Struts2拦截器(Interceptor)
1. 理解拦截器
1.1. 什么是拦截器:
拦截器,在AOP(Aspect-Oriented Programming)中用于在某个方法或字段被访问之前,进行拦截然后在之前或之后加入某些操作。拦截是AOP的一种实现策略。
在Webwork的中文文档的解释为——拦截器是动态拦截Action调用的对象。它提供了一种机制可以使开发者可以定义在一个action执行的前后执行的代码,也可以在一个action执行前阻止其执行。同时也是提供了一种可以提取action中可重用的部分的方式。
谈到拦截器,还有一个词大家应该知道——拦截器链(Interceptor Chain,在Struts 2中称为拦截器栈Interceptor Stack)。拦截器链就是将拦截器按一定的顺序联结成一条链。在访问被拦截的方法或字段时,拦截器链中的拦截器就会按其之前定义的顺序被调用。
1.2. 拦截器的实现原理:
大部分时候,拦截器方法都是通过代理的方式来调用的。Struts 2的拦截器实现相对简单。当请求到达Struts 2的ServletDispatcher时,Struts 2会查找配置文件,并根据其配置实例化相对的拦截器对象,然后串成一个列表(list),最后一个一个地调用列表中的拦截器。如下图:
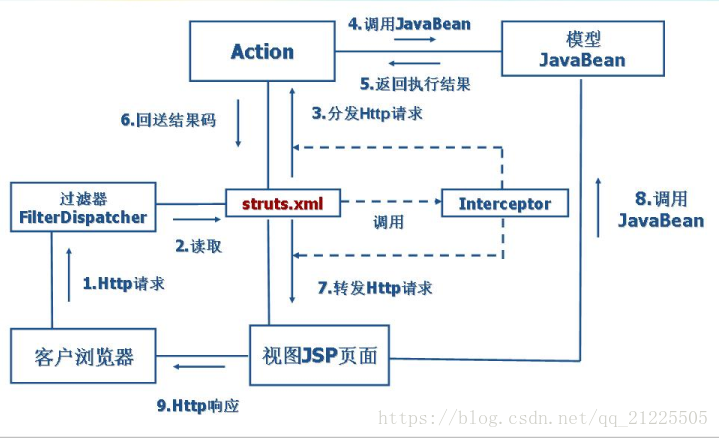
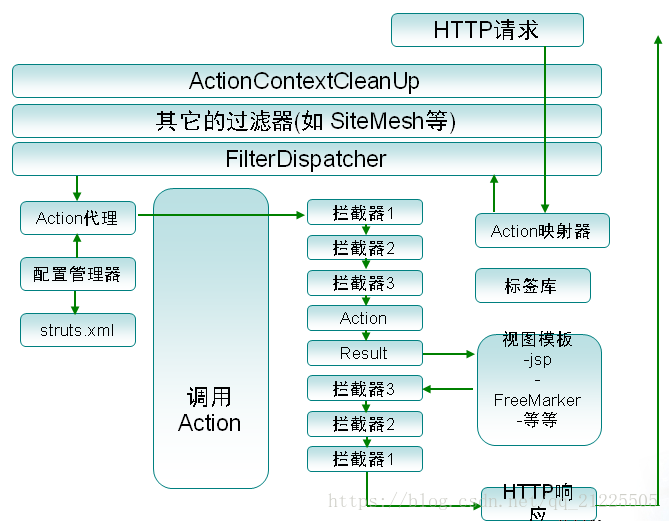
拦截器的工作原理如上图,每一个Action请求都包装在一系列的拦截器的内部。拦截器可以在Action执行直线做相似的操作也可以在Action执行直后做回收操作。
每一个Action既可以将操作转交给下面的拦截器,Action也可以直接退出操作返回客户既定的画面。
2. 拦截器的配置
Struts 2已经为您提供丰富多样的,功能齐全的拦截器实现。大家可以至struts2的jar包内的struts-default.xml查看关于默认的拦截器与拦截器链的配置。
Struts2(XWork)提供的拦截器的功能说明:
| 拦截器 |
名字 |
说明 |
| Alias Interceptor |
alias |
在不同请求之间将请求参数在不同名字件转换,请求内容不变 |
| Chaining Interceptor |
chain |
让前一个Action的属性可以被后一个Action访问,现在和chain类型的result(<result type=”chain”>)结合使用。 |
| Checkbox Interceptor |
checkbox |
添加了checkbox自动处理代码,将没有选中的checkbox的内容设定为false,而html默认情况下不提交没有选中的checkbox。 |
| Cookies Interceptor |
cookies |
使用配置的name,value来是指cookies |
| Conversion Error Interceptor |
conversionError |
将错误从ActionContext中添加到Action的属性字段中。 |
| Create Session Interceptor |
createSession |
自动的创建HttpSession,用来为需要使用到HttpSession的拦截器服务。 |
| Debugging Interceptor |
debugging |
提供不同的调试用的页面来展现内部的数据状况。 |
| Execute and Wait Interceptor |
execAndWait |
在后台执行Action,同时将用户带到一个中间的等待页面。 |
| Exception Interceptor |
exception |
将异常定位到一个画面 |
| File Upload Interceptor |
fileUpload |
提供文件上传功能 |
| I18n Interceptor |
i18n |
记录用户选择的locale |
| Logger Interceptor |
logger |
输出Action的名字 |
| Message Store Interceptor |
store |
存储或者访问实现ValidationAware接口的Action类出现的消息,错误,字段错误等。 |
| Model Driven Interceptor |
model-driven |
如果一个类实现了ModelDriven,将getModel得到的结果放在Value Stack中。 |
| Scoped Model Driven |
scoped-model-driven |
如果一个Action实现了ScopedModelDriven,则这个拦截器会从相应的Scope中取出model调用Action的setModel方法将其放入Action内部。 |
| Parameters Interceptor |
params |
将请求中的参数设置到Action中去。 |
| Prepare Interceptor |
prepare |
如果Acton实现了Preparable,则该拦截器调用Action类的prepare方法。 |
| Scope Interceptor |
scope |
将Action状态存入session和application的简单方法。 |
| Servlet Config Interceptor |
servletConfig |
提供访问HttpServletRequest和HttpServletResponse的方法,以Map的方式访问。 |
| Static Parameters Interceptor |
staticParams |
从struts.xml文件中将<action>中的<param>中的内容设置到对应的Action中。 |
| Roles Interceptor |
roles |
确定用户是否具有JAAS指定的Role,否则不予执行。 |
| Timer Interceptor |
timer |
输出Action执行的时间 |
| Token Interceptor |
token |
通过Token来避免双击 |
| Token Session Interceptor |
tokenSession |
和Token Interceptor一样,不过双击的时候把请求的数据存储在Session中 |
| Validation Interceptor |
validation |
使用action-validation.xml文件中定义的内容校验提交的数据。 |
| Workflow Interceptor |
workflow |
调用Action的validate方法,一旦有错误返回,重新定位到INPUT画面 |
| Parameter Filter Interceptor |
N/A |
从参数列表中删除不必要的参数 |
| Profiling Interceptor |
profiling |
通过参数激活profile |
在struts.xml文件中定义拦截器,拦截器栈:
<package name="my" extends="struts-default" namespace="/manage">
<interceptors>
<!-- 定义拦截器 -->
<interceptor name="拦截器名" class="拦截器实现类"/>
<!-- 定义拦截器栈 -->
<interceptor-stack name="拦截器栈名">
<interceptor-ref name="拦截器一"/>
<interceptor-ref name="拦截器二"/>
</interceptor-stack>
</interceptors>
......
</package>一旦定义了拦截器和拦截器栈后,就可以使用这个拦截器或拦截器栈来拦截Action了。拦截器的拦截行为将会在Action的exceute方法执行之前被执行。
<action name="userOpt" class="org.qiujy.web.struts2.action.UserAction">
<result name="success">/success.jsp</result>
<result name="error">/error.jsp</result>
<!-- 使用拦截器,一般配置在result之后, -->
<!-- 引用系统默认的拦截器 -->
<interceptor-ref name="defaultStack"/>
<interceptor-ref name="拦截器名或拦截器栈名"/>
</action>此处需要注意的是,如果为Action指定了一个拦截器,则系统默认的拦截器栈将会失去作用。为了继续使用默认拦截器,所以上面配置文件中手动引入了默认拦截器。
4. 自定义拦截器
作为“框架(framework)”,可扩展性是不可或缺的。虽然,Struts 2为我们提供如此丰富的拦截器实现,但是这并不意味我们失去创建自定义拦截器的能力,恰恰相反,在Struts 2自定义拦截器是相当容易的一件事。
4.1. 实现拦截器类:
所有的Struts 2的拦截器都直接或间接实现接口com.opensymphony.xwork2.interceptor.Interceptor。该接口提供了三个方法:
1) void init(); 在该拦截器被初始化之后,在该拦截器执行拦截之前,系统回调该方法。对于每个拦截器而言,此方法只执行一次。
2) void destroy();该方法跟init()方法对应。在拦截器实例被销毁之前,系统将回调该方法。
3) String intercept(ActionInvocation invocation) throws Exception; 该方法是用户需要实现的拦截动作。该方法会返回一个字符串作为逻辑视图。
除此之外,继承类com.opensymphony.xwork2.interceptor.AbstractInterceptor是更简单的一种实现拦截器类的方式,因为此类提供了init()和destroy()方法的空实现,这样我们只需要实现intercept方法。
4.2. 使用自定义拦截器:
自定义一个拦截器需要三步:
1 自定义一个实现Interceptor接口(或者继承自AbstractInterceptor)的类。
2 在strutx.xml中注册上一步中定义的拦截器。
3 在需要使用的Action中引用上述定义的拦截器,为了方便也可将拦截器定义为默认的拦截器,这样在不加特殊声明的情况下所有的Action都被这个拦截器拦截。
5. 自定义拦截器示例
5.1. 问题描述:
使用自定义拦截器来完成用户权限的控制:当浏览者需要请求执行某个操作时,应用需要先检查浏览者是否登录,以及是否有足够的权限来执行该操作。
5.2. 实现权限控制拦截器类:
package edu.cqupt.iactg.helper
import java.util.Map;
import org.apache.commons.fileupload.servlet.ServletRequestContext;
import org.apache.struts2.interceptor.SessionAware;
import com.opensymphony.xwork2.ActionContext;
import com.opensymphony.xwork2.ActionInvocation;
import com.opensymphony.xwork2.interceptor.Interceptor;
import edu.cqupt.iactg.action.UserAction;
public class UserInterceptor implements Interceptor {
private Map<String ,Object> session=null;//获得session
public static final String LOGIN="index";//全局返回值
public void destroy() {
System.out.println("拦截器销毁");
}
public void init() {
System.out.println("拦截器加载");
}
public String intercept(ActionInvocation actionInvocation) throws Exception {
System.out.println("进入拦截器");
//如果访问的是登陆acton则不需要对其拦截
if(actionInvocation.getAction() instanceof UserAction){
return actionInvocation.invoke();//执行其他的拦截器
}
session = actionInvocation.getInvocationContext().getSession(); // 从Invocation得到session对象
String user=(String) session.get("username");//得到session中的值
//如果存在该用户,放行
System.out.println(user);
if(user!=null&&!user.isEmpty()){
System.out.println("存在该用户");
return actionInvocation.invoke();
}else{
//如果不存在该用户
System.out.println("不存在该用户");
return LOGIN;//跳转到登陆页面
}
}
}
这里提出两个点1、返回值是一个String类型,如果返回的是invoke();则代表此拦截器已经放行,将执行下一个拦截器,否则返回一个字符串(一般是全局result)看下列代码
<package name="basic" abstract="true" extends="json-default">
<!-- 定义自己的拦截器 -->
<interceptors>
<!-- z指定改拦截器的位置 -->
<interceptor name="userInterceptor" class="edu.cqupt.iactg.helper.UserInterceptor"></interceptor>
<!-- 指定拦截器栈 -->
<interceptor-stack name="myStack">
<interceptor-ref name="defaultStack"></interceptor-ref><!-- Struts2自己提供的默认拦截器 -->
<interceptor-ref name="userInterceptor"></interceptor-ref><!-- 我们自己定义的拦截器 -->
</interceptor-stack>
</interceptors>
<!-- <default-interceptor-ref name="myStack"></default-interceptor-ref> --><!--设置为默认拦截器 -->
<global-results>
<result name="ERROR" type="redirectAction">disparter/error</result>
<result name="index" type="redirect">/</result><!-- 登陆界面地址 -->
</global-results>
<!-- 异常处理 -->
<global-exception-mappings>
<exception-mapping result="ERROR" exception="java.lang.Exception"/>
</global-exception-mappings>
</package>
现在我们就定义好了自己的代码了,我的拦截器定义时放在最终的一个父包里面的,如果要让继承该包的xml文件都使用这个拦截器就应该加上一条
<!-- <default-interceptor-ref name="myStack"></default-interceptor-ref> -->
如果不让所有的都这样的话可以这样,在要使用的的action下指定拦截器就行了:
<package name="disparter" namespace="/disparter" extends="basic">
<action name="main">
<interceptor-ref name="myStack"></interceptor-ref>
<result>/jsp/index_main.jsp</result>
</action>
<action name="home">
<interceptor-ref name="myStack"></interceptor-ref>
<result>/jsp/home.jsp</result>
</action>
<action name="index">
<result>index.jsp</result>
</action>
<action name="error">
<result>/jsp/error.html</result>
</action>
</package>
6、过滤器和拦截器的区别
相信大家读到这里有很多疑问了。Serlvet提供的过滤器和我们的拦截器有什么区别呢?
这里引用http://blog.sina.com.cn/s/blog_8bcfeeda010107q0.html的博客,写得很详细
过滤器,是在java web中,你传入的request,response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者struts的 action进行业务逻辑,比如过滤掉非法url(不是login.do的地址请求,如果用户没有登陆都过滤掉),或者在传入servlet或者 struts的action前统一设置字符集,或者去除掉一些非法字符
拦截器,是在面向切面编程的就是在你的service或者一个方法,前调用一个方法,或者在方法后调用一个方法比如动态代理就是拦截器的简单实现,在你调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在你调用方法后打印出字符串,甚至在你抛出异常的时候做业务逻辑的操作。
拦截器与过滤器的区别 :
- 拦截器是基于java的反射机制的,而过滤器是基于函数回调。
- 拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
- 拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
- 拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
- 在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次
执行顺序 :过滤前 - 拦截前 - Action处理 - 拦截后 - 过滤后。个人认为过滤是一个横向的过程,首先把客户端提交的内容进行过滤(例如未登录用户不能访问内部页面的处理);过滤通过后,拦截器将检查用户提交数据的验证,做一些前期的数据处理,接着把处理后的数据发给对应的Action;Action处理完成返回后,拦截器还可以做其他过程(还没想到要做啥),再向上返回到过滤器的后续操作。
面向切面编程(AOP是Aspect Oriented Program的首字母缩写) ,我们知道,面向对象的特点是继承、多态和封装。而封装就要求将功能分散到不同的对象中去,这在软件设计中往往称为职责分配。实际上也就是说,让不同的类设计不同的方法。这样代码就分散到一个个的类中去了。这样做的好处是降低了代码的复杂程度,使类可重用。
但是人们也发现,在分散代码的同时,也增加了代码的重复性。什么意思呢?比如说,我们在两个类中,可能都需要在每个方法中做日志。按面向对象的设计方法,我们就必须在两个类的方法中都加入日志的内容。也许他们是完全相同的,但就是因为面向对象的设计让类与类之间无法联系,而不能将这些重复的代码统一起来。
也许有人会说,那好办啊,我们可以将这段代码写在一个独立的类独立的方法里,然后再在这两个类中调用。但是,这样一来,这两个类跟我们上面提到的独立的类就有耦合了,它的改变会影响这两个类。那么,有没有什么办法,能让我们在需要的时候,随意地加入代码呢?这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程思想就是面向切面的编程。
一般而言,我们管切入到指定类指定方法的代码片段称为切面,而切入到哪些类、哪些方法则叫切入点。有了AOP,我们就可以把几个类共有的代码,抽取到一个切片中,等到需要时再切入对象中去,从而改变其原有的行为。
这样看来,AOP其实只是OOP的补充而已。OOP从横向上区分出一个个的类来,而AOP则从纵向上向对象中加入特定的代码。有了AOP,OOP变得立体了。如果加上时间维度,AOP使OOP由原来的二维变为三维了,由平面变成立体了。从技术上来说,AOP基本上是通过代理机制实现的。AOP在编程历史上可以说是里程碑式的,对OOP编程是一种十分有益的补充。