最近在复习数据结构方面的知识,顺便回顾一下java集合的实现。上网找了一下java Collection的文章,想看一下完整的类图,结果发现大多数都是没画得很清楚,或者过于复杂,不适合我看。于是,我想自己花点时间整理一下,顺便加深一下印象。这不,花了2、3个小时整理出来了。以下类图基于jdk1.7,对比了一下1.8也是一样的结构。
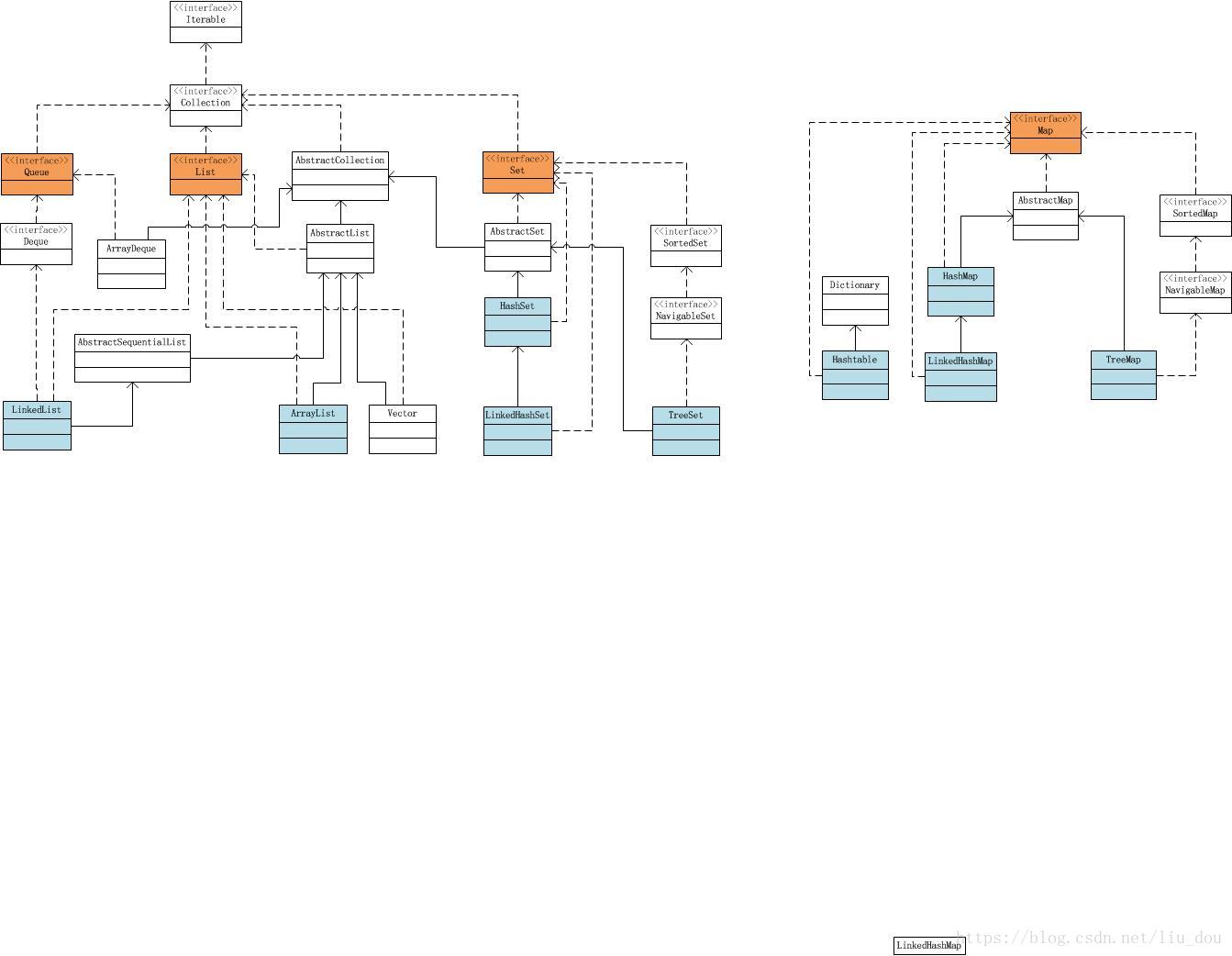
List
ArrayList:跟名字一样,基于数组实现,它的优缺点就是数组的优缺点。
LinkedList:基于链表实现。
要对比这2者的区别,只要理解数组跟链表的区别就好了,还有它们的优缺点。
总的来说,
ArrayList适用于大数据量的查询,添加元素也是可以的,默认在末尾添加,只要不是指定位置的添加,效率都是比较高的。但是,要注意扩容的问题,如果初始化的时候能预计到元素的量,可以预先分配大小,避免频繁扩容,复制元素很耗时。
LinkedList适用于数据量比较大的,增删比较多的操作。它同时实现了双向队列Deque的接口,所以它也封装了一些操作头尾节点的方法。
ArrayDeque和Vector,说实话,从事互联网业务这么多年,基本上没用过。可能它们更适用于其他业务场景。
Set
HashSet:基于HashMap实现,HashSet的不重复就是利用HashMap的key不能重复的特性实现,HashSet就是HashMap的keySet,只不过他们对应的value都是同一个Object。想不到吧~~
LinkedHashSet:继承于HashSet,唯一不同的是,基于LinkedHashMap实现。
TreeSet:基于TreeMap实现,后面看了TreeMap再补充。//TODO
Map
HashMap:jdk1.7基于数组加链表实现,1.8会基于数组加红黑树。下面这2篇文章讲得比较清楚了。
https://www.cnblogs.com/chengxiao/p/6059914.html
https://www.cnblogs.com/yangming1996/p/7997468.html
LinkedHashMap://TODO 时间到了要去跑步啦。
Hashtable:
TreeMap:
接下来,
计划再看一遍源码实现。
阿帕奇的集合工具实现。
还有concurrent下面的集合相关。