Spring Boot 数据库访问 简介
- 对于数据访问层,无论是 SQL(关系型数据库) 还是 NOSQL(非关系型数据库),Spring Boot 底层都是采用 Spring Data 的方式进行统一处理。
- Spring Boot 添加了大量自动配置,屏蔽了很多设置,引入各种 XxxTemplate,XxxRepository 来简化程序员对数据访问层的操作。
- 对程序员来说只需要进行简单的配置即可使用
Spring Data
- Spring Boot 底层都是采用 Spring Data 的方式进行统一处理各种数据库,Spring Data 也是 Spring 中与 Spring Boot、Spring Cloud 等齐名的知名项目。
- Sping Data 官网:https://spring.io/projects/spring-data
Overview
Spring Data’s mission is to provide a familiar and consistent, Spring-based programming model for data access while still retaining the special traits of the underlying data store.
It makes it easy to use data access technologies, relational and non-relational databases, map-reduce frameworks, and cloud-based data services. This is an umbrella project which contains many subprojects that are specific to a given database. The projects are developed by working together with many of the companies and developers that are behind these exciting technologies.
Features
-
Powerful repository and custom object-mapping abstractions
-
Dynamic query derivation from repository method names
-
Implementation domain base classes providing basic properties
-
Support for transparent auditing (created, last changed)
-
Possibility to integrate custom repository code
-
Easy Spring integration via JavaConfig and custom XML namespaces
-
Advanced integration with Spring MVC controllers
-
Experimental support for cross-store persistence
Community modules
-
Spring Data Aerospike - Spring Data module for Aerospike.
-
Spring Data ArangoDB - Spring Data module for ArangoDB.
-
Spring Data Couchbase - Spring Data module for Couchbase.
-
Spring Data Azure DocumentDB - Spring Data module for Microsoft Azure DocumentDB.
-
Spring Data DynamoDB - Spring Data module for DynamoDB.
-
Spring Data Elasticsearch - Spring Data module for Elasticsearch.
-
Spring Data Hazelcast - Provides Spring Data repository support for Hazelcast.
-
Spring Data Jest - Spring Data for Elasticsearch based on the Jest REST client.
-
Spring Data Neo4j - Spring based, object-graph support and repositories for Neo4j.
-
Spring Data Vault - Vault repositories built on top of Spring Data KeyValue.
Related modules
-
Spring Data JDBC Extensions - Provides extensions to the JDBC support provided in the Spring Framework.
-
Spring for Apache Hadoop - Simplifies Apache Hadoop by providing a unified configuration model and easy to use APIs for using HDFS, MapReduce, Pig, and Hive.
-
Spring Content - Associate content with your Spring Data Entities and store it in a number of different stores including the File-system, S3, Database or Mongo’s GridFS.
Release train
Spring Data is an umbrella project consisting of independent projects with, in principle, different release cadences. To manage the portfolio, a BOM (Bill of Materials - see this example) is published with a curated set of dependencies on the individual project. The release trains have names, not versions, to avoid confusion with the sub-projects.
The names are an alphabetic sequence (so you can sort them chronologically) with names of famous computer scientists and software developers. When point releases of the individual projects accumulate to a critical mass, or if there is a critical bug in one of them that needs to be available to everyone, the release train will push out “service releases” with names ending “-SRX”, where “X” is a number.
Currently the release train contains the following modules:
-
Spring Data Commons
-
Spring Data JPA
-
Spring Data KeyValue
-
Spring Data LDAP
-
Spring Data MongoDB
-
Spring Data Gemfire
-
Spring Data for Apache Geode
-
Spring Data REST
-
Spring Data Redis
-
Spring Data for Apache Cassandra
-
Spring Data for Apache Solr
-
Spring Data Couchbase (community module)
-
Spring Data Elasticsearch (community module)
-
Spring Data Neo4j (community module)
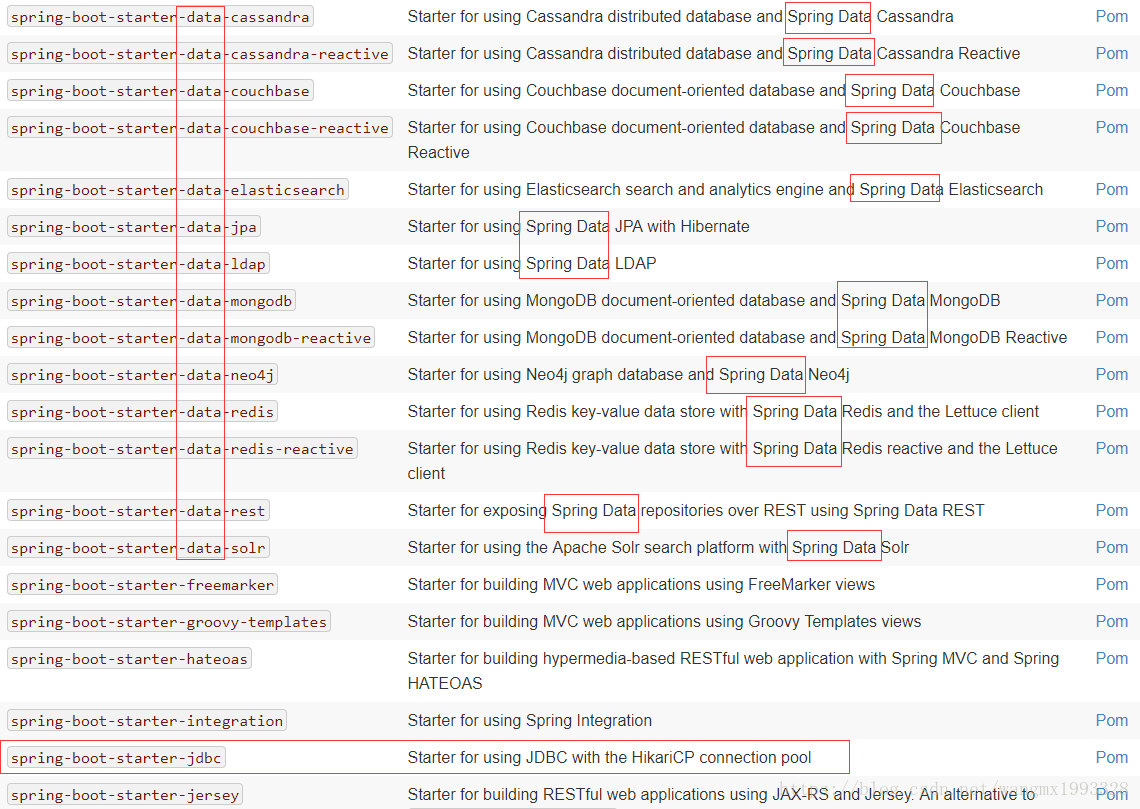
Spring Boot 数据库启动器
- 可以参考官方文档:https://docs.spring.io/spring-boot/docs/2.0.4.RELEASE/reference/htmlsingle/#using-boot-starter