本篇文章仅做sys_write()源码阅读后的记录,从自己的思路叙述,比较随意,仅做本人阅读存档。
sys_write()是linux文件系统中核心函数之一,它完成的操作是将用户缓冲区的文件内容写入到文件在磁盘中的对应位置。
1.文件页面缓存
要想理解Linux文件读写过程,首先需要明白linux对文件读写的设计,具体就是文件数据在内存中的组织方式。我们先看一张图(摘自linux内核情景分析)
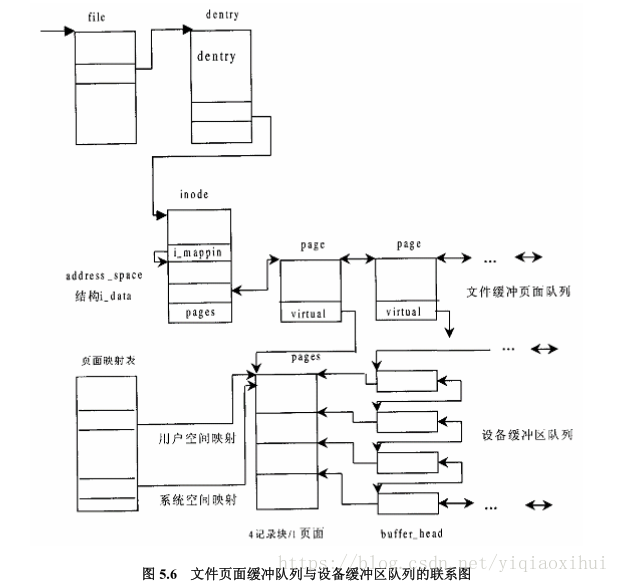
我们可以先考虑若要写入文件内容需要具备哪些条件,这是一个很好的习惯,在看源码的过程中,看一个函数首先不要着急一行行阅读,先思考如果我要设计这个函数,具体需要怎么做,这样能更好的理解。
2.磁盘数据块在内存
首先,我们知道磁盘属于块设备,对磁盘的读写是以块为单位进行的,原因可以简单的理解为文件的内容是以块为最小单位存储的,例如以Ext2文件系统为例,一块大小是1K字节,在设备层面我们把它称为文件在磁盘中的记录块(简称记录块)。那么我们自然想到文件数据在内存中也是按块的大小来组织的,这样设计方便底层驱动对块设备的读写。
所以,无论文件数据块在内存中怎么存储,必定有一个数据结构,它要和文件数据在磁盘中的一块对应起来,这个数据结构中有一个字段(b_page)肯定保存(指向)文件记录块在内存中的拷贝,有一个字段肯定记录对应的磁盘块号b_blocknr,这是最基本的信息。
事实和我们想的一样,linux中这个数据结构叫buffer_head,它文件在磁盘中的记录块在内存中的缓冲区。
struct buffer_head {
/* First cache line: */
struct buffer_head *b_next; /* Hash queue list */
unsigned long b_blocknr; /* block number */
unsigned short b_size; /* block size */
unsigned short b_list; /* List that this buffer appears */
kdev_t b_dev; /* device (B_FREE = free) */
atomic_t b_count; /* users using this block */
kdev_t b_rdev; /* Real device */
unsigned long b_state; /* buffer state bitmap (see above) */
unsigned long b_flushtime; /* Time when (dirty) buffer should be written */
struct buffer_head *b_next_free;/* lru/free list linkage */
struct buffer_head *b_prev_free;/* doubly linked list of buffers */
struct buffer_head *b_this_page;/* circular list of buffers in one page */
struct buffer_head *b_reqnext; /* request queue */
struct buffer_head **b_pprev; /* doubly linked list of hash-queue */
char * b_data; /* pointer to data block (512 byte) */
struct page *b_page; /* the page this bh is mapped to */
void (*b_end_io)(struct buffer_head *bh, int uptodate); /* I/O completion */
void *b_private; /* reserved for b_end_io */
unsigned long b_rsector; /* Real buffer location on disk */
wait_queue_head_t b_wait;
struct inode * b_inode;
struct list_head b_inode_buffers; /* doubly linked list of inode dirty buffers */
};
buffer_head数据结构比较复杂,我们为了关注sys_write()这条主线,省略一些细节可能更容易理解。
然后文件系统的设计者比我们想的更多,仅仅一个buffer_head是不够的,还需要考虑读写效率的问题。
3.文件的页面缓冲
我们知道linux中内存管理是以页面为单位进行管理,数据结构为Page。一个页面为4K个字节,也就是4个记录块大小。事实上文件内容在内存中是以页面为单位进行缓冲的。之前说过记录块大小为1K字节,内存中以记录块单位大小进行缓冲不更简单便于管理吗?这是为了文件内容缓存和文件内存映射结合在一起。文件内存映射机制直接将文件内容映射的用户空间,以后就可以像访问内存一样访问文件。如果文件内容以页面为单位缓冲,设置好相应的内存映射表,很自然的就将缓冲页面映射的用户空间。这样文件系统的缓冲机制和文件内存映射机制就巧妙的结合在一起了。
如上图所示,文件内容首先以页面为单位缓存,因此每个缓冲页面需要4个buffer_head指向页面中固定1K的间隔处。

--摘自linux内核情景分析
4.文件在磁盘中的组织方式
在大致了解了文件缓冲在内存中的结构,我们还需要了解文件在磁盘中的组织形式,这里仅说明和文件读写相关的关键内容,如下图所示
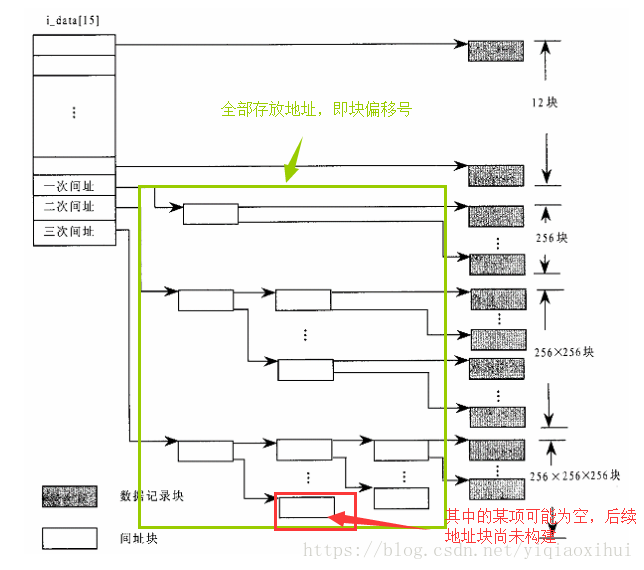
文件的元信息记录了文件的各种属性,其中i_data[15]字段记录文件在磁盘中存放的块号,但是15个块号文件大小最多是15K字节显然不行,因此i_data数组前12个为直接索引,数组的第13、14、15分别是一重、两重、三重简介寻址,如上图所示。那这和文件写操作有什么关系呢?关系是显然的,例如,如果写入的数据刚好是需要三重间接寻址才能索引的的数据块,那么需要将三块存放地址的数据块读到内存中,如果要写入数据的块通过计算发现三重间接寻址块中对应的偏移出地址刚好为空(图中红色标识),说明三重间接寻址未建立,这时不仅需要为文件内容分配记录块,还需要为作为三重间接寻址的相应数据块分配设备块。要知道只有文件比较大需要用到三重索引时,系统才会为其分配用于存放间址的记录块。
5.文件写操作
在大致了解了文件在内存和磁盘中的组织方式,我们现在可以思考,写文件时具体需要做哪些工作?需要知道哪些参数?
可以想象写文件一定需要知道:
1.写哪个文件:struct file *file 结构体
2.写的内容是什么:char* buf
3.写多少字节的数据:size_t count
4.从文件的那个位置开始写:文件偏移量f_pos,file->f_pos
再猜测一下需要做哪些工作的,最必须的工作可能是:
1.待续。。。