分。
如下图:离线训练这部分解决方案的一个特点是模型更新的实时性要求不高,但是的模型训练通常需要处理海量的训练数据模型训练的效率会直接影响到模型的更新迭代的速率,进而直接影响在线预测模块的服务效果。因此模型训练效率是影响这类AI解决方案的关键因素。在实际应用中,模型的训练更新离不开分布式程序的支持,充分利用集群的能力进行高速运算和存储是目前通用的解决方法。典型代表有Hadoop的,MapReduce的,参数服务器,数据流框架等面向大规模数据处理的开源并行计算框架。当然训练的时候需要使用特定的算法组件和领域构件来完成特定解决方案需要的模型。在模型训练完成后,部署的时候同样也炫耀对应的预测算法组件来完成应用层的调用任务。在线上部署的时候需要用到一些容器化系统来保证算法的快速部署和扩容。
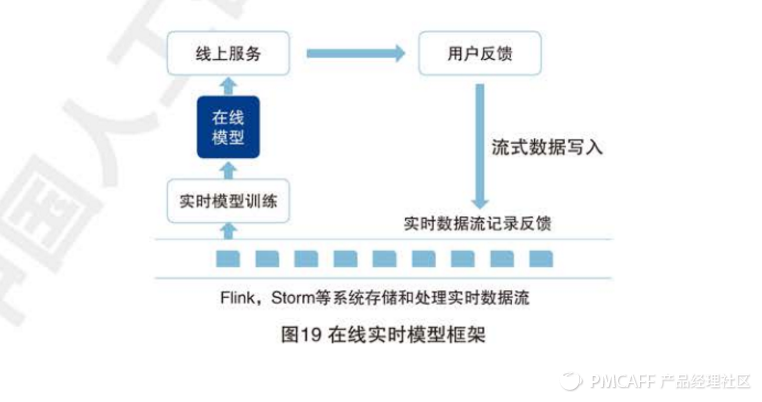
(2) 在线实时模型解决方案:
这种解决方案在很多线上服务中,往往需要跟随用户的反馈快速调整AI的模型,从而能够不断修正模型应对新的用户需求,如在线推荐系统,在线广告系统,搜索引擎系统等。在这样的系统中AI模型不是固定不变的,整个流水线中由线上服务部分(通常利用一些容器和流量均衡控制的系统来支持),线上数据收集和存储的实时数据系统部分,实时模型训练几个部分组成。
如下图:实时模型训练的部分通常是基于实时数据流系统来完成的(典型的代表如弗林克,风暴),系统会调度机器资源,基于实时的数据完成模型(比如的FTR1,MAB,或者强化学习模型)更新,这些模型训练的代码在很多开源软件中可以找到,最重要的是将这些算法接入到实时计算系统中来,适应平台的数据接口。当模型更新完成后线上服务会用最新的模型进行服务。
这类的系统同时适应较常见的自动控制系统,如机器人控制,自动驾驶等。
四,其他章节
“人工智能开源软件生态分析”
“中国人工智能开源软件发展建议”
(以上两章是关于人工智能开源软件的商务商业文化等介绍和建议,对于大部分同学来说没有“干货”,有兴趣大家可以到我的下载主页源文件查阅,另外文中提到的附录甲/ B,在源文件中。)