基于netty 4.0官方文档
http://netty.io/4.0/api/index.html
Netty-ByteBuf
继承关系:
java.lang.Object
->io.netty.buffer.ByteBuf实现的接口:
ReferenceCounted, java.lang.Comparable<ByteBuf>1.几个比较重要的概念
- readerIndex:>= 0,指向读取的开始位置
- writerIndex:>= readerIndex, 指向写入的开始位置
- capacity:>= writerIndex, 可以存储的最大字节数
2.创建ByteBuf
可以使用Unpooled类提供的静态方法
import static io.netty.buffer.Unpooled.*;
ByteBuf heapBuffer = buffer(128);
ByteBuf directBuffer = directBuffer(256);
ByteBuf wrappedBuffer = wrappedBuffer(new byte[128], new byte[256]);
ByteBuf copiedBuffer = copiedBuffer(ByteBuffer.allocate(128));3.基于下标的访问
ByteBuf可以像普通的数组一样,通过下标来访问表中的数据
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i ++) {
byte b = buffer.getByte(i);
System.out.println((char) b);
}4.按序读写
ByteBuf中提供了两个指针,其中readerIndex指向读取的位置,writerIndex指向写入的位置。如下图所示:
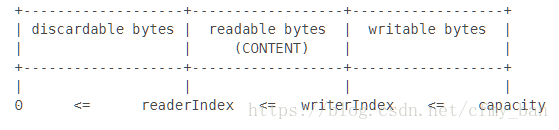
readerIndex和writerIndex将整个ByteBuf分成了三个部分,其中:
Readable bytes (readerIndex ~ writerIndex)
这部分bytes是ByteBuf实际存储内容的区域,此区域中包含的都是还未被读取的数据,任何read或者skip操作都将从readerIndex开始,并最终根据读取的字节数提升readerIndex,如果想要读取的字节数大于此区域大小将会抛出IndexOutOfBoundsException。
如果read操作传入的参数也是一个ByteBuf,那么这个ByteBuf参数的writerIndex 也会一同增长。(即把当前read操作的ByteBuf中readable bytes读出后写入到了参数ByteBuf中)
Writable bytes (writerIndex ~ capacity)
Writable bytes是ByteBuf中还未使用的bytes。任何写操作都将从writerIndex开始,并最终根据写入的字节数来修改writerIndex。如果想要写入的字节数大于此部分的容量,将会抛出IndexOutOfBoundsException
与read操作类似,如果write操作传入的参数也是一个ByteBuf,那么这个ByteBuf参数的ReaderIndex也会一同增长。(即把参数ByteBuf中的bytes读取出来然后写入到了当前write操作的ByteBuf中)
Discardable bytes (0 ~ readerIndex)
这部分bytes是已经被读取过了的,可以被丢弃的bytes。初始这部分bytes的大小为0,经过读取操作最大可以增加到writerIndex。
可以通过调用discardReadBytes()来使这部分bytes可以被重新使用。

值得注意的是,discardReadBytes() 并不能保证原本的writable bytes不被修改。基于不同的对于ByteBuf的实现,writable bytes可能不会改变,也可能会被填充为完全不同的数据。
清除ByteBuf的indexes
调用clear()方法将会把readerIndex和writerIndex都设为0。 该方法不会清除已有的数据,只是将两个指针重置为0。

5.搜索操作
搜索单独的byte的话,可以使用 indexOf(int, int, byte) 和 bytesBefore(int, int, byte) 方法。bytesBefore(int, int, byte) 对于以空字符结尾的字符串尤其有用。对于更复杂的搜索操作,可以调用 forEachByte(int, int, ByteBufProcessor) 来实现。
6.标记和恢复
在每个buffer中都有两个分别用来记录readerIndex和writerIndex的index。调用 markReaderIndex() 和 markWriterIndex() 会分别将当前的对应index保存到marker index中。调用 resetReaderIndex() 和 resetWriterIndex() 将恢复以存储的indexes。
7.派生buffer
调用duplicate(), slice()或者slice(int, int) 都将返回一个基于当前ByteBuf的派生buffer,派生的buffer将会有独立的readerIndex和writerIndex以及marker indexes,但是会与原ByteBuf共享相同的数据。
1.可以调用 copy() 方法来获得一个深拷贝的ByteBuf
2.需要注意派生buffer并不会使该ByteBuf的引用计数增加。