算法概述
CART(Classification And Regression Tree)算法是一种决策树分类、回归方法。
它采用一种二分递归分割的技术,分割方法采用基于最小距离的基尼指数估计函数,将当前的样本集分为两个子样本集,使得生成的的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。
分类树
如果目标变量是离散变量,则是classfication Tree。
分类树是使用树结构算法将数据分成离散类的方法。
回归树
如果目标是连续变量,则是Regression Tree。
CART树是二叉树,不像多叉树那样形成过多的数据碎片。
分类树两个关键点
(1)将训练样本进行递归地划分自变量空间进行建树
(2)用验证数据进行剪枝。
a.对于离散变量X(x1…xn)
分别取X变量各值的不同组合,将其分到树的左枝或右枝,并对不同组合而产生的树,进行评判,找出最佳组合。如果只有两个取值,好办,直接根据这两个值就可以划分树。取值多于两个的情况就复杂一些了,如变量年纪,其值有“少年”、“中年”、“老年”,则分别生产{少年,中年}和{老年},{上年、老年}和{中年},{中年,老年}和{少年},这三种组合,最后评判对目标区分最佳的组合。因为CART二分的特性,当训练数据具有两个以上的类别,CART需考虑将目标类别合并成两个超类别,这个过程称为双化。这里可以说一个公式,n个属性,可以分出(2^n-2)/2种情况。
b.对于连续变量X(x1…xn)
首先将值排序,分别取其两相邻值的平均值点作为分隔点,将树一分成左枝和右枝,不断扫描,进而判断最佳分割点。特征值大于分裂值就走左子树,或者就走右子树。
这里有一个问题,这次选中的分裂属性在下次还可以被选择吗?对于离散变量XD,如果XD只有两种取值,那么在这一次分裂中,根据XD分裂后,左子树中的subDataset中每个数据的XD属性一样,右子树中的subDataset中每个数据的XD属性也一样,所以在这个节点以后,XD都不起作用了,就不用考虑XD了。XD取3种,4种。。。的情况大家自己想想,不难想明白。至于连续变量XC,离散化后相当于一个可以取n个值的离散变量,按刚刚离散变量的情况分析。除非XC的取值都一样,否则这次用了XC作为分裂属性,下次还要考虑XC。
变量和最佳切分点选择原则
树的生长,总的原则是,让枝比树更纯,而度量原则是根据不纯对指标来衡量,对于分类树,则用GINI指标、Twoing指标、Order Twoing等;如果是回归树则用,最小平方残差、最小绝对残差等指标衡量
(1)GINI指标(Gini越小,数据越纯)——针对离散目标
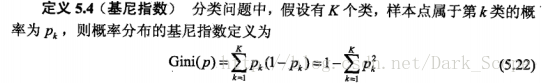


(2)最小平方残差——针对连续目标
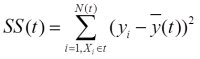
其思想是,让组内方差最小,对应组间方差最大,这样两组,也即树分裂的左枝和右枝差异化最大。
通过以上不纯度指标,分别计算每个变量的各种切分/组合情况,找出该变量的最佳值组合/切分点;再比较各个变量的最佳值组合/切分点,最终找出最佳变量和该变量的最佳值组合/切分点
整个树的生长是一个递归过程,直到终止条件
终止条件
(1)节点是纯结点,即所有的记录的目标变量值相同
(2)树的深度达到了预先指定的最大值
(3)混杂度的最大下降值小于一个预先指定的值
(4)节点的记录量小于预先指定的最小节点记录量
(5)一个节点中的所有记录其预测变量值相同
直观的情况,当节点包含的数据记录都属于同一个类别时就可以终止分裂了。这只是一个特例,更一般的情况我们计算χ2值来判断分类条件和类别的相关程度,当χ2很小时说明分类条件和类别是独立的,即按照该分类条件进行分类是没有道理的,此时节点停止分裂。注意这里的“分类条件”是指按照GINI_Gain最小原则得到的“分类条件”。
终止条件(3)混杂度的最大下降值小于一个预先指定的值,该枝的分化即停止。所有枝节的分化都停止后,树形模型即成。其实你也可以不使用这个终止条件,让树生长到最大,因为CART有剪枝算法。