Linux进阶资源
Command line one-liners
the-art-of-command-line
Linux工具快速教程
快乐的 Linux 命令行
Linux Tutorial
UNIX Tutorial for Beginners
像黑客一样使用 Linux 命令行
高效使用 Linux 命令行
统计使用命令的频率
$ history | awk '{print $2}' | sort | uniq -c | sort -rn | head -10RTFM 阅读那该死的手册
Read The Fucking Manual的缩写,翻成中文是“阅读那该*死的手册”。
man命令,显示使用手册
在手册中移动
我们来学习如何在手册页面中移动:
键盘上的方向键:向上键和向下键可以使我们实现上一行和下一行的跳转。
键盘上的PgUp和PgDn(或者空格键)键:实现上一页和下一页的跳转。
键盘上的Home和End键:实现开始和结尾的跳转。
键盘上的/键(斜杠):实现搜索,和之前在less命令中功能类似。
键盘上的Q键:退出手册页。apropos命令:查找命令
在使用man命令时,我们需要先知道我们要显示使用手册的那个命令的名字。那如果不知道那个命令叫什么怎么办呢?
这时候我们就需要请apropos命令上场了,apropos是英语“关于”的意思。
apropos命令的用法很简单,只要后接一个关键字,apropos命令就会为你在所有手册页中查找相关的命令。
因此apropos命令与man命令有点对立的关系,man命令用于显示命令的使用手册,而apropos命令用于根据手册中的关键字来找到命令。
想要知道如何用终端的命令来控制音量
apropos sound-h或–help参数
-h参数中的h是help的首字母,help是英语“帮助”的意思。所以-h或–help参数的作用是显示帮助文档。
比如我们要查看apt-get命令的帮助文档,可以这样:
apt-get -hwhatis命令
what是英语“什么”的意思,is是英语“是”的第三人称单数形式。所以连起来what is就是“是什么”的意思。
whatis命令可以说是man命令的精简版,它只会列出man命令显示的手册的开头部分,就是概述命令的作用。
例如用whatis命令来查看ls命令的作用。
whatis ls快捷键
Ctrl + L 用于清理终端的内容,就是清屏的作用。其实clear命令也有同样效果
Ctrl + D 给终端传递EOF (End Of File,文件结束符)如果你在命令行提示符后什么也不输入的情况下直接按下这组快捷键,那么就会关闭当前的终端。
Shift + PgUp 用于向上滚屏,与鼠标的滚轮向上滚屏是一个效果,但岂不是很方便吗?
Shift + PgDn 用于向下滚屏,与鼠标的滚轮向下滚屏是一个效果。
Ctrl + A 光标跳到一行命令的开头。一般来说,Home键有相同的效果。
Ctrl + E 光标跳到一行命令的结尾。一般来说,End键有相同的效果。
Ctrl + U 删除所有在光标左侧的命令字符。
Ctrl + K 删除所有在光标右侧的命令字符。
Ctrl + W 删除光标左侧的一个“单词”,这里的“单词”指的是用空格隔开的一个字符串。例如 -a 就是一个“单词”。
Ctrl + Y 粘贴用Ctrl + U, Ctrl + K或Ctrl + W“删除”的字符串,有点像“剪切-粘贴”。tmux是一款终端中的分屏工具
sudo apt-get install tmuxtmux的使用方法见tmux快捷键
flux是一款护眼工具,能根据一天中的不同时间自动调节屏幕亮度
sudo add-apt-repository ppa:nathan-renniewaldock/flux
sudo apt-get update
sudo apt-get install fluxguiLinux写代码的夜间模式(保护眼睛),在Linux中安装f.lux
1.自动创建中间目录
mkdir:创建一个目录
mkdir也可以同时创建好几个目录:
mkdir new_folder new_folder_2如果我所要创建的目录的名字里有空格怎么办呢?
很简单,加上双引号:
mkdir "new folder"还可以用 -p 参数来递归创建目录结构。
mkdir -p /tmp/123/345/567mkdir -p会自动创建中间缺的目录,而不需要一个个的按顺序创建。
就会先创建123这个目录,在123目录里面创建345这个目录,在345里面再创建567这个目录:
touch命令:创建一个空白文件.
touch在英语中是“触摸,触碰”的意思,就是说我碰一下那个文件,让电脑以为我刚修改过。
touch命令其实一开始的设计初衷是修改文件的时间戳,就是可以修改文件的创建时间或修改时间,让电脑以为文件是在那个时候被修改或创建的。
用touch命令同时创建多个文件:
touch new_file new_file_2在创建文件的时候,如果需要一次性创建多个文件,比如:“love_1_linux.txt,love_2_linux.txt,… love_10_linux.txt”。
touch love_{1..10}_linux.txt如果所要创建的文件的名字里有空格怎么办呢?
很简单,加上双引号:
touch "new file"cp命令和mv命令:拷贝文件和移动文件
cp命令:拷贝文件或目录
拷贝刚才创建的new_file文件怎么做呢?
cp new_file new_file_copy第一个文件new_file是已经存在的文件,也就是被拷贝的文件;第二个文件new_file_copy是需要创建的文件,是new_file的副本,内容一模一样。
复制文件到另一个目录
只需要把cp命令的第二个参数换成目录名。
cp new_file one/上面的命令就把new_file这个文件拷贝到了one这个目录中
拷贝目录
要拷贝目录,只要在cp命令之后加上-R参数(注意是大写的R)。拷贝的时候,目录中的所有内容(子目录和文件)都会被拷贝。
cp -R one one_copy之前,我们创建了一个目录one,现在我们将其拷贝为one_copy
*使用通配符*
*号(星号)是很常用的正则表达式的符号,被称为“通配符”,顾名思义就是百搭,可以替代任意字符串。
cp *.txt folder
那么就会把当前目录下所有txt文件拷贝到folder这个子目录当中。
mv命令:移动文件
cp命令就好比Windows中的复制+黏贴,而mv命令就好比Windows中的剪切+黏贴。
mv命令来移动目录很简单,不需要额外的参数,就跟移动文件一样:
mv new_folder one以上命令将new_folder这个目录(包括其下的子目录和文件)移动到one这个目录中。
除了移动文件,mv命令还可以用于重命名文件
mv new_file renamed_file以上命令会将new_file重命名为renamed_file
rm命令:删除文件和目录
rm是英语remove的缩写,表示“移除”。这个命令就是用来删除东西的。
同时删除多个文件,只要用空格隔开每个文件即可。例如:
rm file1 file2 file3i 参数:向用户确认是否删除
保险起见,用rm命令删除文件时,可以加上 -i 参数,这样对于每一个要删除的文件,终端都会询问我们是否确定删除。i是英语inform的缩写,表示“告知,通知”。
-f参数:慎用,不会询问是否删除,强制删除
如果在rm命令后加上-f参数,那么终端不会询问用户是否确定删除文件,不论如何,文件会立刻被强制删除。
f是英语force的缩写,表示“强迫,强制”。
rm -f file以上命令会强制删除file文件。
-r参数:递归地删除
r是英语recursive的缩写,表示“递归的”。所以使用-r参数,可以使rm命令删除目录,并且递归删除其包含的子目录和文件。
这个命令也挺危险的,用得不好可能你的子目录和文件都没了。
rm -r one以上命令会删除one这个目录,包括其子目录和文件。
rm命令加-r和-f参数:极为危险!
千万不要这样做!
rm -rf /* 或者 rm -rf /rm:rm命令,这个没问题吧,删除命令么。
-r:递归删除。
-f:不询问,强制删除。
/:系统的根目录。后面可以不加通配符*,也可以加。所以整个命令的意思很明确:强制递归删除根目录下所有文件!
#linux 复制多个文件夹下的文件到一个文件夹下面
for i in $(find ./aug_label/ -name \*.tif);do cp -rf $i ./newlabel/;done
for i in $(find ./aug_train/ -name \*.tif);do cp -rf $i ./newtrain/;done
for i in $(find ./train/ -name \*.tif);do cp -rf $i ./newtrain/;done
for i in $(find ./label/ -name \*.tif);do cp -rf $i ./newlabel/;done
#http://www.cnblogs.com/awinlei/archive/2013/02/05/2893292.html#批量重命名
for var in *.tif;do mv "$var" "${var%.tif}_train.tif";done
for var in *.tif;do mv "$var" "${var%.tif}_label.tif";done
#http://www.cnblogs.com/pangblog/p/3243931.html2.网络监控软件
bwm-ng
iptraf
iftopLinux流量监控软件bwm (支持64位系统)
Bandwidth Monitor NG (简称为 Bwm-NG)是一个简单的网络和磁盘带宽监视程序,可在Linux、BSD、Solaris等平台上运行。它支持各种各样的检测元件,用于收集各种统计数据,包括/proc/net/dev、netstat、getifaddr、sysctl、kstat、 /proc/diskstats /proc/partitions、 IOKit、 devstat 、 libstatgrab等。接口或设备可以黑白方式列示,这样用户就可以只查看感兴趣的数据。Bwm-NG支持多种输出选项,如图形、纯文本、CVS及 HTML等。查看流量命令:bwm-ng -d (按u键可切换流量单位)
看看会不会拿服务器被当”肉鸡”使用,检测这一问题的最好办法就是查看外面的流量出口,这时候我想到了iftop命令。
iftop是类似于top的实时流量监控工具。iftop可以用来监控网卡的实时流量(可以指定网段)、反向解析IP、显示端口信息等,详细的将会在后面的使用参数中说明。
sudo iftop -np 查看访问服务器的IP个数
netstat -pnt | grep :80
netstat -pnt | grep :80 | wc -l # IP个数IPTraf的是一个IP网络的网络监控工具。它截取网络上的数据包,并给出了当前的IP流量在它的各条信息。IPTraf的是一个纯软件的分析仪。它利用内置的原始数据包捕获的Linux内核,允许它被用于广泛的以太网卡,支持FDDI适配器,支持ISDN适配器,令牌环网,异步SLIP / PPP接口和其他网络设备的接口。不需要特殊的硬件要求。
# 查看有无异常进程
$ ps aux
#查看正运行的进程
ps -u username
# grep python的意思是过滤出跟python相关的进程
ps -aux | grep python
......
# 查看系统资源占用有无异常
$ top
......
# 有没有新增异常用户
$ cat /etc/passwd
......
#查看了root用户的命令历史记录,当然这个对稍有经验家伙是没有意义的,拿到了root权限后可以清理任何痕迹
# history
......3.打开文件夹
nautilus /home或者
xdg-open /home文件管理
file #确定文件类型,通过file指令,我们得以辨识该文件的类型
stat #文件信息文件内容显示
nl #(添加行号列印)
nl /etc/issue #用 nl 列出 /etc/issue 的内容
head #功能说明,显示先是文件的前几行(默认10行)。
head -n 5 syslog #可以指定显示的行数,用 -n 这个参数
head -20 test.sh #显示文件 test.sh前20行
tail #命令用于查看纯文本文档的后N行
tail -n 5 syslog #默认情况下,tail会显示文件的尾10行。可以指定显示的行数,用 -n 这个参数
head命令和tail命令:显示文件的开头和结尾
Less #功能说明,less 命令的功能几乎和 more 命令一样,也是用来按页显示文件,不同之处在于less 命令在显示文件时允许用户既可以向前又可以向后翻阅文件。
less命令:分页显示文件内容
less test.shless命令和cat命令之间最大的区别就是:less命令会分一页一页地显示文件内容,使我们可以方便地在终端里阅读。
more的缺陷就是它没有less那么强大,比如more命令虽然也是一页一页地显示文件,但是我们不能往后翻页,只能往前,“一路向北”.
less命令的好处是它会先读入文件开始的若干行,然后就停在那里,而这若干行的行数取决于终端屏幕的大小。这样的好处是我们可以有时间去渐进地读文件的内容。
less命令中最基本最常用的快捷键:
空格键:文件内容读取下一个终端屏幕的行数,相当于前进一个屏幕(页)。很常用的快捷键。与键盘上的PageDown(下一页)效果一样。
回车键:文件内容读取下一行,也就是前进一行。与键盘上的向下键效果是一样的。
d键:前进半页(半个屏幕)。
b键:后退一页。与键盘上的PageUp(上一页)效果一样。
y键:后退一行。与键盘上的向上键效果是一样的。
u键:后退半页(半个屏幕)。
q键:停止读取文件,中止less命令。less高级的快捷键
=号:显示你在文件中的什么位置(会显示当前页面的内容是文件中第几行到第几行,整个文件所含行数,所含字符数,整个文件所含字符)。
h键:显示帮助文档。按q键退出帮助文档。
/(斜杠):进入搜索模式,只要在斜杠后面输入你要搜索的文字,按下回车键,就会把所有符合的结果都标识出来。要在搜索所得结果中跳转,可以按n键(跳到下一个符合项目),N键(shift键+n。跳到上一个符合项目)。当然了,正则表达式(Regular Expression)也是可以用在搜索内容中的。
n键:跳到下一个符合的搜索结果。
N键:跳到上一个符合的搜索结果。文件显示总结
cat 由第一行开始显示內容
tac 从最后一行开始显示,可以看出 tac 是 cat 的到这写!
nl 显示的时候,顺道输出行号。
more 一页一页显示內容
less 与more 类似,但是比 more 更好的是,可以往前翻页!
head 只看头几行,默认前10行。
tail 只看尾巴几行。
od 以二进位的方式读取文档內容!文件查找
whereis #由一些特定的目录中寻找文件档名
whereis filename #快速查找某个文件
whereis ifconfig #请找出 ifconfig 这个档名
which #用于查找PATH路径下的某个命令是否存在
whatis #显示命令的简要描述,即会显示man手册页的第一行描述
find 目录 -name 文件名 locate命令,快速查找
locate是英语“定位”的意思。这个命令用于定位要查找的文件,而且此命令很快。
locate命令的用法也很直观,后接需要查找的文件名(当然也可以用正则表达式)。
例如我们来查找一个叫做 renamed_file的文件:
locate renamed_file文件的数据库
在使用locate命令查找文件时,大家可能会遇到这样的问题:我刚创建的文件,为什么用locate命令查找不到呢?
这正好是locate命令的缺陷,我正要说到:locate命令不会对你实际的整个硬盘进行查找,而是在文件的数据库里查找记录。
locate命令的原理如下图所示:
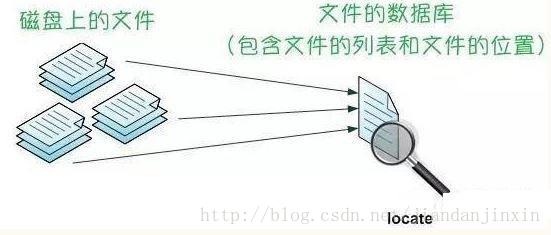
对于刚创建不久的文件,因为它们还没被收录进文件数据库,因此locate命令就找不到其索引,自然就不会返回任何结果。
可以用updatedb命令强制系统立即文件数据库。但是updatedb命令只能由root用户执行。
update是英语“更新”的意思。db是英语database的缩写,表示“数据库”。所以连起来就是“更新数据库”。
sudo updatedb查找软件安装位置及版本
dpkg -L firefox 查看软件firefox的安装路径。
dpkg -l firefox 查看软件firefox版本
apt-show-versions firefox 查看软件firefox版本
aptitude show firefoxfind命令详解
与locate命令不同,find命令不会在文件数据库中查找文件的记录,而是遍历你的实际硬盘。
所以,如果你的硬盘容量很大的话,那find命令会查找比较久。
find命令的原理如下图所示
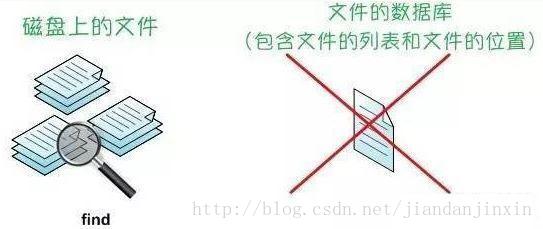
find命令的这种“耿直”的查找方式保证了我们不会遗漏一天之内创建的文件。
find命令的用法是这样的:
find 《何处》《何物》《做什么》1. 根据文件名查找
find -name "france1.jpg"这里,我们用-name参数指定了文件名字,是france1.jpg,用双引号括起来。不加双引号或者用单引号也是可以的。
假如,现在我位于我的家目录中,我却想在其他目录中进行查找,怎么办呢?
那就须要指定《何处》这个参数了。
例如,我要在/var/log目录下查找名为syslog的文件,我应该这么输入:
find /var/log "syslog"与locate命令不同的是,find命令只会查找完全符合《何物》的字符串表示的文件。locate会查找所有包含关键字的文件。比如,如果要用find来找thing这个文件,那么只会找到名字就是thing的文件;而locate命令会查找到比如thing,thing1,onething,twothings这样的文件。
可以用通配符:*(星号)来实现匹配多个名称。
例如,我要查找所有以syslog这个关键字开头的文件,可以这样来实现:
find /var/log -name "syslog*"那如果我要在整个硬盘里查找怎么做呢?很简单:
find / -name "syslog"在Linux的根目录查找很花时间,而且,如果你不是以root身份查找的话,就会有很多目录提示你“无权限访问”。
2. 根据文件大小查找
我们可以查找/var中大小超过10M的文件(当然你要以root身份):
find /var -size +10M这次,我们使用了-size参数,来指定查找文件的大小。size是英语“尺寸,大小”的意思。
后面紧跟的+10M表示大于10兆字节。
M是兆,也就是10的6次方;平时我们所说的Ko,Mo,Go其实分别是千字节,兆字节,千兆字节的意思。
如果我们要查找小于指定大小的文件,可以用减号。例如:
find /var -size -50K表示查找小于50Ko的文件。
3. 根据文件的最近访问时间查找
如果你记得你近7天里在家目录中访问过JPG格式的图片,但是你忘记它们的名字了,如何查找呢?
可以使用-atime参数。atime是access和time的缩写,access是英语“访问,进入”的意思,time是英语“时间”的意思。
find -name "*.jpg" -atime -7-atime参数后面紧跟的-7表示7天之内,减号的作用是表示小于。
4. 仅查找目录或文件
我们可以用-type参数来指定查找的文件类型。type是英语“类型”的意思。
-type d:只查找目录类型。d是directory的首字母,表示“目录”。
-type f:只查找文件类型。f是file的首字母,表示“文件”。如果不用-type参数指定类型,那么find命令默认是查找目录和文件的。比如说,有syslog这个文件,和syslog这个目录,那么find会把他们都查找出来。
find /var/log -name "mysql" -type dfind命令的高级用法:操作查找结果
当然了,默认地,find命令会显示每个查找到的文件。
事实上,
find -name "*.jpg"等价于
find -name "*.jpg" -print-print参数用于打印结果。print是英语“打印”的意思。
1.格式化打印查找结果
例如,我们可以这样打印查找到的内容:
find ~/Photos -name "*.jpg" -printf "%p - %u\n"printf是print formatted的缩写,表示“格式化打印”。
在-printf参数后面写了”%p - %u\n”,这个格式字符串的意思如下:
%p:文件名。
-:就是一个短横。
%u:文件的所有者,这里是小编的用户名,所以是bids。
\n:用于换行。可以看到,用法和C语言的printf函数很类似。
2.删除查找到的文件
假如我要删除查找到的文件,我可以用-delete参数。用法很简单:
find -name "*.jpg" -delete将会删除当前目录及其子目录下所有以.jpg为后缀的文件。而且不会有确认提示。所以慎用-delete参数。
3.调用命令
使用-exec参数,可以后接一个命令,对每个查找到的文件进行操作。
exec是execute的缩写,是英语“执行”的意思。
假设我想要将当前目录下所有查找到的JPG文件的访问权限都改为600,那么我们可以这样做:
find -name "*.jpg" -exec chmod 600 {} \;就是说对于每个找到的.jpg结尾的文件,都进行-exec参数指定的操作:
这个操作不必用双引号括起来。
{} 会用查找到的每个文件来替换。
\; 是必须的结尾。虽然-exec参数一开始有点看不懂其用法,但是慢慢地你会发现,这个参数太强大了,你可以对查找到的文件做任何你想要的操作。
如果你对于没有确认提示不太放心,你可以将-exec参数换成-ok参数,用法一样,只不过-ok参数会对每一个查找到的文件都做确认提示,输入y加回车表示对此文件进行此操作;输入n加回车表示对此文件不进行此操作。
与时间有关的选项:共有 -atime, -ctime 与 -mtime ,以 -mtime 说明
-mtime n :n 为数字,意义为在 n 天之前的『一天之内』被更动过内容的文件;
-mtime +n :列出在 n 天之前(不含 n 天本身)被更动过内容的文件档名;
-mtime -n :列出在 n 天之内(含 n 天本身)被更动过内容的文件档名。
-newer file :file 为一个存在的文件,列出比 file 还要新的文件档名
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为’command’ { } \;,注意{ }和\;之间的空格。
find / -mtime 0 # 那个 0 是重点!0 代表目前的时间,所以,从现在开始到 24 小时前。将过去系统上面 24 小时内有更动过内容 (mtime) 的文件列出
find / -mtime 3 #有变动过的文件都被列出。# 有变动过内容的文件都会被列出来!那如果是三天前的 24 小时内?
find /etc -newer /etc/passwd #寻找 /etc 底下的文件,如果文件日期比 /etc/passwd 新就列出
# -newer 用在分辨两个文件之间的新旧关係是很有用的!
find /home -user dmtsai #搜寻 /home 底下属于 dmtsai 的文件\# 这个东西也很有用的~当我们要找出任何一个使用者在系统当中的所有文件时,
# 就可以利用这个指令将属于某个使用者的所有文件都找出来喔!
find / -nouser #搜寻系统中不属于任何人的文件
# 透过这个指令,可以轻易的就找出那些不太正常的文件。如果有找到不属于系统任何人的文件时,# 不要太紧张,那有时候是正常的,尤其是你曾经以原始码自行编译软体时。
find / -name passw #找出档名包含了 passwd 这个关键字的文件
find / -name "*passwd*" # 利用这个 -name 可以搜寻档名啊!预设是完整档名,如果想要找关键字,可以使用类似 * 的任意字元来处理
4.tree 查看目录树
tree /pstree #可以很直接的看到相同的进程数量,最主要的还是我们可以看到所有进程的之间的相关性。5.清空当前终端的所有输入输出显示记录
reset
或者
ctrl + L6.进入上一目录
cd指令可让用户在不同的目录间切换,但该用户必须拥有足够的权限进入目的
cd ..
cd -7.显示CPU信息
less /proc/cpuinfo 或者 lscpu 8.显示内存信息
less /proc/meminfo9.yes 是一个非常有趣又有用的命令,尤其对于脚本编写和系统管理员来说,它可以自动地生成预先定义的响应或者将其传到终端。
yes I LoveLinux提示: (直到你按下ctrl+c才停止)
————————————————————————–
————————————————————————–
————————————————————————–
————————————————————————–
10.sl (Steam Locomotive)蒸汽机
sl,然后一辆火车来开过
当你敲入的是‘LS‘而不是’ls‘时,这个命令也会运行。
sl -F飞起来的火车
ls #列出目录内容。执行ls指令可列出目录的内容,包括文件和子目录的名称。
ls -l #每列仅显示一个文件或目录名称。
ls -lh #来更直观的查看文件的大小
ll #以详细方式显示所有文件与文件夹。(相当于 ls -l 命令)
ls -sS #小 s 为显示文件大小,大 S 为按文件大小排序
ls -a或--all #列出所有文件和目录
ls -i #列出 inode 号码
ls -F #查看目前存在文件夹中的文件
ls -A #显示除了 .(当前目录)和 ..(上一级目录)之外的所有文件,包括隐藏文件
ls -a #查看文件包括隐藏文件dir #功能说明,列出<文件>的信息 (默认为目前的目录)
dir -l 11.Telnet 是一个文本化的双向网络协议
telnet towel.blinkenlights.nl12.Fortune命令是在相同命令行中作为fortune cookies。我们运行这个命令的时候随机找了一条谚语或信息。依靠这个命令,Linux可以像个算命师一样。
13.一个在终端用ASCII码组成的小牛,这个小牛会说出你想要它说的话。
cowsay I Love nix cowthink是另一个命令。运行“cowthink Linux is sooo funny ”看看它与cowsay的不同吧。
cowthink Linux is sooo funnyxcowsay是一个图形界面程序。它与cowsay类似只是以一种图形的方式来表达,可以说是X版本的cowsay
xcowsay I Love Linuxxcowthink是另一个命令。运行“xcowthink Linux is sooo funny ”看看它与xcowsay的不同吧。
xcowthink Linux is sooo funny14.如果用管道将‘fortune command’命令重定向到xcowsay会怎样呢?
fortune | xcowsay提示:‘|’是管道命令符。通常它是将一个命令的输出作为下一个命令的输入。在上面的例子中‘fortune’的输出作为‘xcowsay’命令的输出。管道命令会经常用在脚本和程序编写中。
尽管这个命令中只出现了cow,但其实它还可以有羊的效果。
cowsay -f sheep "I too love linux"只需用 ‘-l 就能看到它能提供的所有动物。输入:
cowsay -l为了使之更有趣,你可以让cowsay说出fortune信息,如输入:
fortune | cowsay -f hellokitty15.你可能看多好莱坞的电影‘黑客帝国’并陶醉于被赋予Neo的能看到在矩阵中任何事物的能力,或者你会想到一幅类似于‘Hacker’的桌面的生动画面。
cmatrix16.可能你坚信Linux的鼠标指针永远是同样的黑色或白色一点儿也不生动,那你就错了。“oneko”是一个会让一个“Jerry”你的鼠标指针附着到你鼠标上的一个软件包。
oneko提示:关闭运行着oneko的终端时,Jerry也会随之消失,重新启动终端时也不会再出项。你可以将这个程序添加到启动选项中然后继续使用它。
17.将你的多媒体音箱的音量调到最大,然后在将这个命令复制到你的终端,来看看你听到上帝的声音时的反应吧。
espeak "Tecmint is a very good website dedicated to Foss Community"18.在你的终端放一把火如何。把这个“aafire”敲到你的终端,不需要什么引号看看这神奇的一幕吧。按下任意键中指该程序。
aafire19.首先安装“apt-get install bb”,然后敲入“bb”看看会发生什么吧
ASCIIquarium
这真是一个不可思议的杰作,你的linux终端窗口竟然成了水族馆,里面有水,有石、有鱼、有兽。不多说,自己欣赏一下吧。
apt-get install libcurses-perl
cd /tmp
wget http://search.cpan.org/CPAN/authors/id/K/KB/KBAUCOM/Term-Animation-2.4.tar.gz
tar -zxvf Term-Animation-2.4.tar.gz
cd Term-Animation-2.4/
perl Makefile.PL && make && make test
sudo make install安装ASCIIquarium
~# cd /tmp
~# wget http://www.robobunny.com/projects/asciiquarium/asciiquarium.tar.gz
~# tar -zxvf asciiquarium.tar.gz
~# cd asciiquarium_1.1/
~# cp asciiquarium /usr/local/bin
~# chmod 0755 /usr/local/bin/asciiquarium执行效果
~# asciiquarium
命令:factor
该谈点儿关于Mathematics的了,这个命令输出给定数字的所有因子
命令:while
下面的”while“命令是一个脚本,这个脚本可以为你提供彩色的日期和文件直到你按下中断键(ctrl+c)。复制粘贴这个命令到你的终端。
while true; do echo "$(date '+%D %T' | toilet -f term -F border --gay)"; sleep 1; done提示:以上脚本通过下面的修改也会产生类似的输出但是还是有点不同的,在你的终端试试吧。
while true; do clear; echo "$(date '+%D %T' | toilet -f term -F border --gay)"; sleep 1; done20.命令行百科
首先安装“apt-get install funny-manpages”然后运行下面命令的man手册。其中一些
baby
celibacy
condom
date 命令用于显示/设置系统的时间或日期
echo
flame
flog
gong
grope, egrope, fgrope
party
rescrog
rm
rtfm
tm
uubp
woman (undocumented)
xkill
xlart
sex
strfry
man baby21.这个命令会用大写方式把我们输入的字符串显示在标题栏,显示效果由ASCII字符组成。
由于它不是标准设置,所以要先安装这一功能。
figlet mylinuxbook22.它比figlet命令的效果更有艺术感。
toilet mylinuxbook不过,它还可以添加颜色。我们可以运行下列命令看到颜色:
toilet -f mono12 -F metal mylinuxbook23.执行xeyes会在屏幕上出现一双大眼睛,而且眼珠会跟随你的鼠标转动。
xeyes————————————————————————–
————————————————————————–
————————————————————————–
————————————————————————–
24.把传递给它的的每个字符串都反过来
revSpace Invaders:太空侵略者
使用下面这个命令可以安装,之所以叫 ninvaders 是因为这款游戏是基于 ncurses 命令行图形库做的:
sudo apt-get install ninvaders25.命令行编辑错误,如何修改
重新输入,然后执行
稍加编辑,再来执行
使用 ^ 删掉多余部分
% grep fooo /var/log/auth.log
% ^o
% grep foo /var/log/auth.log使用 ^old^new 换掉输错或输少的部分
% cat myflie
% ^li^il
% cat myfile
% ansible vod -m command -a 'uptim'
% ^im^ime
% ansible vod -m command -a 'uptime'使用 !:gs/old/new 将 old 全部换成 new
% ansible nginx -m command -a 'which nginx'
% !:gs/nginx/squid
% ansible squid -m command -a 'which squid'
% ^nginx^squid^:G # zsh要记住的是:
一删 使用 ^ 删掉多余部分
二换 使用 ^old^new 换掉输错或输少的部分
三全变 使用 !:gs/old/new 将 old 全部换成 new
利用 :s 做替换
% echo this that
% !:s/is/e
echo the that惯用法: ^is^e
利用 :gs 做全局操作
% echo abcd abef
% !:gs/ab/cd
echo cdcd cdef
cdcd cdef26.历史记录命令
了解历史记录的大小
echo $HISTSIZE历史记录的保存位置
echo $HISTFILE历史记录的保存大小
echo $HISTFILESIZE # bash
或者
echo $SAVEHIST # zsh查看历史
history
history | less
history 5查看系统默认保存历史命令记录条数
echo $HISTSIZE
~/.bash_history #注销系统,那么会将所有的历史命令都存入到这里,只有1000条的默认记录修改Linux中history命令保存条数
sudo gedit ~/.bashrc
shopt-s histappend
HISTSIZE=100000
HISTFILESIZE=1000000设置命令历史记录的时间(临时生效)
sudo gedit /etc/profile
export HISTTIMEFORMAT='%F %T' #注意有个空格,为了显示时日期与命令之间有空格分割。
source /etc/profile #命令生效
history设置命令历史记录的时间永久生效
history
sudo gedit /etc/bash.bashrc
export HISTTIMEFORMAT='%F %T'
export HISTFILESIZE=1000000
source /etc/bash.bashrc
history使用 Ctrl + r 逆向搜索历史命令
(reverse-i-search)`h': history 5使用 Ctrl + p 访问上一条命令
history >> recordhistory.txt # 将历史命令记录输出到recordhistory.txt 文件里面参考文献:
http://superuser.com/questions/137438/how-to-unlimited-bash-shell-history
http://blog.itpub.net/29306197/viewspace-1062708/
http://askubuntu.com/questions/307541/how-to-change-history-size-for-ever/690870
27. 历史引用
使用 !! 执行上一条命令
% !!
% sudo !!
例子
% apt-get install figlet
E: Could not open lock file /var/lib/dpkg/lock - open (13: Permission denied)
E: Unable to lock the administration directory (/var/lib/dpkg/), are you root?
% sudo !!
sudo apt-get install figletsudo是英语Substitute User DO的缩写,substitute是“替换,代替,替身”的意思,user是“用户”的意思,do就是“做”的意思。所以连在一起就是“替换用户来执行…”的意思。
sudo su #一直成为root
su - #成为root,并直接定位到root的家目录使用 !foo 执行以 foo 开头的命令
% !his
history使用 !?foo 执行包含 foo 的命令
% !?is
echo $histchars使用 !n 执行第 n 个命令
% !10
vim lib/TunePage.pm使用 !-n 执行倒数第 n 个命令
% !-2
htop
关于历史引用,要记住的是:
!! 执行上一条命令
![?]字符串 执行以字符串开头的命令或执行【包含】字符串的命令
![-]数字 执行正数【倒数】第 n 个命令
!# 引用当前行28.word选取
通过 !$ 得到上一条命令的最后一位参数
% mkdir videos
% cd !$通过 !^ 得到上一条命令的第一个参数
% ls /usr/share/doc /usr/share/man
% cd !^通过 !:n 得到上一条命令第 n 个参数
touch foo.txt bar.txt baz.txt
% vim !:2
vim bar.txt通过 !:x-y 得到上一条命令从 x 到 y 的参数
% touch foo.txt bar.txt baz.txt
% vim !:1-2
vim foo.txt bar.txt通过 !:n* 得到上一条命令从 n 开始到最后的参数
% cat /etc/resolv.conf /etc/hosts /etc/hostname
% vim !:2*
vim /etc/hosts /etc/hostname通过 !* 得到上一条命令的所有参数
% ls code src
% cp -r !*关于 Word 选取,要记住的是:
!:n,得到上一条命令第 n 个参数
^|$ 得到上一条命令的第一个参数,得到上一条命令的最后一位参数
[n]* 得到上一条命令从 n 开始到最后的参数
x-y 得到上一条命令从 x 到 y 的参数29.关于修饰符
利用 :h 选取路径开头
% ls /usr/share/fonts/truetype
% cd !$:h
cd /usr/share/fonts利用 :t 选取路径结尾
% wget http://nginx.org/download/nginx-1.4.7.tar.gz
% tar zxvf !$:t
tar zxvf nginx-1.4.7.tar.gz利用 :r 选取文件名
% unzip filename.zip
% cd !$:r
cd filename利用 :e 选取扩展名
% echo abc.jpg
% echo !$:e**重点内容**
echo .jpg # bash
.jpg
echo jpg # zsh
jpg利用 :p 打印命令行
% echo *
% !:p
echo *利用 :s 做替换
% echo this that
% !:s/is/e
echo the that惯用法: ^is^e
利用 :gs 做全局操作
% echo abcd abef
% !:gs/ab/cd
echo cdcd cdef
cdcd cdef利用 :u 将其更改为大写 (zsh)
% echo $histchars
% echo !$:u
echo $HISTCHARS利用 :l 将其更改为小写 (zsh)
% echo !$:l
echo $histchars关于修饰符,要记住的是:
h|t 选取路径开头,选取路径结尾
r|e 选取文件名,选取扩展名
p 打印
s 替换
g 全部替换
u|l
30.guake:半透明的,F12一键弹出,又酷炫又方便
31.choco,可能是三大平台最牛逼的包管理器之一
32.watch 可以帮你监测一个命令的运行结果,省得你一遍遍的手动运行。
在Linux下,watch是周期性的执行下个程序,并全屏显示执行结果。
-d, –differences[=cumulative] 高亮显示变动
-n, –interval=<seconds> 周期(秒)
如:watch -n 1 -d netstat -ant可以拿他来监测你想要的一切命令的结果变化,比如 tail 一个 log 文件,ls 监测某个文件的大小变化。
watch允许你偷看其它terminal正在做什么,该命令只能让超级用户使用。
watch -n 10 uptime #来每秒刷新一次获得当前的系统负载情况,每10秒输出一次系统负载情况33.命令行浏览器
w3m
elinks
—————————————————————————————
下面给出Linux检测的一些常用命令
详情见 https://www.91ri.org/14906.html
—————————————————————————————
34.审计命令
(1)last:这个命令可用于查看我们系统的成功登录、关机、重启等情况;这个命令就是将/var/log/wtmp文件格式化输出。
(2)lastb:这个命令用于查看登录失败的情况;这个命令就是将/var/log/btmp文件格式化输出
(3)lastlog:这个命令用于查看用户上一次的登录情况;这个命令就是将/var/log/lastlog文件格式化输出。
(4)who:这个命令用户查看当前登录系统的情况;这个命令就是将/var/log/utmp文件格式化输出。
(5)w:与who命令一致。
关于它们的使用:man last,last与lastb命令使用方法类似
(6)查看访问服务器的IP个数
netstat -pnt | grep :80
netstat -pnt | grep :80 | wc -l # IP个数last 命令参数
-a 把从何处登入系统的主机名称或ip地址,显示在最后一行。
-d 指定记录文件。指定记录文件。将IP地址转换成主机名称。
-f <记录文件> 指定记录文件。
-n <显示列数>或-<显示列数> 设置列出名单的显示列数。
-R 不显示登入系统的主机名称或IP地址。
-x 显示系统关机,重新开机,以及执行等级的改变等信息以下看所有的重启、关机记录
last | grep reboot
last | grep shutdownlast | more #查看谁登录了服务器35.日志查看
cat 功能说明
cat命令:一次性显示文件的所有内容
把档案串连接后传到基本输出(屏幕或加 >filename 到另一个档案)
cat 来看比较小的文件的内容
cat -n syslog #在显示的文件内容上加上行号syslog由sys和log组成,sys是system的缩写,是英语“系统”的意思;log就是log,是英语“日志”的意思。
系统所有的日志都在 /var/log 下面自己看(具体用途可以自己查,附录列出一些常用的日志)
cat /var/log/syslog
cat /var/log/*.logcat
-b : 指定添加行号的方式,主要有两种:
-b a:表示无论是否为空行,同样列出行号("cat -n"就是这种方式)
-b t:只列出非空行的编号并列出(默认为这种方式)
-n : 设置行号的样式,主要有三种:
-n ln:在行号字段最左端显示
-n rn:在行号字段最右边显示,且不加 0
-n rz:在行号字段最右边显示,且加 0
-w : 行号字段占用的位数(默认为 6 位)
tail 查看文件的后N行,有实时监控的功能。
如果日志在更新,如何实时查看
tail -f /var/log/messages
参数-f使tail不停地去读最新的内容,这样有实时监视的效果,用Ctrl+c来终止
#tail命令还可以配合 -f 参数来实时追踪文件的更新:
tail -f syslog
#这样,就会检查文件syslog是否有追加内容,如果有,就显示新增内容。
#tail -f会每过1秒检查一下文件是否有新内容。可以指定间隔检查的秒数,用 -s 参数
tail -f -s 4 syslog #每隔4秒检查一次文件是否有更新
tail -f -s 2.5 syslog #每隔2.5秒检查一次文件是否有更新
#或者
watch -d -n 1 cat /var/log/messages事实上,Ctrl + c这个组合快捷键(同时按下)可以终止大部分终端的命令和正在执行的程序,有点类似Windows中的Alt + F4
linux日志文件说明
/var/log/message 系统启动后的信息和错误日志
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件日志名称 记录信息
alternatives.log 系统的一些更新替代信息记录
apport.log 应用程序崩溃信息记录
apt/history.log 使用apt-get安装卸载软件的信息记录
apt/term.log 使用apt-get时的具体操作,如 package 的下载打开等
auth.log 登录认证的信息记录
boot.log 系统启动时的程序服务的日志信息
btmp 错误登陆的信息记录
Consolekit/history 控制台的信息记录
dist-upgrade dist-upgrade这种更新方式的信息记录
dmesg 启动时,显示屏幕上内核缓冲信息,与硬件有关的信息
----------
dpkg.log dpkg命令管理包的日志。
dpkg -L firefox 查看软件firefox的安装路径。
dpkg -l firefox 查看软件firefox版本
apt-show-versions firefox 查看软件firefox版本
aptitude show firefox
---------
faillog 用户登录失败详细信息记录
fontconfig.log 与字体配置有关的信息记录
kern.log 内核产生的信息记录,在自己修改内核时有很大帮助
lastlog 用户的最近信息记录
wtmp 登录信息的记录。wtmp可以找出谁正在登陆进入系统,谁使用命令显示这个文件或信息等
syslog 系统信息记录–
36.Linux集中日志服务器rsyslog
更多日志信息 可查看
ubuntu 15.04 /var/log/下各个日志文件及修复无message文件和debug文件
37.用户查看命令
所有用户都会在/etc/passwd /etc/shadow /etc/group /etc/group- 文件中记录
less /etc/passwd:查看是否有新增用户
grep :0 /etc/passwd:查看是否有特权用户(root权限用户)
ls -l /etc/passwd:查看passwd最后修改时间
awk -F: ‘$3==0 {print $1}’ /etc/passwd:查看是否存在特权用户
awk -F: ‘length($2)==0 {print $1}’ /etc/shadow:查看是否存在空口令用户38.进程查看
普通进程查看进程中我们一般使用ps来查看进程;man ps
ps是Process Status的缩写,process是英语《进程》的意思,status是《状态》的意思,所以ps命令用于显示当前系统中的进程。
查看正运行的进程
ps -u username
PID:进程号。pid是process identifier的缩写。每个进程有唯一的进程号。之后我们学习如何结束进程时需要用到进程号。
TTY:进程运行所在的终端。
TIME:进程运行了多久。
CMD:产生这个进程的程序名。如果你在进程列表中看到有好几行都是同样的程序名,那么就是同样的程序产生了不止一个进程(例如MySQL程序)。
ps -u 用户名:列出此用户运行的进程
ps -u newname #列出用户newname的所有进程ps -a #查看当前用户正在进行的任务。ps -aux #查看进程,进程快照。ps(process status)命令用来列出系统中当前运行的那些进程。ps命令列出的是当前那些进程的快照,就是执行ps命令的那个时刻的那些进程。为我们提供了进程的一次性的查看,它所提供的查看结果并不动态连续的。
ps -aux | grep searchd #查询进程是否开启(这里以search为例)
lsof -p pid #查看进程所打开的端口及文件
ps -ef #查看所有进程
ps -ef | grep redis #查看redis进程是否存在检查隐藏进程
ps -ef | awk ‘{print }’ | sort -n | uniq >1
ls /proc | sort -n |uniq >2
diff 1 2关闭进程
kill 进程号(就是ps -A中的第一列的数字)或者 killall 进程名( 杀死一个进程)
kill 进程号
kill -9 进程号 #强制杀死一个进程 Linux中终止某个用户的所有进程
1. pkill方式
# pkill -u ttlsa
2. killall方式
# killall -u ttlsa
3. ps方式
ps列出ttlsa的pid,然后依次kill掉,比较繁琐.
# ps -ef | grep ttlsa | awk '{ print $2 }' | sudo xargs kill -9
4. pgrep方式
pgrep -u参数查出用户的所有pid,然后依次kill
# pgrep -u ttlsa | sudo xargs kill -9
#终止某个程序的进程
5. pkill -f "tensorboard"—————————————————————————————
39.etc
cat /etc/passwd | more # 查看密码文件的内容并具有分页的功能
cat /etc/shadow | more # 记录所有的登陆密码40.简单命令
data #显示日期
cal#显示日历
cal 1998 # 查看1998年的所有日历
who #查看谁在使用系统
-------
USER:用户名(登录名)。user是英语“用户”的意思。
TTY:Linux中默认提供了六个命令行终端和一个图形终端:tty1~tty7。其中tty1~tty6是命令行终端(就是全屏,黑底白字的控制台,以前的Linux探索之旅 | 第二部分第一课:终端Terminal,好戏上场这一课介绍过),tty7是图形终端(也就是平时我们启动Ubuntu桌面版时默认登录的图形用户界面,也是全屏的)。Ubuntu中可以通过Ctrl+Alt+F1~F7切换这7个终端。除了这7个基本的《大环境》终端,我们还可以在tty7中开很多不是全屏的终端,也就是我们平时用来输入命令行的图形终端(ctrl + shift + T快捷键),这些终端的名字是以pts开头的。pts是pseudo terminal slave的缩写,表示“伪终端从属”。如果我新开一个图形终端,那么显示名称为pts/0,如上图中所示。如果我再开一个图形终端,那么它的名字就是pts/1。依次类推。
FROM:用户连接到的服务器的IP地址(或者主机名)。在我们的例子中,我们并没有登录远程服务器,只是在本地自己的电脑上测试,所以FROM那列显示的并不是实际的IP地址。from是英语“从...”的意思
LOGIN@:用户连接系统的时间。login是英语“登录”的意思。
IDLE:用户有多久没活跃了(没运行任何命令)。idle是英语“不活跃的”的意思。
WHAT:当下用户正运行的程序。what是英语“什么”的意思。
-----
clear #清除屏幕
ctrl + L #清除屏幕
reset #清除屏幕
bc # 计算器
ctrl + c #中断前台进程
ctrl + d #结束符
yes #多次打印字符串41.Linux主要目录结构
/etc # 存放Linux系统管理中的各种配置文件和子目录
/sbin # 存放系统管理员的系统管理程序
/dev # 存放系统所使用的各种外设(外设入口文件)
/bin # 系统常用命令(内部命令),bin是Binary的缩写。存放最常使用的命令。
/boot # 系统启动时所使用的各种文件,包括一些连接文件以及镜像文件。
/lib # 存放系统中的共享动态连接库
/proc #存放系统信息文件,与内存映像
/root #root用户的主目录
/home #该目录下存放了各个用户的工作目录
/usr # 存放系统应用程序(可以说是外围工具、程序或命令);/usr/bin; /usr/lib;/usr/include跟开发相关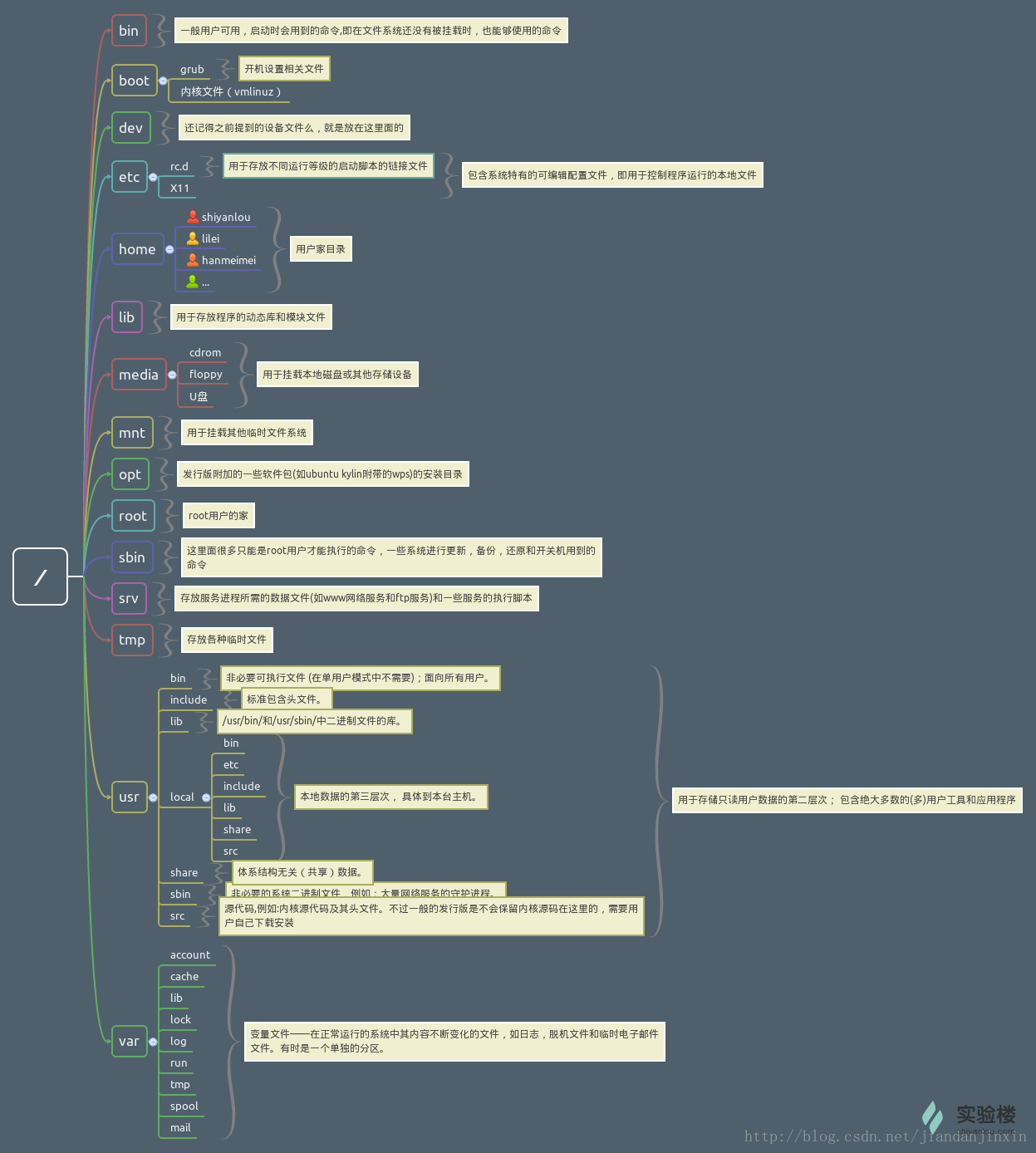
试试最真实最直观的方式,执行如下命令:
$ tree /42.管理命令
磁盘和分区
df # 磁盘的使用状况
df -h # 直观显示,查看当前磁盘使用情况, 包括占用量单位。显示以MB,KB为单位
du用于显示当前一个文件或者目录占用的磁盘空间(单位kb)
du file.txtdu -s #显示当前目录下文件大小的总和 # mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况43.文件权限
44.find
find 命令格式
find pathname -expression
find # 若省略,则等同于下命令
find . -print
find . -name 'mini*'
find . -name 'mini*' -print45.wget
wget命令行工具是从网站负责所有html文件,并储存在本地硬盘上。
命令格式:
wget [参数] [URL地址]继续中断的下载
要继续一个中断的下载,只要在相同的下载命令中加入 -c 参数,例如:
wget -c http://cdimage.debian.org/debian-cd/8.6.0/i386/iso-cd/debian-8.6.0-i386-netinst.isoc是英语continue的缩写,表示“继续”。
wget的一个优点是会显示下载的进度。ftp命令则不会显示下载进度。
56.Linux重启命令
shutdown #关机
shutdown -h now #立刻挂机,其中now相当于时间为0的状态
shutdown -h 20:25 #系统在今天的20:25分会关机。若在21:25下达此命令,则隔天才关机。
shutdown -h +10 #系统再过十分钟后自动关机
shutdown -r now #系统立刻重新启动。
shutdown -r +30 #系统再过三十分钟会重新启动。
poweroff
init
reboot #重启
reboot Init 6 #重启LINUX系统
halt #关机shutdown命令安全地将系统关机。
在系统关机前使用shutdown命令﹐系统管理员会通知所有登录的用户系统将要关闭。并且login指令会被冻结﹐即新的用户不能再登录。直接关机或者延迟一定的时间才关机都是可能的﹐还可能重启。这是由所有进程〔process〕都会收到系统所送达的信号〔signal〕决定的。 shutdown执行它的工作是送信号〔signal〕给init程序﹐要求它改变runlevel。Runlevel 0被用来停机〔halt〕﹐runlevel 6是用来重新激活〔reboot〕系统。
shutdown 参数说明:
[-t] 在改变到其它runlevel之前﹐告诉init多久以后关机。
[-r] 重启计算器。
[-k] 并不真正关机﹐只是送警告信号给
每位登录者〔login〕。
[-h] 关机后关闭电源〔halt〕。
[-n] 不用init﹐而是自己来关机。不鼓励使用这个选项﹐而且该选项所产生的后果往往不总是你所预期得到的。
[-c] cancel current process取消目前正在执行的关机程序。所以这个选项当然没有时间参数﹐但是可以输入一个用来解释的讯息
﹐而这信息将会送到每位使用者。
[-f] 在重启计算器〔reboot〕时忽略fsck。
[-F] 在重启计算器〔reboot〕时强迫fsck。
[-time] 设定关机〔shutdown〕前的时间。halt—-最简单的关机命令,其实halt就是调用shutdown -h。halt执行时﹐杀死应用进程﹐执行sync系统调用﹐文件系统写操作完成后就会停止内核。
reboot的工作过程差不多跟halt一样﹐不过它是引发主机重启﹐而halt是关机。
init是所有进程的祖先﹐它的进程号始终为1﹐所以发送TERM信号给init会终止所有的 用户进程﹑守护进程等。
56.硬链接与软连接
ln命令:创建链接
ln是link的缩写,在英语中表示“链接”。所以ln命令用于在文件之间创建链接。说起链接可能你比较陌生,那么为了简单起见,我们用一个你比较熟悉的词好了:快捷方式。
Linux下有两种链接类型:
Physical link:物理链接或硬链接。
Symbolic link:符号链接或软连接。文件的存储
在硬盘上存储时,每个文件有三部分:
文件名
权限
文件内容每个文件的文件内容被分配到一个标示号码,就是inode。因此每个文件名都绑定到它的文件内容(用inode标识),原理如下图:
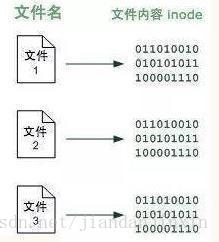
创建硬链接
硬链接的原理:使链接的两个文件共享同样的文件内容,也就是同样的inode。
所以一旦文件1和文件2之间有了硬链接,那么你修改文件1或文件2,其实修改的是相同的一块内容。只不过我们可以用两个文件名来取到文件内容。
硬链接有一个缺陷:只能创建指向文件的硬链接,不能创建指向目录的硬链接。但是软链接可以指向文件或目录。所以对于目录的链接,我们一般都是用软链接。
ln file1 file2 #创建了file1的一个硬链接file2可以用ls -i命令查看一下(-i参数可以显示文件的inode)。我们可以看到file1和file2的inode是一样的
硬链接原理图:
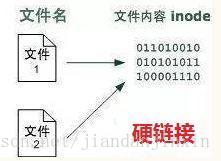
上图中,我们看到,file2是新生成的硬链接,它指向file1的文件内容,也就是说它们共享相同的文件内容,也就是拥有同一个inode。
创建软链接
创建硬链接是ln不带任何参数,但是要创建软链接需要加上-s参数。s是symbolic(符号的)的缩写。
ln -s file1 file2以上命令创建了file1的软链接file2
软链接原理图:
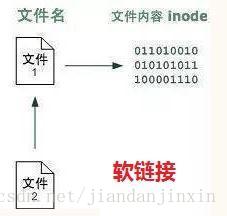
可以看到上图中,file2指向的不再是file1的文件内容(和硬链接不同),而是指向file1的文件名。
用ls -l命令查看一下,会发现形式和之前的硬链接不一样噢,file2的信息是这样的: file2->file1,表示file2指向file1。
ln #创建软/硬链接 ,软链接也叫符号链接。
ln -s #创建软链接,需要加一个参数 -s,软链接可以理解为快捷方式
ln #语法
ln [-bdfinsv][-S <字尾备份字符串>][-V <备份方式>][--help][--version][源文件或目录][目标文件或目录]
或 ln [-bdfinsv][-S <字尾备份字符串>][-V <备份方式>][--help][--version][源文件或目录...][目的目录]
ln -s /home/Fiji/imagej-linux64 /usr/bin/imagej # 将imagej-linux64 软连接到 /usr/bin/imagej, 这样就可以在命令终端直接打开imagej了。
补充说明
ln指令用在连接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。
若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。
57.系统信息查询
uname -a 查看内核版本
head -n 1 /etc/issue # 查看操作系统版本
cat /proc/cpuinfo # 查看CPU信息
hostname # 查看计算机名
iostat: CPU 和硬盘状态
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量
lsblk #列出块设备信息: 以树形展示你的磁盘以及磁盘分区信息
lscpu,lspci 和 dmidecode #查看包括 CPU、BIOS、RAID、显卡等
lshw #查看当前硬件信息
lsusb #查看usb设备
free - m #显示空闲的、已用的物理内存及swap内存,及被内核使用的buffer.
htop
top #显示当前系统中消耗资源的进程情况
top -d 2 #每隔2秒刷新,每隔2秒显示徐偶有进程的资源占用情况
top -p id #单独查看某个进程的具体信息
top -p processId #显示某一进程实时耗用的资源
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况。
敲击键盘“b”(打开/关闭加亮效果),top的视图变化。
top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
q:退出top
h:显示帮助文档,也就是哪些按键可以使用。按下任意键返回。
B:大写的B,加粗某些信息。
f:在进程列表中添加或删除某些列。
F:改变进程列表排序所参照的列。默认情况下,是按照%CPU那一列来排序。
u:依照用户来过滤显示。可以输入用户名,按回车。
k:结束某个进程。会让你输入要结束的进程的PID。
s:改变刷新页面的时间。默认地,页面每隔3秒刷新一次。
vmstat #查看虚拟内存Virtual Meomory Statistics.
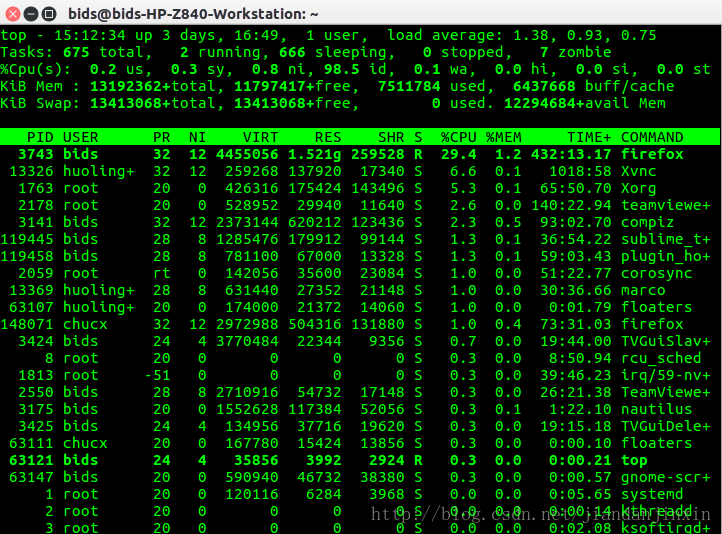
第一行:
15:12:34 — 当前系统时间
3 days, 16:49 — 系统已经运行了3天16小时49分钟
1 users — 当前有1个用户登录系统
load average: 1.38, 0.93, 0.75 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
第二行:
Tasks — 任务(进程),系统现在共有675个进程,其中处于运行中的有2个,666个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有7个。
第三行:cpu状态
0.2% us — 用户空间占用CPU的百分比。
0.3% sy — 内核空间占用CPU的百分比。
0.8% ni — 改变过优先级的进程占用CPU的百分比
98.5% id — 空闲CPU百分比
0.1% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态
13192362 total — 物理内存总量
7511784 used — 使用中的内存总量
11797417 free — 空闲内存总量
6437668 buffers — 缓存的内存量
第五行:swap交换分区
13413068 total — 交换区总量
0 used — 使用的交换区总量
13413068 free — 空闲交换区总量
12294684 cached — 缓冲的交换区总量
UID 进程所属用户的ID,即哪个用户创建了该进程
第七行以下:各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者父进程ID
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒,进程使用CPU的时间
COMMAND — 进程名称(命令名/命令行)
STIME 进程被创建的时间
TTY 与进程有关的终端类型,该 process 是在那个终端机上面运作,若与终端机无关,则显示 ? (关于pts/ tty/ 暂时还不明白)
CMD 创建该进程的命令
58.监控
w #查看处于登录状态的用户
id #用户/组 ID 信息,显示用户身份号
finger #用来查询一台主机上的登录账号的信息,通常会显示用户名、主目录、停滞时间、登录时间、登录Shell等信息,使用权限为所有用户系统正常运行时间一般就称为uptime,Linux中有一个uptime命令可以显示
uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载uptime在w命令的输出的第一行的右边,有三个数值,表示负载:
load average: 0.15, 0.11, 0.09
load是《负载,负荷》的意思,average是《平均值》的意思。负载是系统活动的一个指标:
这三个数值从左到右分别表示:
1分钟以内的平均负载(0.15)。
5分钟之内的平均负载(0.11)。
15分钟之内的平均负载(0.09)这些数值表示一段时间内的平均活跃进程数(也就是使用CPU处理器的进程数。进程简单地说就是运行起来的程序)。
由此可知,近1分钟内平均有0.15个进程使用了处理器,也就是说处理器有15%的时间是活跃的。
负载的数值也取决于电脑的处理器的核心数目。一个单核的处理器如果负载超过了1,那就是过载了。双核的处理器如果负载超过了2,那就是过载了。四核的处理器如果负载超过了4,那就是过载。依次类推。
网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息ip
ifconfig
--------
ifconfig eth0 192.168.120.56 netmask 255.255.255.0 broadcast 192.168.120.255
上面的命令用于给eth0网卡配置IP地址(192.168.120.56),加上子网掩码(255.255.255.0),加上个广播地址(192.168.120.255)。
-------
-------
dig
netstat -lntp # 查看所有监听端口
netstat -antp # 查看所有已经建立的连接
netstat -s # 查看网络统计信息进程
#查看访问服务器的IP个数
netstat -pnt | grep :80
netstat -pnt | grep :80 | wc -l # IP个数
本地测试固定静态IP
用户root登陆到服务器,编辑配置信息
vi /etc/sysconfig/network-scripts/ifcfg-eth0设置如下内容,有则改之,无则添加
DEVICE=eth0
BOOTPROT=static
IPADDR=192.168.1.200
GATEWAY=192.168.1.1
NETMASK=255.255.255.0
ONBOOT=yes之后保存
然后重启网卡即可
service network restart现在试试吧,IP已经变为192.168.1.200
直接远程登陆
ssh root@192.168.1.200#查询Gateway Netmask
netstat -rn
route -n
#重启网卡
sudo ifconfig eth0 down
sudo ifconfig eth0 upuptime命令用于查看系统的负载情况,格式为:“uptime”
Load average:表示1分钟、5分钟、15分钟内系统的平均负荷
当CPU完全空闲的时候,平均负荷为0;当CPU工作量饱和的时候,平均负荷为1。
一般来说其CPU的核的数量决定了最大负荷,4核的CPU,工作量饱和的时候为4
(一般看15分钟的那个数据,因为1min具有瞬时性,不具有代表性)
watch -n 10 uptime #来每秒刷新一次获得当前的系统负载情况,每10秒输出一次系统负载情况pv #监视通过管道的数据
普通情况下,直接启动tcpdump将监视第一个网络界面上所有流过的数据包。
cssh #可视化的并发 shell
dstat #系统状态查看
slurm #网络可视化Glances 是一个由 Python 编写跨平台命令行系统监视工具。
glances可以为我们实时展示:
CPU 使用率
内存使用情况
内核统计信息和运行队列信息
磁盘 I/O 速度、传输和读/写比率
文件系统中的可用空间
磁盘适配器
网络 I/O 速度、传输和读/写比率
页面空间和页面速度
消耗资源最多的进程
计算机信息和系统资源
59.通信命令
write #发给某个用户信息
write fnngj #给fnngj用户发送信息
$ write fnngj pts/4
what are you fucking about
#结束消息
ctrl+d
# 踢掉在线终端
$ pkill -kill -t pts/4
hello fnngj !! I like you!!xixi #发送的内容
ctrl + D #结束
wall #发给所有使用系统的用户
wall [信息内容]
wall hello china60.Linux之 cut 用法
cut是一个选取命令,就是将一段数据经过分析,取出想要的。
其语法格式为:
cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file]
使用说明
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
主要参数
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除。
cut命令主要是接受三个定位方法:
第一,字节(bytes),用选项-b
who|cut -b 3 #提取每一行的第3个字节
who|cut -b 3-5,8 #提取第3,第4、第5和第8个字节第二,字符(characters),用选项-c
who|cut -c 3-5,8 #提取第3,第4,第5和第8个字符第三,域(fields),用选项-f
#设置“间隔符”,再设置“提取第几个域”
cat /etc/passwd|head -n 5|cut -d : -f 1 #用-d来设置间隔符为冒号,然后用-f来设置我要取的是第一个域
cat /etc/passwd|head -n 5|cut -d : -f 1,3-5 细节可参考
http://www.cnblogs.com/dong008259/archive/2011/12/09/2282679.html
61.gedit显示行号
用gedit打开文件,然后使gedit窗口最大化。然后鼠标移动到窗口左上方,编辑-首选项-查看-显示行号62.卸载软件命令
sudo apt-get autoremove software-name
sudo apt-get autoremove --purge software-name # 一次卸载干净63.Linux配置查询
screenfetch64.grep命令:筛选数据
grep是Globally search a Regular Expression and Print的缩写,意思是《全局搜索一个正则表达式,并且打印》
grep的简单用法
grep的最基本的用法:
grep text file可以看到,上面就是grep命令的最基本用法。
text代表要搜索的文本,file代表供搜索的文件。
实际的例子来学习。比如我要在用户的家目录的 .bashrc 文件中搜索alias这个文本,而且显示所有包含alias的行。
grep alias .bashrcgrep命令列出了.bashrc文件中所有包含alias的行,并且在小编的终端中,以红色标出了每一个alias。其实grep更像是一个过滤器,它可以筛选出我们要找的对象。
如果我们要用grep命令在一个文件中查找用空格隔开的文本,那么就要加上双引号,例如:
grep "Hello World" file2-i参数:忽略大小写
默认的情况下,grep命令是区分大小写的,也就是说搜索的文本将严格按照大小写来搜索。比如我搜索的文本是text,那么就不会搜出例如Text,tExt,TEXT等等文本。
但是我们可以给grep加上-i参数,使得grep可以忽略大小写。i是英语ignore的缩写,表示“忽略”。
例如:
grep -i alias .bashrc加了-i参数后,grep的搜索结果就多了 #Alias definitions. 那一行,因为-i参数使得grep搜索不区分大小写。
-n参数:显示行号
-n参数的作用很简单,就是显示搜索到的文本所在的行号。n是英语number的缩写,表示“数字,编号”。
grep -n alias .bashrc-v参数:只显示文本不在的行
-v参数很有意思,v是invert的缩写,表示“颠倒,倒置”。-v参数的作用与正常grep的作用正好颠倒,就是只显示搜索的文本不在的那些行。
grep -v alias .bashrc可以看到,这次grep过滤出了.bashrc中所有不包含alias的行。
-r参数:在所有子目录和子文件中查找
如果你不知道你要找的文本在哪个文件里,你可以用强大的-r参数。
r是英语recursive的缩写,表示“递归”。
如果用了-r参数,那么grep命令使用时的最后一个参数(grep text file这个模式中的file)需要换成directory,也就是必须是一个目录。因为-r参数是让grep命令能够在指定目录的所有子目录和子文件中查找文本。
grep -r "Hello World" folder/表示在folder这个目录的所有子目录和子文件中查找Hello World这个文本。当然了,以上例子中,folder后面的斜杠(/)不是必须的,这里只是为了清楚表明folder是一个目录。只要folder是一个目录,Linux系统是不会搞错的。
Linux中还有一个rgrep的命令,它的作用相当于grep -r
grep的高级用法:配合正则表达式
列出了最常用的一些正则表达式的字符以及其含义:
特殊字符 含义
. 匹配除 "\n" 之外的任何单个字符
^ 行首(匹配输入字符串的开始位置)
$ 行尾(匹配输入字符串的结束位置)
[] 在中括号中的任意一个字符
? 问号前面的元素出现零次或一次
* 星号前面的元素可能出现零次,一次或多次
+ 加号前面的元素必须出现一次以上(包含一次)
一根竖线 逻辑或
() 表达式的分组(表示范围和优先度)为了让grep命令知道我们要使用正则表达式,须要加上-E参数。例如:
grep -E Alias .bashrc当然了,Linux也有一个命令egrep,其效果等同grep -E
不要怀疑,Alias也算是一个正则表达式,只不过没有用到上面表格中的特殊符号而已。
来看这个例子:
grep -E ^alias .bashrc用到了^这个特殊符号,上面的表格里对于^已经做了说明:行首(匹配输入字符串的开始位置)。也就是说,^后面的字符须要出现在一行的开始。
因此,就搜出了这三行都是包含alias,并且以alias开头的。
再来举几个例子:
grep -E [Aa]lias .bashrc上面解释了[]的作用,是将[]中的字符任取其一,因此[Aa]lias的意思就是既可以是Alias,又可以是alias。因此grep的搜索结果把包含Alias和alias的行都列出来了。
再比如:
grep -E [0-4] .bashrc用于搜索包含0至4的任一数字的行。
grep -E [a-zA-Z] .bashrc用于搜索包含在a至z之间的任意字母或者A至Z之间的任意字母的行。
65.sort命令:为文件排序
sort是英语“排序”的意思。
sort命令用于对文件的行进行排序。
为了演示,我们首先用文本编辑器(可以用nano)来创建一个文件,名叫name.txt比如,然后在里面写入以下的行:
John
Paul
Luc
Matthew
Mark
jude
Daniel
Samuel
Job用sort命令来举个例子:
sort name.txt可以看到,sort命令将name.txt文件中的行按照首字母的英文字典顺序进行了排列。
可以看到,sort命令并不区分大小写。
-o参数:将排序后的内容写入新文件
如果你打开name.txt文件,你会发现,经过了sort命令的“洗礼”,name.txt中的内容还是维持原来的顺序。
单独使用sort命令是不会真正改变文件内容的,只是把排序结果显示在终端上。
那我们要存储排序结果到新的文件怎么办呢?可以用-o参数。
sort -o name_sorted.txt name.txt可以看到,name.txt经过sort命令排序之后的内容被储存在了新的文件name_sorted.txt中,而name.txt的内容是不变的。
-r参数:倒序排列
-r参数中的r是reverse的缩写,是“相反,反面”的意思,与普通的仅用sort命令正好相反。
sort -r name.txt-R参数:随机排序
-R参数比较“无厘头”,因为它会让sort命令的排序变为随机,就是任意排序,也许每次都不一样。但在有些时候,还是很有用的。
sort -R name.txt为了显示每次排序都是随机的
-n参数:对数字排序
对数字的排序有点特殊。默认地,仅用sort命令的时候,是不区分首字符是否是数字的,因此还是按照1-9的顺序来排序。例如138会排在25前面,因为1排在2的前面。
那如果我们要sort命令识别整个数字,比如按照大小顺序来说,25应该排在138前面,那该怎么办呢?
就可以请出我们的-n参数了。n是number的缩写。是英语“数字”的意思。-n参数用于对数字进行排序,按从小到大排序。
用文本编辑器来创建一个文件,就叫number.txt好了。
里面随便填一些数字,每行一个:
12
9
216
28
174
35
68sort name.txt结果
12
174
216
28
35
68
9sort -n name.txt结果
9
12
28
35
68
174
216可以看到,不加-n参数时,sort就会把这些数字按首字符来排序,按照1-9的顺序。
加上-n参数,就会把各行的数字看成一个整体,按照大小从小到大来排序了。
66.wc命令:文件的统计
wc是word count的缩写word是英语“单词”的意思,count是英语“计算,统计,数数”的意思。
因此,wc命令貌似是用来统计单词数目的,但其实wc的功能不仅止于此。wc命令还可以用来统计行数,字符数,字节数等。
wc name.txt可以看到返回值是
9 9 50 name.txt最后的name.txt只是表明文件名,不需考虑。
那么这三个数字:9,9,和50分别表示什么呢?
这三个数字,按顺序,分别表示:
行数
单词数
字节数-l参数:统计行数
为了只统计行数,我们可以加上-l参数。l是英语line的缩写,表示“行”。
wc -l name.txt因为我们之前创建name.txt时,每一行只有一个单词(英语名字),所以这里统计的行数和单词数都是9。
-w参数:统计单词数
w是英语word的缩写,word是英语“单词”的意思。因此-w参数用于统计单词。
wc -w name.txt-c参数:统计字节数
wc -c name.txt-m参数:统计字符数
wc -m name.txt统计某文件夹下文件的个数
ls -l |grep "^-"|wc -l统计当前目录及所有子目录下文件数目:
$ls -lR | grep '^-' | wc -l 统计当前目录及所有子目录下以‘.jpg’后缀结尾的图片个数:
$ls -lhR | grep '.jpg' |wc -l统计当前目录下及所有子目录下所有文件夹数目:
$ls -lR | grep '^d' | wc -ld67.uniq命令:删除文件中的重复内容
有时候,文件中包含重复的行。我们也许想要将重复的内容删除。
uniq是英语unique的缩写,表示“独一无二的”。
为了演示,我们创建一个文件repeat.txt(repeat是英语“重复”的意思),里面写入如下排序好的内容
Albert
China
France
France
France
John
Matthew
Matthew
patrick
Steve
Vincent可以看到,有三个France连在一起,两个Matthew连在一起。
我们用uniq命令来处理看看:
uniq repeat.txt
可以看到,三个连续的France只剩下一个了,两个连续的Matthew也只剩一个了。
但是uniq命令并不会改变原文件的内容,只会把处理后的内容显示出来。如果想将处理后的内容储存到一个新文件中,可以使用如下的方法:
uniq repeat.txt unique.txt-c参数:统计重复的行数
-c参数用于显示重复的行数,如果是独一无二的行,那么数目就是1。
uniq -c repeat.txt-d参数:只显示重复行的值
uniq -d repeat.txt68.cut命令:剪切文件的一部分内容
cut命令用于对文件的每一行进行剪切处理。
-c参数:根据字符数来剪切
比如,我们要name.txt的每一行只保留第2至第4个字符。可以这样做:
cut -c 2-4 name.txt69.tar命令:将多个文件归档
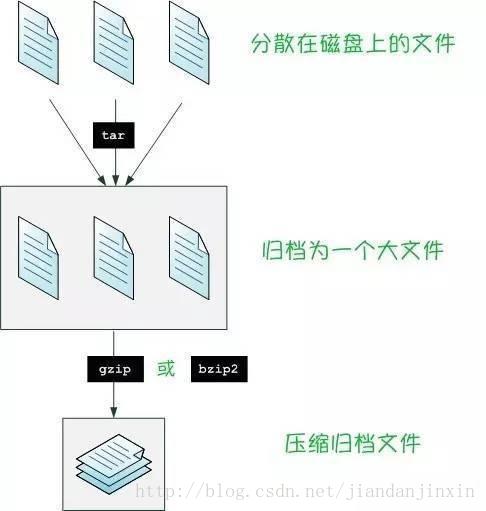
-cvf:创建一个tar归档
这样来创建一个tar归档:
tar -cvf newname.tar name/tar命令的三个选项参数分别表示:
c:c是create的缩写,表示“创建”。
v:v是verbose的缩写,表示“冗余”。会显示操作的细节。
f:f是file的缩写,表示“文件”。指定归档文件。可以直接对文件进行归档操作,不需要先把所有文件放到一个目录里,如下:
tar -cvf archive.tar file1.txt file2.txt file3.txt就会把file.txt,file2.txt,file3.txt归档为archive.tar。
-tf:显示归档里的内容,并不解开归档
可以用tf选项参数来看一下我们刚生成的归档newname.tar中的内容。
tar -tf newname.tar一般,建立归档之前,最好把所有文件都先放置到一个目录里。因为假如你拿到的归档文件是不包含目录的(如上面 tar -cvf archive.tar file1.txt file2.txt file3.txt这样),并且里面有好几百个文件,你将其解开到你的家目录,那会乱成一团的。
-rvf:追加文件到归档
例如:
tar -rvf archive.tar file_extra.txt表示将file_extra.txt这个文件添加到archive.tar归档中。
-xvf:解开归档
算是-cvf的相反操作。将生成的归档解开。x是extract的缩写,表示《提取,取出》。
tar -xvf newname.targzip和bzip2命令:压缩归档
Linux中常用的压缩命令是gzip和bzip2,它们的功能类似。
gzip:比较常用。
bzip2:不是那么常用。bzip2的压缩率比gzip更大,但是更耗时。.tar.gz:这是用gzip命令压缩后的文件后缀名。
.tar.bz2:这是用bzip2命令压缩后的文件后缀名。两个压缩命令的用法如下:
gzip newname.tar
bzip2 newname.tar就会分别生成newname.tar.gz和newname.tar.bz2两个压缩文件。
如果要对这两个命令生成的压缩文件分别进行解压,可以使用gunzip和bunzip2两个命令:
gunzip newname.tar.gz
bunzip2 newname.tar.bz2用tar命令同时归档和压缩
之前我们只介绍了tar命令的归档作用,其实我们可以用tar命令同时完成归档和压缩的操作。
当然了,也就是给tar命令多加一个选项参数,使之完成归档操作后,还是调用gzip或bzip2命令来完成压缩操作。
-zcvf:归档,然后用gzip来压缩归档
tar -zcvf newname.tar.gz newname/一步到位,从tutorial目录,归档、压缩,生成newname.tar.gz文件。
要解压,也可以一步到位:
tar -zxvf newname.tar.gz相信常用Linux系统的用户对这个命令应该很熟悉吧。
-jcvf:归档,然后用bzip2来压缩归档
tar -jcvf newname.tar.bz2 newname/一步到位,从tutorial目录,归档、压缩,生成newname.tar.bz2文件。
要解压,也可以一步到位:
tar -jxvf newname.tar.bz2zcat,zmore,zless:直接显示用gzip压缩的文件的内容
cat,more和less三个命令我们已经很熟悉了,是用于显示文件内容。
如果是压缩文件,比如我们上面生成的newname.tar.gz,如果直接用cat,more或less命令来显示,是会显示乱码的。
cat newname.tar.gz但是用zcat,zmore,zless命令就可以显示用gzip命令压缩的文件的内容了:
zcat newname.tar.gzunzip和unrar命令:解压zip和rar文件
尽管.tar.gz和.tar.bz2结尾的压缩文件在Linux世界很常见,但是如果某个Windows用户给您发送压缩文件,大部分情况可能是.zip或.rar结尾的压缩文件,那么在Linux下如何解压这类来自Windows世界的“外来物”呢?
不必担心,我们可以用unzip和unrar命令来分别解压.zip和.rar格式的压缩文件。
unzip:解压.zip格式的压缩文件
一般Linux发行版中默认没有安装这个程序,我们可以用以下命令来安装:
sudo apt-get install unzip # 这是在Debian一族中的安装方式安装完之后,要解压.zip格式的压缩文件,可以这样:
unzip archive.zip如果不想解开.zip文件,只想看其中的内容的话,可以加上-l参数:
unzip -l archive.zip在Linux中,虽然不常见,但是有时候我们也需要创建.zip格式的文件,我们可以安装zip这个程序:
sudo apt-get install zip # 这是在Debian一族中的安装方式想要生成.zip格式的压缩文件,可以这样:
zip -r archive.zip archive/**注意:这里有一个-r参数,须要加上。如果不加,则只会压缩空文件夹而已。加上-r参数,则会递归压缩目录和子目录中的所有文件。**
unrar:解压.rar格式的压缩文件
类似于unzip,安装unrar的命令如下:
sudo apt-get install unrar # 这是在Debian一族中的安装方式安装完之后,要解压.rar格式的压缩文件,可以这样:
unrar e archive.rar可以看到,有些意外,因为e这个选项参数前面没有 -(短横),人生总是有意外的不是吗?unrar这个命令的作者显然是不走寻常路。
如果不想解开.rar文件,只想看其中的内容的话,可以加上l参数(是的,也不加 -):
unrar l archive.rar那如果我想在Linux中创建.rar格式的压缩文件呢?
不好意思,.rar格式的压缩软件并没有公开,解压的软件是免费的。如果你要压缩rar文件,那只能去买收费软件。
Linux下也有rar这个软件,你也可以下载安装,但这是一个试用软件,到了一定天数后,就会收费。不过,zip软件是免费的。
70.crontab 添加定时任务
crontab的使用
crontab的使用非常简单:
usage: crontab [-u user] file
crontab [ -u user ] [ -i ] { -e | -l | -r }
(default operation is replace, per 1003.2)
-e (edit user's crontab)
-l (list user's crontab)
-r (delete user's crontab)
-i (prompt before deleting user's crontab)新建freemen.sh
cd root
mkdir toolsetting
cd toolsetting
gedit freemen.sh添加以下内容
#!/bin/bash
used=`free -m | awk 'NR==2' | awk '{print $3}'`
free=`free -m | awk 'NR==2' | awk '{print $4}'`
echo "===========================" >> /var/log/mem.log
date >> /var/log/mem.log
echo "Memory usage | [Use:${used}MB][Free:${free}MB]" >> /var/log/mem.log
sync && echo 1 > /proc/sys/vm/drop_caches
sync && echo 2 > /proc/sys/vm/drop_caches
sync && echo 3 > /proc/sys/vm/drop_caches
echo "OK" >> /var/log/mem.log
echo "Not required" >> /var/log/mem.log将脚本添加到crond任务,定时执行。
crontab -e #添加定时任务添加下列命令,每隔2分钟执行一次
*/2 * * * * root /root/toolsetting/freemem.sh备注:Crontab第一道第五个字段的整数取值范围及意义是:
0~59 表示分
1~23 表示小时
1~31 表示日
1~12 表示月份
0~6 表示星期(其中0表示星期日)
修改脚本的权限
chmod 777 /root/toolsetting/freemem.sh启动定时服务
service crond stop
service crond start查看定时任务
crontab -l查看结果
tail -f /var/log/mem.log ===========================
2017年 05月 10日 星期三 09:02:01 CST
Memory usage | [Use:15729MB][Free:99379MB]
OK
Not required
===========================
2017年 05月 10日 星期三 09:03:01 CST
Memory usage | [Use:15733MB][Free:111141MB]
OK
Not required
===========================
2017年 05月 10日 星期三 09:04:01 CST
Memory usage | [Use:15738MB][Free:110174MB]
OK
Not required
===========================
2017年 05月 10日 星期三 09:05:02 CST
Memory usage | [Use:15742MB][Free:111135MB]
OK
Not required
===========================
2017年 05月 10日 星期三 09:06:01 CST
Memory usage | [Use:15758MB][Free:111117MB]
OK
Not required
===========================
2017年 05月 10日 星期三 09:07:01 CST
Memory usage | [Use:15772MB][Free:110138MB]
OK
Not required
删除定时任务:
crontab -r(crontab -i)71.保留端口回话screen
#新建一个screen
screen
screen -S XXX #XXX是你为这个screen制定的名称#在screen 中新建一个虚拟终端
ctrl + a + c (先按ctrl +a,然后在按c)#在虚拟终端之间切换
#前一个
ctrl + a + p
#后一个
ctrl + a + n
#列表选择
ctrl+a+shift+#关闭一个虚拟终端
ctrl+a+k或者exit#重新连接screen
screen -ls #列出当前挂起的screen72.Shell 常用通配符
字符 含义
* 匹配 0 或多个字符
? 匹配任意一个字符
[list] 匹配 list 中的任意单一字符
[!list] 匹配 除list 中的任意单一字符以外的字符
[c1-c2] 匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z]
{string1,string2,...} 匹配 string1 或 string2 (或更多)其一字符串
{c1..c2} 匹配 c1-c2 中全部字符 如{1..10}73.输出图形字符的命令banner
#安装
sudo apt-get update
$ sudo apt-get install sysvbannerbanner linux打开office, pdf
openoffice.org -a 文件名.doc &
#打开演示文件命令:
openoffice.org -g 文件名.... &
#打开电子表格:
openoffice.org -c 文件名 &
#打开pdf文件
evince .....pdf &XX.待续—–
Linux 的云计算平台
- 本地有要运行的文件
单个文件的话可以直接 ssh 去云端运行
比如这个 Python 脚本是这样的.
import platform
a = 0
for i in range(9999):
a += i
print("Finish job, result=%i" % a)
print("This is", platform.system())$ ssh morvan@192.168.0.114 python3 < ~/Desktop/machine_learning.py
Finish job, result=49985001
This is Linux- 多个文件可以先复制去云端, 然后在 ssh 运行
比如我现在需要两个 Python 文件才能运行, b.py 如下:
# This is b.py
def inner_func():
print("This is a function in b")
还有一个 a.py 需要调用 b.py 才能运行.
# This is a.py
from b import inner_func
inner_func()输入 scp (secure copy), 加密传输复制 ~/Desktop/{a,b}.py 在我桌面上的 a.py 和 b.py 两个文件到 云端[email protected]的桌面 ~/Desktop
$ scp ~/Desktop/{a,b}.py morvan@192.168.0.114:~/Desktop
a.py 100% 37 6.3KB/s 00:00
b.py 100% 54 8.9KB/s 00:00在本地用 ssh 去云端, 但是 ssh 的时候同时发送一条指令去执行 a.py. 这条指令我们用 “” 给框起来, 说明是要发送去云端再执行的指令.
$ ssh morvan@192.168.0.114 "python3 ~/Desktop/a.py"
This is a function in b- 如果在云端有产生文件, 可以用 scp 复制回来
XX.待续—–
参考文献
https://www.quora.com/What-are-some-lesser-known-but-useful-Unix-commands
http://talk.linuxtoy.org/using-cli/#1
http://talk.linuxtoy.org/cli-tips/#1
https://github.com/jlevy/the-art-of-command-line
https://linuxtoy.org/
Linux探索之旅 | 第二部分第九课:查找文件,无所遁形