在做特征抽取的时候,我们是尽可能地抽取更多的Feature,但过多的 Feature 会造成 冗余(部分特征的相关度太高了,消耗计算性能),噪声(部分特征是对预测结果有负影响),容易过拟合等问题,因此我们需要进行 特征筛选。特征选择可以加快模型的训练速度,甚至还可以提升效果。
接下来,我们了解下各种特征选择的方式。

- 过滤型(Filter)
评估 单个特征 和 结果值 之间的相关程度,我们可以排序留下Top相关程度较高 的的特征部分。而计算相关程度可以用相关系数、互信息、卡方检验,距离相关度来 计算。这种方法的缺点是:没有考虑到特征之间的关联作用,可能把有用的关联特征误踢掉(数值为0,并不能说明两个变量不相关,只是线性不相关而已)。
- 方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
from sklearn.datasets import load_iris
from sklearn.feature_selection import VarianceThreshold
from sklearn.feature_selection import SelectKBest # 根据 k个最高分选择功能。
Data = load_iris()
X, y = Data.data, Data.target
print(X.shape)
X_new = VarianceThreshold(threshold=3).fit_transform(X, y) #参数threshold为方差的阈值
print(X_new.shape) >>>(150, 4)
>>>(150, 1)
2.相关系数法
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 200
X = np.random.normal(0, 1, size)
print("Lower noise", pearsonr(X, X+np.random.normal(0, 1, size)))
print("higher noise", pearsonr(X, X+np.random.normal(0, 10. size)))>>>Lower noise (0.7579114556127933, 1.3803800258462316e-38)
>>>higher noise (0.04185684491264431, 0.5562015462329835)
3.卡方检验
卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:

用feature_selection库的SelectKBest类 结合 卡方检验 来选择特征的代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import chi2 #卡方检验
from sklearn.feature_selection import SelectKBest # 根据 k个最高分选择功能。
Data = load_iris()
X, y = Data.data, Data.target
print(X.shape)
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
print(X_new.shape) >>>(150, 4)
>>> (150, 2)
4.互信息法
互信息是用于评价离散特征对离散目标变量的相关性。
互信息用于特征选择有以下缺点:
- 它不属于度量方式,无法进行归一化,在不同数据集上的结果无法做比较;
- 对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
最大信息系数(Maximal Information Coefficient, MIC)克服了这两个问题。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。
MIC度量计算的方法
具有两个属性的数据点的集合分布在两维的空间中,使用m乘以n的网格划分数据空间,使落在第(x,y)格子中的数据点的频率作为P(x,y)的估计即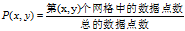 ,使落在第x行的数据点的频率作为P(x)的估计,同理获得P(y)的估计。然后计算随机变量X、Y的互信息。因为m乘以n的网格划分数据点的方式不止一种,所以我们要获得使互信息最大的网格划分。然后使用归一化因子,将互信息的值转化为(0,1)区间之内。最后,找到能使归一化互信息最大的网格分辨率,作为MIC的度量值。其中网格的分辨率限制为m x n < B,
,使落在第x行的数据点的频率作为P(x)的估计,同理获得P(y)的估计。然后计算随机变量X、Y的互信息。因为m乘以n的网格划分数据点的方式不止一种,所以我们要获得使互信息最大的网格划分。然后使用归一化因子,将互信息的值转化为(0,1)区间之内。最后,找到能使归一化互信息最大的网格分辨率,作为MIC的度量值。其中网格的分辨率限制为m x n < B,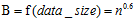 。
。
将MIC的计算过程概括为公式为: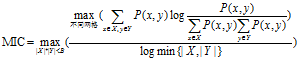
minepy提供了MIC功能,代码如下:
from minepy import MINE
import numpy as np
m = MINE()
x = np.random.uniform(-1, 1, 10000)
m.compute_score(x, x ** 2)
print(m.mic())>>>1.0000000000000009
MIC的不足:当零假设不成立时,MIC的统计就会受到影响。在有的数据集上不存在这个问题,但有的数据集上就存在这个问题。
- 包裹型(Wrapper)
包裹型是指把特征选择看做一个特征子集搜索问题,筛选各种特征子集,用模型评估效果。典型的包裹型算法为 “递归特征删除算法”REF(recursive feature elimination algorithm)。
比如用逻辑回归,怎么做这个事情呢?
1、用全量特征跑一个模型
2、根据线性模型的系数(体现相关性),删掉5-10%的弱特征,观察 准确率/auc的变化
3、逐步进行,直至准确率/auc出现大的下滑停止
from sklearn.feature_selection import RFE # 递归特征删除算法,通过递归地删除越来越小来弱特征
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
data = load_boston()
X = data["data"]
y = data["target"]
names = data["feature_names"]
LR = LinearRegression()
rfe = RFE(LR, n_features_to_select=1) #对所有特征排序,持续消除直到最后一个
rfe.fit(X, y)
print("通过排序后得到特征分类")
# 在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
print(sorted(zip(map(lambda x: round(x, 3), rfe.ranking_), names), reverse=True))# 返回最接近于参数x的数,其值保留到小数点后面3位>>>[(13, 'AGE'), (12, 'B'), (11, 'TAX'), (10, 'ZN'), (9, 'INDUS'), (8, 'CRIM'), (7, 'RAD'), (6, 'LSTAT'), (5, 'DIS'), (4, 'PTRATIO'), (3, 'CHAS'), (2, 'RM'), (1, 'NOX')]
- 嵌入型(Embedded)
嵌入型特征选择是指根据模型来分析 特征的重要性(有别于上面的方式, 是从产生的模型权重等. 最常见的方式为用正则化方式来做特征选择。
正则化一般分为两种:L1正则化 和 L2正则化。
一般回归分析中 回归w 表示 特征的系数,从下式可以看到正则化项是对 系数做了处理(限制)。
L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中 各个元素的绝对值之和,通常表示为

- L2正则化是指权值向量w中 各个元素的平方和(可以看到Ridge回归的L2正则化项有平方符号),通常表示为

一般都会在正则化项之前添加一个系数,Python中用 α 表示,一些文章也用 λ 表示,主要用来 权衡正则项与C0项的比重。另外L2正则化项须要再乘以1/2,要是为了后面求导的结果方便,后面那一项求导会产生一个2, 与1/2相乘刚好凑整。
L2正则化项是怎么避免overfitting的呢?
我们推导一下看看,先求导:

能够发现 L2正则化项 对 b 的更新没有影响,可是对于 w 的更新有影响:

在不使用L2正则化时,求导结果中 w 前系数为 1,经变化后w前面系数为 1−ηλ/n ,由于η、λ、n都是正的。所以 1−ηλ/n小于1,它的效果是减小w,这也就是权重衰减(weight decay)的由来。
更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀)
那添加L1和L2正则化有什么用?
- L1正则化可以产生 稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型 过拟合(overfitting)。当然,一定程度上,L1也可以防止过拟合。
稀疏模型与特征选择
上面提到 L1正则化b 有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。
在预测或分类时,那么多特征显然难以选择,而且模型复杂。但是,如果 代入这些特征 得到的模型是一个 稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征,大大减少模型复杂度,这就是稀疏模型与特征选择的关系。
举个例子,最早在电商用LR做CTR预估,在3-5亿维的系数 特征上用L1正则化的LR模型。剩余2-3千万的feature,意味着其他的feature重要度不够。
在什么情况下使用L1,什么情况下使用L2?
L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?我看到的有两种几何上直观的解析:
(1)下降速度:
我们知道,L1和L2都是规则化的方式,我们将 权值参数 以 L1 或者 L2 的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快,所以会非常快得降到0。不过我觉得这里解释的不太中肯,当然了也不知道是不是自己理解的问题.
L1称Lasso,L2称Ridge

L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。
L1(Lasso)在 特征选择 时候非常有用,而L2(Ridge)就只是一种规则化而已.
通过训练带L1或L2惩罚项的Linear Model模型来筛选特征
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
data = load_iris()
X, y = data.data, data.target
LSVC_L1 = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
LSVC_L2 = LinearSVC(C=0.01, penalty="l2", dual=False).fit(X, y)
#如果prefit=为True,则必须直接调用``transform``, 否则使用``fit``然后``transform``来训练模型
model_L1 = SelectFromModel(LSVC_L1, prefit=True)
model_L2 = SelectFromModel(LSVC_L2, prefit=True)
# model.fit(X, y)
X_L1 = model_L1.transform(X)
X_L2 = model_L2.transform(X)
print(X.shape)
print(X_L1.shape)
print(X_L2.shape)>>>(150, 4)
>>>(150, 2)
基于随机森林的特征选择法
随机森林由多个决策树构成。决策树中的每一个节点都是基于某个特征的将数据集按照不同的label一分为二。利用随机森林提供的不纯度可以进行特征选择,对于分类问题,通常采用 基尼指数Gini 或者 信息增益IG;对于回归问题,通常采用的是 方差 或者最小二乘拟合。当训练随机森林时,可算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的依据。基于随机森林的特征选择代码如下:
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rf = RandomForestRegressor()
rf.fit(X, Y)
print("Features sorted by their score:")
print(sorted(zip(map(lambda x: round(x, 4), rf.feature_importances_), names), reverse=True))>>>Features sorted by their score:
>>>[(0.4761, 'LSTAT'), (0.3321, 'RM'), (0.0649, 'DIS'), (0.0361, 'CRIM'), (0.0245, 'NOX'), (0.0178, 'TAX'), (0.0144, 'AGE'), (0.0119, 'PTRATIO'), (0.0097, 'B'), (0.0059, 'INDUS'), (0.0048, 'RAD'), (0.0014, 'CHAS'), (0.0004, 'ZN')]
