python3 中将utf-8编码与汉字
在爬取网页时,我们经常需要找到网页的url,例如https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E8%95%BE%E5%A7%86&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=%E8%95%BE%E5%A7%86&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1521104335732=
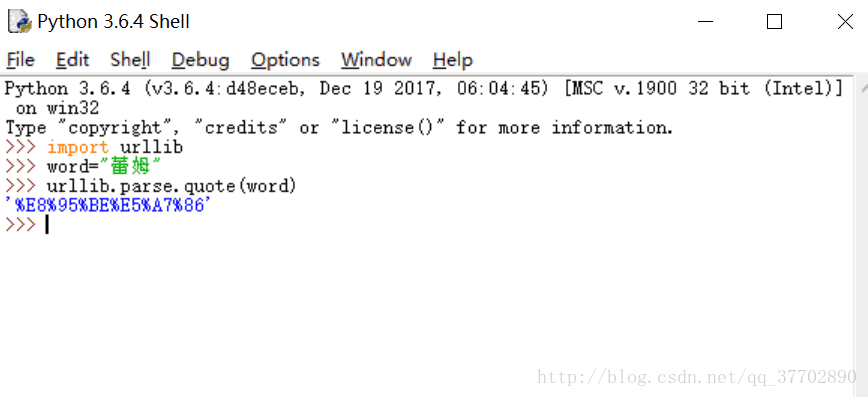
这个url中粗体的部分,就是汉字“蕾姆”的utf-8编码,那么我们如何确认呢?
import urllib
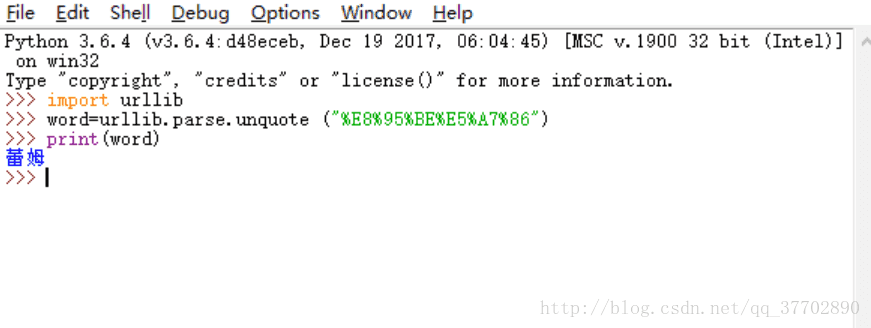
word=urllib.parse.unquote("%E8%95%BE%E5%A7%86")
print(word)运行结果:
那我们如何在将汉字转为utf-8编码的呢?
这里要用到quote函数