接着上一篇,我们继续介绍stream 相关api。我们知道stream有两大类操作:
1)Intermediate相关的操作有:map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
2)Terminal相关的操作有:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
3)Short-circuiting(短路)相关的操作有:anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
下面,我们重点讲一些常见的方法。
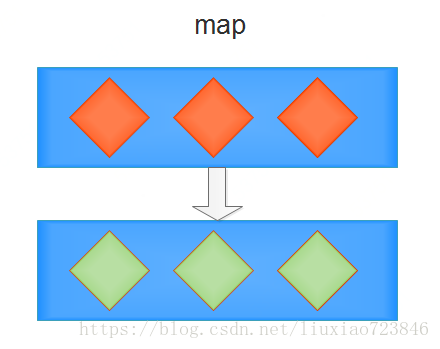
1、map、flatMap:
1)map:
如果你熟悉 scala 这类函数式语言,对这个方法应该很了解,它的作用就是把 input Stream 的每一个元素,映射成 output Stream 的另外一个元素,中间可以对元素值进行修改。map和flatMap都接受一个Function<T,R>的参数。
public static void mapTest() {
List<String> list1 = Arrays.asList(new String[]{"a1","b2","c3"});
list1.stream().map(String::toUpperCase).forEach(System.out::print);
}输出:A1B2C3
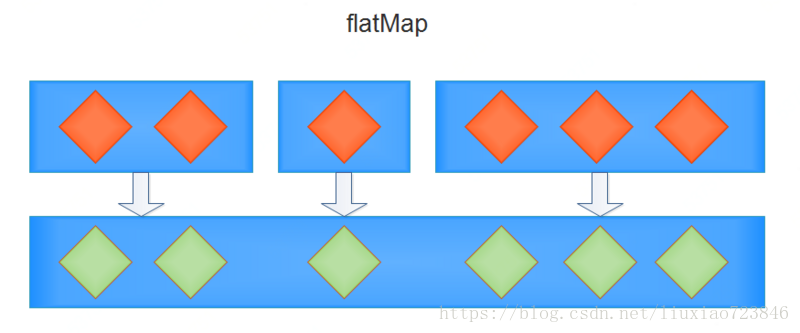
2)flatMap:
map方法是将一个容器里的元素映射到另一个容器中。
flatMap方法,可以将多个容器的元素全部映射到一个容器中,即为扁平的map。
我们看几个例子:求每个元素的平法
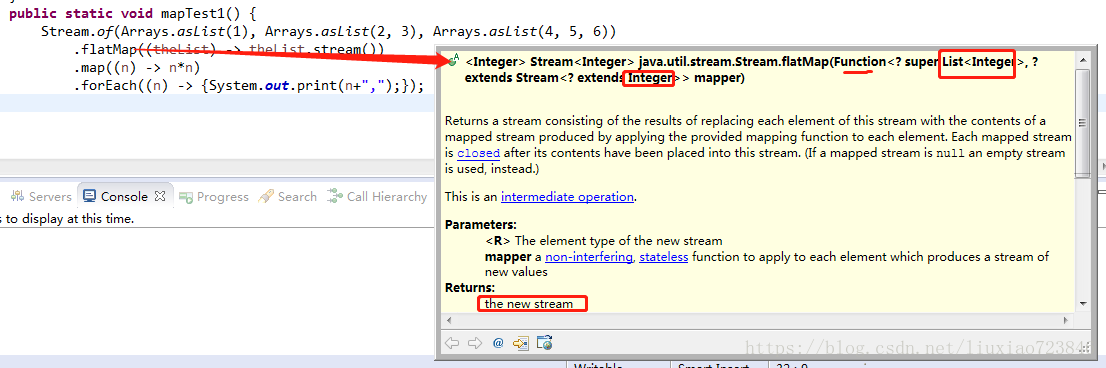
Stream.of(Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6))
.flatMap((theList) -> theList.stream())
.map((n) -> n*n)
.forEach((n) -> {System.out.print(n+",");});首先我们创建了一个Stream对象,使用三个容器List<Integer>初始化这个Stream对象,然后使用flatMap方法将每个容器中的元素映射到一个容器中,这时flatMap接收的参数Funciton的泛型T就是List<Integer>类型,返回类型就是T对应的Stream。最后再对这个容器使用map方法求出每个元素的平方,map接受的也是一个Function,其泛型T是integer(上一步FlatMap生成新的Stream的元素),返回值是T对应的Stream)。
Function接口有两个参数:第一个都是输入、第二个是输出,我们在eclipse可以看到具体的类型。
我们再看一个例子,输出每个单词的字母:
List<String> words = new ArrayList<String>();
words.add("your");
words.add("name");
Stream<Character> flatMap = words.stream()
.flatMap(w -> {
List<Character> result = new ArrayList<>();
for (char c : w.toCharArray())
result.add(c);
return result.stream();
});
List<Character> collect = flatMap.collect(Collectors.toList());有的时候,我们一个Stream经过转换操作后,就会变成多个值得Stream,这是就需要使用flatMap。flatMap的参数Function中泛型T是String,返回值是Character对应的Stream;我们用collect可以转成List<Character>.
输出:[y, o, u, r, n, a, m, e]
如果我们用map:
Stream<List<Character>> map = words.stream().map(w -> {
List<Character> result = new ArrayList<>();
for (char c : w.toCharArray())
result.add(c);
return result;
});
List<List<Character>> collect2 = map.collect(Collectors.toList());输出:[[y, o, u, r], [n, a, m, e]]
map的参数Function中泛型T是String,返回值是List<Character>对应的Stream;所以我们用collect最终转成List<List<Character>>.
2、filter:
filter对原始 Stream 进行某项测试,通过测试的元素被留下来生成一个新 Stream。所以filter方法接受的参数是Predicate<T>,它会返回一个boolean
List<User> tmpList = list.stream()
.filter(u -> u.getSex()==0)
.filter(predicate2)
.collect(Collectors.toList());predicate之间还可以进行逻辑运算
Predicate<User> predicate = u -> u.getSex()==0;
Predicate<User> predicate2 = u -> u.getAge()>=12;
list.stream()
.filter(predicate.or(predicate2))
.forEach(u -> System.out.println(u));3、sorted:
对 Stream 的排序通过 sorted (可以传入自定义排序接口Comparator,当然推荐使用lambda),它比数组的排序更强之处在于你可以首先对 Stream 进行各类 map、filter、limit、skip 甚至 distinct 来减少元素数量后,再排序,这能帮助程序明显缩短执行时间。
list.stream()
.filter(predicate.or(predicate2))
.limit(2)
.sorted((u1,u2) -> (u2.getAge()-u1.getAge()))
.forEach(u -> System.out.println(u));4、limit、skip:
limit 返回 Stream 的前面 n 个元素;skip 则是扔掉前 n 个元素(它是由一个叫 subStream 的方法改名而来)。
public void testLimitAndSkip() {
List<Person> persons = new ArrayList();
for (int i = 1; i <= 10000; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<String> personList2 = persons.stream().
map(Person::getName).limit(10).skip(3).collect(Collectors.toList());
System.out.println(personList2);
}
private class Person {
public int no;
private String name;
public Person (int no, String name) {
this.no = no;
this.name = name;
}
public String getName() {
System.out.println(name);
return name;
}
}输出:
name1
name2
name3
name4
name5
name6
name7
name8
name9
name10
[name4, name5, name6, name7, name8, name9, name10]这是一个有 10,000 个元素的 Stream,但在 short-circuiting 操作 limit 和 skip 的作用下,管道中 map 操作指定的 getName() 方法的执行次数为 limit 所限定的 10 次,而最终返回结果在跳过前 3 个元素后只有后面 7 个返回。
有一种情况是 limit/skip 无法达到 short-circuiting 目的的,就是把它们放在 Stream 的排序操作后,原因跟 sorted 这个 intermediate 操作有关:此时系统并不知道 Stream 排序后的次序如何,所以 sorted 中的操作看上去就像完全没有被 limit 或者 skip 一样。
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().sorted((p1, p2) ->
p1.getName().compareTo(p2.getName())).limit(2).collect(Collectors.toList());
System.out.println(personList2);首先对 5 个元素的 Stream 排序,然后进行 limit 操作。输出结果为:
name2
name1
name3
name2
name4
name3
name5
name4
[stream.StreamDW$Person@816f27d, stream.StreamDW$Person@87aac27]最后有一点需要注意的是,对一个 parallel 的 Steam 管道来说,如果其元素是有序的(执行sorted),那么 limit 操作的成本会比较大,因为它的返回对象必须是前 n 个也有一样次序的元素。取而代之的策略是取消元素间的次序,或者不要用 parallel Stream。
5、distinct:
List<String> words = br.lines().
flatMap(line -> Stream.of(line.split(" "))).
filter(word -> word.length() > 0).
map(String::toLowerCase).
distinct().
sorted().
collect(Collectors.toList());
br.close();
System.out.println(words);