Mybaits与JDBC进行比较的话,你会发现相同功能下,mybaits能够省略到大部分的代码,且使SQL语句不出现在代码程序中,将所有的SQL集中在映射文件中,这将更加有利于未来的功能维护升级,这些正是mybaits的强大之处之一。
Mybaits映射文件只有很少的几个顶级元素:
cacha:给定命名空间的缓存配置。
cacha-ref:其他命名空间缓存配置的引用
resultMap:用来描述如何从数据库结果集中来加载对象,是最复杂也是最强大的元素,也是我们在开发中必然会遇到的元素
sql:可被其他语句引用的可重用语句块
insert:映射插入语句
update:映射更新语句
delete:映射删除语句
select:映射查询语句
虽然顶级元素不多,但是其中的属性确实繁多,功能也十分强大,接下来将从语句本身开始来描述每个元素的细节
select
查询语句是我们在日常开发和使用中最常用的语句,对每个插入、更新或删除操作,通常对应多个查询操作。这是 MyBatis 的基本原则之一,也是将焦点和努力放到查询和结果映射的原因。简单查询的 select 元素是非常简单的。比如:
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>这个语句被称作 selectPerson,接受一个 int(或 Integer)类型的参数,并返回一个 HashMap 类型的对象,其中的键是列名,值便是结果行中的对应值。注意SQL语句中的#{id},这相当于JDBC中预处理语句,此处指传进的int参数
parameterType 和resuleType 是select元素的属性,分别代表的参数类型和返回结果类型,除此之外,select还有其他属性,属性和功能具体如下:
| 属性 | 描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 |
| parameterType | 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。 |
| resultType | 从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用 resultType 或 resultMap,但不能同时使用。 |
| resultMap | 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,对其有一个很好的理解的话,许多复杂映射的情形都能迎刃而解。使用 resultMap 或 resultType,但不能同时使用。 |
| flushCache | 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false。 |
| useCache | 将其设置为 true,将会导致本条语句的结果被二级缓存,默认值:对 select 元素为 true。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。 |
| fetchSize | 这是尝试影响驱动程序每次批量返回的结果行数和这个设置值相等。默认值为 unset(依赖驱动)。 |
| statementType | STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 中的一个,默认值为 unset (依赖驱动)。 |
| databaseId | 如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
| resultOrdered | 这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组了,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false。 |
| resultSets | 这个设置仅对多结果集的情况适用,它将列出语句执行后返回的结果集并每个结果集给一个名称,名称是逗号分隔的。 |
insert 、delete和update
同select类似,都是SQL语句,都可以使用#{}来传入参数,具体的属性和功能如下:
| 属性 | 描述 |
|---|---|
| id | 命名空间中的唯一标识符,可被用来代表这条语句。 |
| parameterType | 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 MyBatis 可以通过 TypeHandler 推断出具体传入语句的参数,默认值为 unset。 |
| flushCache | 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true(对应插入、更新和删除语句)。 |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为 unset(依赖驱动)。 |
| statementType | STATEMENT,PREPARED 或 CALLABLE 的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
| useGeneratedKeys | (仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。 |
| keyProperty | (仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| keyColumn | (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 PostgreSQL)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| databaseId | 如果配置了 databaseIdProvider,MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略。 |
示例如下:
<insert id="insertAuthor">
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
</insert>
<update id="updateAuthor">
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
</update>
<delete id="deleteAuthor">
delete from Author where id = #{id}
</delete>事实上insert语句的配置规则会相对更加丰富许多,在插入语句中有一些额外的属性和子元素用来才处理主键的生成,而且有多种生成方式。
首先,如果你的数据库支持自动生成主键的字段(比如MySQL可以设置主键自增长),那么你可以设置useGenerateKeys=“true”,然后再把keyProperty设置到目标属性上就OK了,比如如果上面的Author表已经对id使用了自动生成的列类型,那么语句可以修改为:
<insert id="insertAuthor" useGeneratedKeys="true"
keyProperty="id">
insert into Author (username,password,email,bio)
values (#{username},#{password},#{email},#{bio})
</insert>此时,插入语句不再需要插入id列的值
如果你的数据库支持多行插入,则可以传入一个Author数组或则集合,并返回自动生成的主键。
<insert id="insertAuthor" useGeneratedKeys="true"
keyProperty="id">
insert into Author (username, password, email, bio) values
<foreach item="item" collection="list" separator=",">
(#{item.username}, #{item.password}, #{item.email}, #{item.bio})
</foreach>
</insert>如果你的数据库不支持自动生成主键,mybaits也有方法来生成主键:
<insert id="insertAuthor">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select CAST(RANDOM()*1000000 as INTEGER) a from SYSIBM.SYSDUMMY1
</selectKey>
insert into Author
(id, username, password, email,bio, favourite_section)
values
(#{id}, #{username}, #{password}, #{email}, #{bio}, #{favouriteSection,jdbcType=VARCHAR})
</insert>当然此处生成主键的方式是不对的,主键必须确保唯一性,这里使用随机函数,是有可能会重复的,仅用于说明mybaits能够处理生成主键,一般情况下只要通过代码生成唯一主键在传进SQL语句就可以了
selectkey 元素的属性及功能如下:
| keyProperty | selectKey 语句结果应该被设置的目标属性。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| keyColumn | 匹配属性的返回结果集中的列名称。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
| resultType | 结果的类型。MyBatis 通常可以推算出来,但是为了更加确定写上也不会有什么问题。MyBatis 允许任何简单类型用作主键的类型,包括字符串。如果希望作用于多个生成的列,则可以使用一个包含期望属性的 Object 或一个 Map。 |
| order | 这可以被设置为 BEFORE 或 AFTER。如果设置为 BEFORE,那么它会首先选择主键,设置 keyProperty 然后执行插入语句。如果设置为 AFTER,那么先执行插入语句,然后是 selectKey 元素 - 这和像 Oracle 的数据库相似,在插入语句内部可能有嵌入索引调用。 |
| statementType | 与前面相同,MyBatis 支持 STATEMENT,PREPARED 和 CALLABLE 语句的映射类型,分别代表 PreparedStatement 和 CallableStatement 类型。 |
sql这个元素可以用来定义可重用的SQL代码段,但是不推荐使用,故不做过多介绍
cacha:缓存
mybatis提供查询缓存,如果缓存中有数据就不用从数据库中获取,用于减轻数据压力,提高系统性能。
一级缓存是sqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域是互相不影响的,mybatis默认支持一级缓存
二级缓存是mapper级别的缓存,多个sqlSession去操作同一个mapper的sql语句,多个sqlSession可以共用二级缓存,二级缓存是跨SqlSession的,mybaits默认是没有开启二级缓存的
一级缓存原理
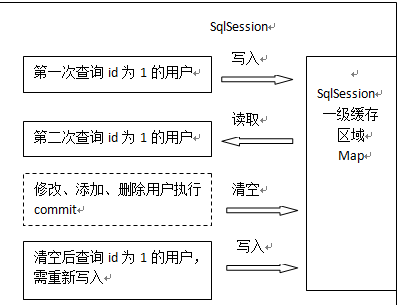
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
sqlSession如果执行了commit操作(插入、更新、删除),清空sqlSession中的一级缓存,这样做的目的是为了让缓存中存储的是最新的信息,避免脏读。
清空缓存后再次查询id为1的用户信息,操作与第一次发起查询相同。
二级缓存原理:

二级缓存是mapper级别的。
第一次调用mapper下的sql去查询用户信息,查询到的信息会缓存到该mapper对应的二级缓存区域内。
第二次调用相同namespace下的mapper映射文件中相同的SQL去查询用户信息。会去对应的二级缓存内取结果
如果调用相同namespace下的mapper映射文件中的增删改SQL,并执行了commit操作,此时会清空该namespace下的二级缓存。
开启二级缓存的方法:
1、在全局配置文件中加入以下内容(开启二级缓存总开关):
<!-- 开启二级缓存总开关 -->
<setting name="cacheEnabled"value="true"/>
2、在mapper文件中,加入以下内容,开启二级缓存
<!-- 开启本mapper下的namespace的二级缓存,默认使用的是mybatis提供的PerpetualCache -->
<cache></cache>
具体执行某条sql语句时可以设置禁用二级缓存,设置userCache=false,即每次查询都是去数据库中查询,默认情况下是true。
<select id="findUserById" parameterType="int"
resultType="cn.itcast.mybatis.po.User" useCache="false">
SELECT * FROM user WHERE id = #{id}
</select>
同样的,我们也可以设置执行具体的某个sql时刷新缓存,默认情况下是select不刷新,insert、update、delete刷新缓存,只需要设置flushCashe=true即可,当然,你也可以把insert、delete、update的flushCashe设置成false
<select id="findUserById" parameterType="int"
resultType="cn.itcast.mybatis.po.User" useCache="true" flushCache="true">
SELECT * FROM user WHERE id = #{id}
</select>
还可以设置高级一点的二级缓存,例如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>这个更高级的配置创建了一个FIFO缓存,并每隔60秒刷新,存数结果对象或列表的512个引用,而且返回的对象被认为是只读的,因此在不同的线程中的调用者之间修改它们会导致冲突。
可用的收回策略有:
LRU-最近最少使用的;移除最长时间不被使用的对象
FIFO-先进先出;按对象进入缓存的顺序来移除它们
SOFT-软引用;移除基于垃圾回收器状态和软引用规则的对象
WEAK-弱引用;更积极地移除基于垃圾收集器状态和弱引用规则的对象
默认的是LRU
ResultMap标签功能非常强大且非常有用,我将另起一片博文详细介绍
值得一提的是mapper文件中参数的传入形式,除了简单的参数类型,当我们传入一个复杂的对象时,mybaits的处理方式十分简便,例如:
<insert id="insertUser" parameterType="User">
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
</insert>如果User类型的参数对象传递到了语句中(这个User进行了全局声明,否则需要输入具体的路径,比如:com.xxx.xxx.pojo.User)id、username、password属性将会被查找,然后将它们的值传入预处理语句的参数中,前提是User类中要有id、username、password的get、set方法。
需要注意的是,默认情况下,使用#{}格式的语句会导致mybaits创建PreparedStatement参数并安全地设置参数(就像预处理的?一样),这样做更安全也更便捷,但是有时你需要在sql语句中插入一个不转义的字符串。比如ORDER BY,此时需要使用${}格式的语句。例如:
ORDER BY ${columnName}需要说明的是:
1.当${}接受简单类型的参数时,${}里面只能是value
2.${}会引起SQL注入,所以要谨慎使用。