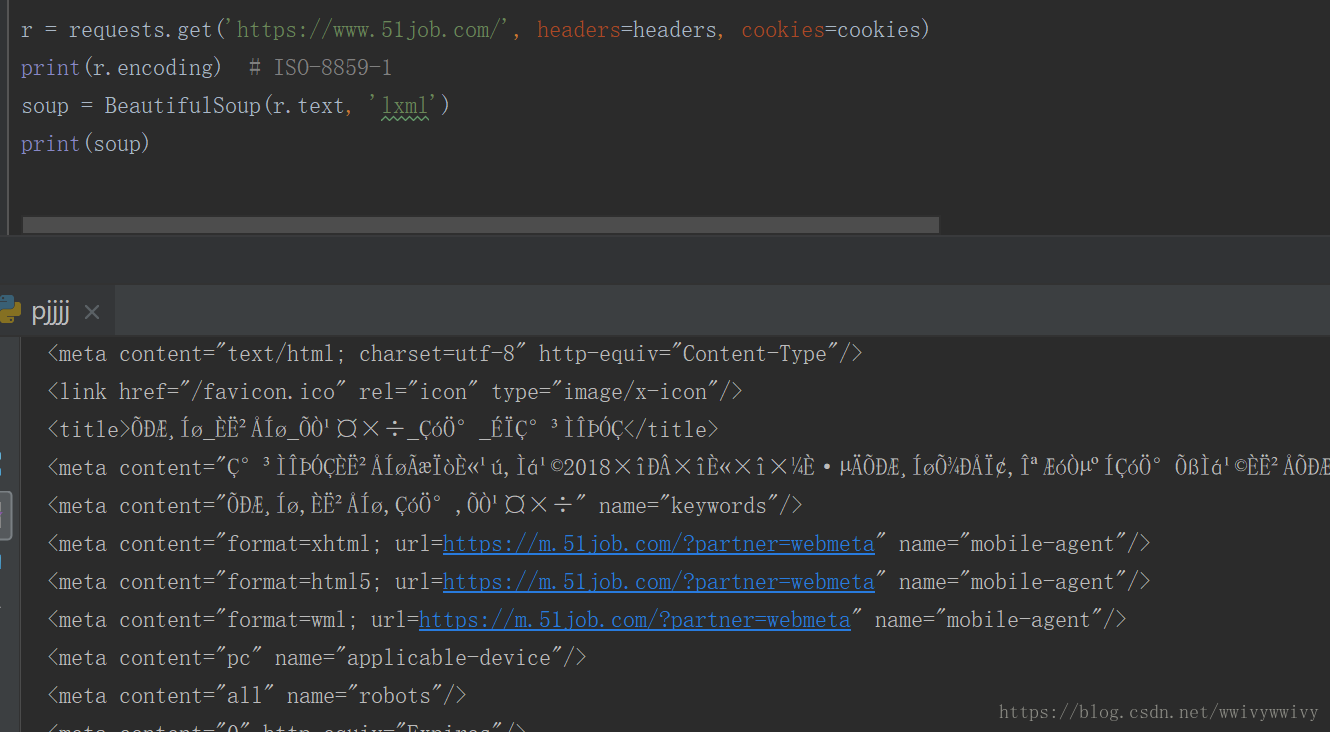
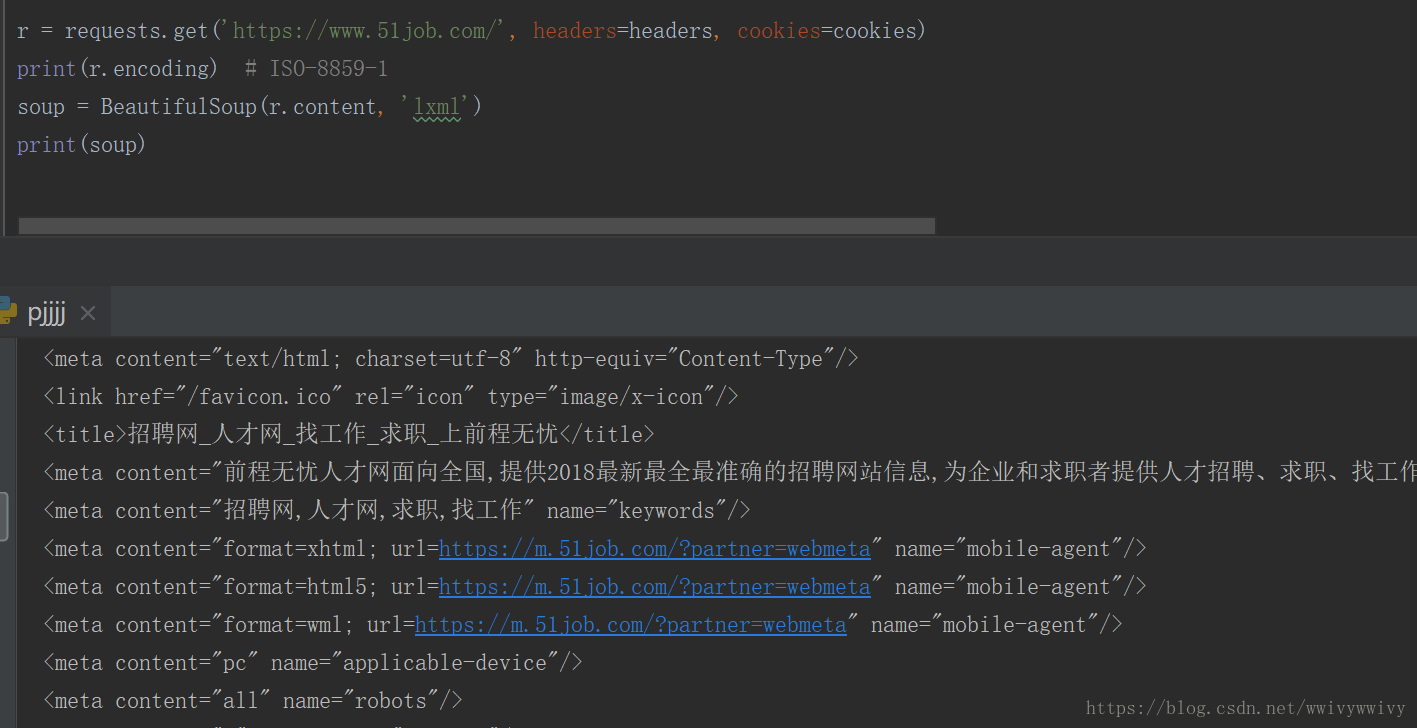
最近碰到个问题,用requests爬51job时候,发现中文乱码,传给bs的是r.text,排查发现r.encoding是 ISO-8859-1。
发现指定编码方式之后,可以正常显示。
# method 1
r = requests.get('https://www.51job.com/', headers=headers, cookies=cookies)
print(r.encoding) # ISO-8859-1
r.encoding = 'gbk' # 指定页面编码方式
soup = BeautifulSoup(r.text, 'lxml')
print(soup)- 或者直接传r.content也可以,记录一下这个问题。
# method 2
r = requests.get('https://www.51job.com/', headers=headers, cookies=cookies)
print(r.encoding) # ISO-8859-1
r.encoding = 'gbk' # 指定页面编码方式
soup = BeautifulSoup(r.text, 'lxml')
print(soup)