众所周知大型网站都是并发支持,用到最多的也是生产者与消费者模式。
- 生产消费者模型
生产者消费者模型具体来讲,就是在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品。
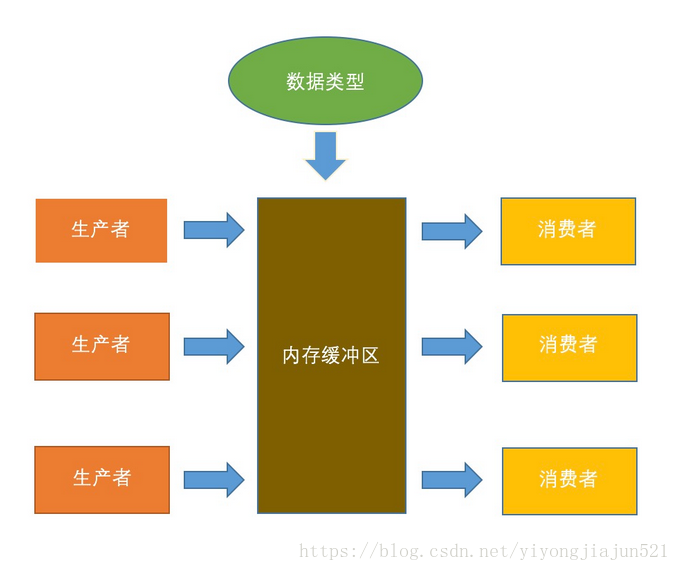
,譬如注册用户这种服务,它可能解耦成好几种独立的服务(账号验证,邮箱验证码,手机短信码等)。它们作为消费者,等待用户输入数据,在前台数据提交之后会经过分解并发送到各个服务所在的url,分发的那个角色就相当于生产者。消费者在获取数据时候有可能一次不能处理完,那么它们各自有一个请求队列,那就是内存缓冲区了。做这项工作的框架叫做消息队列。
- 生产者消费者模型的实现
生产者是一堆线程,消费者是另一堆线程,内存缓冲区可以使用List数组队列,数据类型只需要定义一个简单的类就好。关键是如何处理多线程之间的协作。这其实也是多线程通信的一个范例。
在这个模型中,最关键就是内存缓冲区为空的时候消费者必须等待,而内存缓冲区满的时候,生产者必须等待。其他时候可以是个动态平衡。值得注意的是多线程对临界区资源的操作时候必须保证在读写中只能存在一个线程,所以需要设计锁的策略。
这下来是代码:
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 生产者
* @author Administrator
*
*/
public class Product implements Runnable {
//定义一个标志位,来判定他是执行还是阻塞
private volatile boolean isRunning = true;
//队列
private BlockingQueue<PCData1> queue;//内存缓存区区
private static AtomicInteger count = new AtomicInteger();//原子性
private static final int SLEEPTIME = 1000;
public Product(BlockingQueue<PCData1> queue) {
super();
this.queue = queue;
}
public Product(boolean isRunning, BlockingQueue<PCData1> queue) {
super();
this.isRunning = isRunning;
this.queue = queue;
}
@Override
public void run() {
//首先判断对象的数据是否为空
PCData1 data = null;
//创建一个随机数对象
Random r = new Random();
//这句话的命令式,开始执行并且获取id
System.out.println("start product id"+Thread.currentThread().getId());
try {
//首先isRunning这个是那个为真,也就是会一直循环下去
while (isRunning) {
//线程休眠,根据随机生成的数,再乘以1000
Thread.sleep(r.nextInt(SLEEPTIME));
data = new PCData1(count.incrementAndGet()) ;
System.out.println("加入队列"+data+"队列");
if(!queue.offer(data,2,TimeUnit.SECONDS)){
System.out.println("加入队列失败");
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
public void stop(){
isRunning = false;
}
}
class PCData1{
private final int intData;
public int getIntData() {
return intData;
}
public PCData1(int d) {
intData = d;
}
public PCData1(String d) {
intData = Integer.valueOf(d);
}
@Override
public String toString() {
return "PCData [intData=" + intData + "]";
}
}消费者代码:
import java.text.MessageFormat;
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import sun.misc.MessageUtils;
/**
* 消费者
* @author Administrator
*
*/
public class Custom implements Runnable {
private BlockingQueue<PCData1> queue;
private static final int SLEEPTIME = 1000;
public Custom(BlockingQueue<PCData1> queue) {
super();
this.queue = queue;
}
@Override
public void run() {
System.out.println("start custom id"+Thread.currentThread().getId());
Random r = new Random();
try {
while(true){
PCData1 data = queue.take();
if(data!= null){
int rm = data.getIntData() * data.getIntData();
//MessageFormat主要用作字符串转换。
System.out.println(MessageFormat.format("{0}*{1}={2}", data.getIntData(),data.getIntData(),rm));
Thread.sleep(r.nextInt(SLEEPTIME));
}
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
Thread.interrupted();
}
}
}
主方法的调用:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
public class Test {
public static void main(String[] args) throws InterruptedException {
LinkedBlockingQueue<PCData1> queue = new LinkedBlockingQueue<>(10);
Product p1 = new Product(queue);
Product p2 = new Product(queue);
Product p3 = new Product(queue);
Custom c1 = new Custom(queue);
Custom c2 = new Custom(queue);
Custom c3 = new Custom(queue);
ExecutorService execution = Executors.newCachedThreadPool();
execution.execute(p1);
execution.execute(p2);
execution.execute(p3);
execution.execute(c1);
execution.execute(c2);
execution.execute(c3);
Thread.sleep(10000);
p1.stop();
p2.stop();
p3.stop();
Thread.sleep(1000*10);
}
}现在我们队其中的某些东西做解释:先说这个队列;
谈到线程池,不得不谈到生产者-消费者模式,谈到生产者-消费者,就不得不谈到对应的数据结构,谈到对应的数据结构不得不言BlockingQueue。

顾名思义,BlockingQueue翻译为阻塞队列。队列无非两种操作:入队和出队。而针对于入队出队的边界值的不同,分为几个方法:
| 抛出异常 |
特殊值 |
阻塞 |
超时 |
|
| 插入 |
||||
| 移除 |
||||
| 检查 |
不可用 |
不可用 |
BlockingQueue:因为BlockingQueue是一个阻塞队列,它的存取可以保证只有一个线程在进行,所以根据逻辑,生产者在内存满的时候进行等待,并且唤醒消费者队列,反过来消费者在饥饿状态下等待并唤醒生产者进行生产。
从上述代码也可以看出,BlockingQueque还有几个特点:
1. 不接受null值。
2. 线程安全,方法都用了Lock
3. 最最精华的部分:生产者-消费者模型。
阻塞队列的实现类
基本的任务排队方式有三种:
有界:ArrayBlockingQueue: 一个由数组支持的有界阻塞队列。
无界:LinkedBlockingQueue: 一个基于已链接节点的、范围任意的blocking queue。
同步移交:SynchronousQueue: 同步队列,put和take串行执行。生产者对其的插入操作必须等待消费者的移除操作,反之亦然。同步队列类似于信道,它非常适合传递性设计,在这种设计中,在一个线程中运行的对象要将某些信息、事件或任务传递给在另一个线程中运行的对象,它就必须与该对象同步。
而线程池的选择上:
单一线程池:可以看到corePoolSize=1;
固定大小线程池:corePoolSize和maximumPoolSize固定;
无界线程池:maximumPoolSize为Integer.MAX_VALUE;
前两者默认情况下将使用一个无界的LinkedBlockingQueue。如果所有工作者线程都处于忙碌状态,那么任务将在队列中等候。如果任务持续快速地到达,并且超过了线程池处理他们的速度,那么队列将无限制地增加。
一种更稳妥的资源管理策略是使用有界队列,例如ArrayBlockingQueue、有界的LinkedBlockingQueue、PriorityBlockingQueue。有界队列有助于避免资源耗尽的情况发生,但它又带来了新的问题:当队列填满后,新的任务该怎么办?(这就需要一些饱和策略)在使用有界队列工作时,队列的大小与线程池的大小必须一起调节。如果线程池较小而队列较大,那么有助于减少内存使用量,降低CPU的使用率,同时可以减少上下文切换,但付出的代价是可能会限制吞吐量。
对于非常大的或者无界的线程池,可以通过使用SynchronousQueue来避免任务排队,以及直接将任务从生产者移交给工作者线程。SynchronousQueue不是一个真正的队列,而是一种在线程之间进行移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接受这个元素。如果没有线程正在等待,并且线程池的当前大小小于最大值,那么ThreadPoolExecutor将创建一个新的线程,否则根据饱和策略,这个任务将被拒绝。使用直接移交将更高效,因为任务会直接移交给执行它的线程,而不是被首先放在队列中,然后由工作者线程从队列中提取该任务。只有当线程池是无界或者可以拒绝任务时,SynchronousQueue才有实际价值。
对于Executor,newCachedThreadPool工厂方法是一种很好的默认选择。它能提供比固定大小的线程池更好的排队性能。当需要限制当前任务的数量以满足资源管理需求时,那么可以选择固定大小的线程池,就像在接受网络客户请求的服务器应用程序中,如果不进行限制,那么狠容易发生过载问题。
从另一个维度来看:cpu密集型任务,由于cpu使用率一直很高,这时的线程不宜过多,建议配置尽可能小的线程,如配置Ncpu+1个线程的线程池。IO密集型任务由于线程并不是一直在执行任务,IO比较频繁,所以可以配置较多的线程,如2*Ncpu。