1.TCP的黏包问题如何处理?
1 什么是粘包现象
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
2 为什么出现粘包现象
(1)发送方原因
我们知道,TCP默认会使用Nagle算法。而Nagle算法主要做两件事:1)只有上一个分组得到确认,才会发送下一个分组;2)收集多个小分组,在一个确认到来时一起发送。
所以,正是Nagle算法造成了发送方有可能造成粘包现象。
(2)接收方原因
TCP接收到分组时,并不会立刻送至应用层处理,或者说,应用层并不一定会立即处理;实际上,TCP将收到的分组保存至接收缓存里,然后应用程序主动从缓存里读收到的分组。这样一来,如果TCP接收分组的速度大于应用程序读分组的速度,多个包就会被存至缓存,应用程序读时,就会读到多个首尾相接粘到一起的包。
3 什么时候需要处理粘包现象
(1)如果发送方发送的多个分组本来就是同一个数据的不同部分,比如一个很大的文件被分成多个分组发送,这时,当然不需要处理粘包的现象;
(2)但如果多个分组本毫不相干,甚至是并列的关系,我们就一定要处理粘包问题了。比如,我当时要接收的每个分组都是一个有固定格式的商品信息,如果不处理粘包问题,每个读进来的分组我只会处理最前边的那个商品,后边的就会被丢弃。这显然不是我要的结果。
4 如何处理粘包现象
(1)发送方
对于发送方造成的粘包现象,我们可以通过关闭Nagle算法来解决,使用TCP_NODELAY选项来关闭Nagle算法。
(2)接收方
遗憾的是TCP并没有处理接收方粘包现象的机制,我们只能在应用层进行处理。
(3)应用层处理
应用层的处理简单易行!并且不仅可以解决接收方造成的粘包问题,还能解决发送方造成的粘包问题。
解决方法就是循环处理:应用程序在处理从缓存读来的分组时,读完一条数据时,就应该循环读下一条数据,直到所有的数据都被处理;但是如何判断每条数据的长度呢?
两种途径:
1)格式化数据:每条数据有固定的格式(开始符、结束符),这种方法简单易行,但选择开始符和结束符的时候一定要注意每条数据的内部一定不能出现开始符或结束符;
2)发送长度:发送每条数据的时候,将数据的长度一并发送,比如可以选择每条数据的前4位是数据的长度,应用层处理时可以根据长度来判断每条数据的开始和结束。
2.Linux中如何进行同步?
参考博客:https://blog.csdn.net/jkx01whg/article/details/78119189
3.常用锁介绍?
mutex(互斥锁):
互斥锁主要用于实现内核中的互斥访问功能。对它的访问必须遵循一些规则:同一时间只能有一个任务持有互斥锁,而且只有这个任务可以对互斥锁进行解锁。互斥锁不能进行递归锁定或解锁。
semaphore (信号量):
信号量在创建时需要设置一个初始值,表示同时可以有几个任务可以访问该信号量保护的共享资源,初始值为1就变成互斥锁(Mutex),即同时只能有一个任务可以访问信号量保护的共享资源。一个任务要想访问共享资源,首先必须得到信号量,获取信号量的操作将把信号量的值减1,若当前信号量的值为负数,表明无法获得信号量,该任务必须挂起在该信号量的等待队列等待该信号量可用;若当前信号量的值为非负数,表示可以获得信号量,因而可以立刻访问被该信号量保护的共享资源。当任务访问完被信号量保护的共享资源后,必须释放信号量,释放信号量通过把信号量的值加1实现,如果信号量的值为非正数,表明有任务等待当前信号量,因此它也唤醒所有等待该信号量的任务。
rw_semaphore (读写信号量):
读写信号量对访问者进行了细分,或者为读者,或者为写者,读者在保持读写信号量期间只能对该读写信号量保护的共享资源进行读访问,如果一个任务除了需要读,可能还需要写,那么它必须被归类为写者,它在对共享资源访问之前必须先获得写者身份,写者在发现自己不需要写访问的情况下可以降级为读者。读写信号量同时拥有的读者数不受限制,也就说可以有任意多个读者同时拥有一个读写信号量。如果一个读写信号量当前没有被写者拥有并且也没有写者等待读者释放信号量,那么任何读者都可以成功获得该读写信号量;否则,读者必须被挂起直到写者释放该信号量。如果一个读写信号量当前没有被读者或写者拥有并且也没有写者等待该信号量,那么一个写者可以成功获得该读写信号量,否则写者将被挂起,直到没有任何访问者。因此,写者是排他性的,独占性的。
Spanlock(自旋锁):
自旋锁与互斥锁有点类似,只是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。
信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用(_trylock的变种能够在中断上下文使用),而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。如果被保护的共享资源只在进程上下文访问,使用信号量保护该共享资源非常合适,如果对共巷资源的访问时间非常短,自旋锁也可以。但是如果被保护的共享资源需要在中断上下文访问(包括底半部即中断处理句柄和顶半部即软中断),就必须使用自旋锁。
自旋锁保持期间是抢占失效的,而信号量和读写信号量保持期间是可以被抢占的。自旋锁只有在内核可抢占或SMP的情况下才真正需要,在单CPU且不可抢占的内核下,自旋锁的所有操作都是空操作。
跟互斥锁一样,一个执行单元要想访问被自旋锁保护的共享资源,必须先得到锁,在访问完共享资源后,必须释放锁。如果在获取自旋锁时,没有任何执行单元保持该锁,那么将立即得到锁;如果在获取自旋锁时锁已经有保持者,那么获取锁操作将自旋在那里,直到该自旋锁的保持者释放了锁。
无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。
区别?
信号量。互斥锁允许进程sleep属于睡眠锁,自旋锁不允许调用者sleep,而是让其循环等待,所以有以下区别应用:
- 信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因而自旋锁适合于保持时间非常短的情况;
- 自旋锁可以用于中断,不能用于进程上下文(会引起死锁),而信号量不允许使用在中断中,而可以用于进程上下文;
- 自旋锁保持期间是抢占失效的,自旋锁被持有时,内核不能被抢占,而信号量和读写信号量保持期间是可以被抢占的。
另外需要注意的是:
- 信号量锁保护的临界区可包含可能引起阻塞的代码,而自旋锁则绝对要避免用来保护包含这样代码的临界区,因为阻塞意味着要进行进程的切换,如果进程被切换出去后,另一进程企图获取本自旋锁,死锁就会发生;
- 占用信号量的同时不能占用自旋锁,因为在等待信号量时可能会睡眠,而在持有自旋锁时是不允许睡眠的。
信号量和互斥锁的区别
1、概念上的区别:
信号量:是进程间(线程间)同步用的,一个进程(线程)完成了某一个动作就通过信号量告诉别的进程(线程),别的进程(线程)再进行某些动作。有二值和多值信号量之分;
互斥锁:是线程间互斥用的,一个线程占用了某一个共享资源,那么别的线程就无法访问,直到这个线程离开,其他的线程才开始可以使用这个共享资源。可以把互斥锁看成二值信号量。
2、上锁时:
信号量: 只要信号量的value大于0,其他线程就可以sem_wait成功,成功后信号量的value减一。若value值不大于0,则sem_wait阻塞,直到sem_post释放后value值加一。一句话,信号量的value>=0。
互斥锁: 只要被锁住,其他任何线程都不可以访问被保护的资源。如果没有锁,获得资源成功,否则进行阻塞等待资源可用。一句话,线程互斥锁的vlaue可以为负数。
3、使用场所:
信号量主要适用于进程间通信,当然,也可用于线程间通信。而互斥锁只能用于线程间通信。
由此,可以总结出自旋锁和信号量选用的3个原则:
1:当锁不能获取到时,使用信号量的开销就是进程上线文切换的时间Tc,使用自旋锁的开销就是等待自旋锁(由临界区执行的时间决定)Ts,如果Ts比较小时,应使用自旋锁比较好,如果Ts比较大,应使用信号量。
2:信号量所保护的临界区可包含可能引起阻塞的代码,而自旋锁绝对要避免用来保护包含这样的代码的临界区,因为阻塞意味着要进行进程间的切换,如果进程被切换出去后,另一个进程企图获取本自旋锁,死锁就会发生。
3:信号量存在于进程上下文,因此,如果被保护的共享资源需要在中断或软中断情况下使用,则在信号量和自旋锁之间只能选择自旋锁,当然,如果一定要是要那个信号量,则只能通过down_trylock()方式进行,不能获得就立即返回以避免阻塞
4.Linux下epool和select的区别
在linux 没有实现epoll事件驱动机制之前,我们一般选择用select或者poll等IO多路复用的方法来实现并发服务程序。在大数据、高并发、集群等一些名词唱得火热之年代,select和poll的用武之地越来越有限,风头已经被epoll占尽。
本文便来介绍epoll的实现机制,并附带讲解一下select和poll。通过对比其不同的实现机制,真正理解为何epoll能实现高并发。
select()和poll() IO多路复用模型
select的缺点:
- 单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在linux内核头文件中,有这样的定义:#define __FD_SETSIZE 1024)
- 内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销;
- select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
因此,该epoll上场了。
epoll IO多路复用模型实现机制
由于epoll的实现机制与select/poll机制完全不同,上面所说的 select的缺点在epoll上不复存在。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树)。把原先的select/poll调用分成了3个部分:
1)调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字
3)调用epoll_wait收集发生的事件的连接
如此一来,要实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这个epoll对象中添加或者删除连接。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有一股脑的向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接。
下面来看看Linux内核具体的epoll机制实现思路。
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
-
struct eventpoll{ -
.... -
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/ -
struct rb_root rbr; -
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/ -
struct list_head rdlist; -
.... -
};
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
-
struct epitem{ -
struct rb_node rbn;//红黑树节点 -
struct list_head rdllink;//双向链表节点 -
struct epoll_filefd ffd; //事件句柄信息 -
struct eventpoll *ep; //指向其所属的eventpoll对象 -
struct epoll_event event; //期待发生的事件类型 -
}
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。

epoll数据结构示意图
从上面的讲解可知:通过红黑树和双链表数据结构,并结合回调机制,造就了epoll的高效。
OK,讲解完了Epoll的机理,我们便能很容易掌握epoll的用法了。一句话描述就是:三步曲。
第一步:epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄来标识。
第二步:epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。
第三部:epoll_wait()系统调用。通过此调用收集收集在epoll监控中已经发生的事件。
最后,附上一个epoll编程实例。(作者为sparkliang)
-
// -
// a simple echo server using epoll in linux -
// -
// 2009-11-05 -
// 2013-03-22:修改了几个问题,1是/n格式问题,2是去掉了原代码不小心加上的ET模式; -
// 本来只是简单的示意程序,决定还是加上 recv/send时的buffer偏移 -
// by sparkling -
// -
#include <sys/socket.h> -
#include <sys/epoll.h> -
#include <netinet/in.h> -
#include <arpa/inet.h> -
#include <fcntl.h> -
#include <unistd.h> -
#include <stdio.h> -
#include <errno.h> -
#include <iostream> -
using namespace std; -
#define MAX_EVENTS 500 -
struct myevent_s -
{ -
int fd; -
void (*call_back)(int fd, int events, void *arg); -
int events; -
void *arg; -
int status; // 1: in epoll wait list, 0 not in -
char buff[128]; // recv data buffer -
int len, s_offset; -
long last_active; // last active time -
}; -
// set event -
void EventSet(myevent_s *ev, int fd, void (*call_back)(int, int, void*), void *arg) -
{ -
ev->fd = fd; -
ev->call_back = call_back; -
ev->events = 0; -
ev->arg = arg; -
ev->status = 0; -
bzero(ev->buff, sizeof(ev->buff)); -
ev->s_offset = 0; -
ev->len = 0; -
ev->last_active = time(NULL); -
} -
// add/mod an event to epoll -
void EventAdd(int epollFd, int events, myevent_s *ev) -
{ -
struct epoll_event epv = {0, {0}}; -
int op; -
epv.data.ptr = ev; -
epv.events = ev->events = events; -
if(ev->status == 1){ -
op = EPOLL_CTL_MOD; -
} -
else{ -
op = EPOLL_CTL_ADD; -
ev->status = 1; -
} -
if(epoll_ctl(epollFd, op, ev->fd, &epv) < 0) -
printf("Event Add failed[fd=%d], evnets[%d]\n", ev->fd, events); -
else -
printf("Event Add OK[fd=%d], op=%d, evnets[%0X]\n", ev->fd, op, events); -
} -
// delete an event from epoll -
void EventDel(int epollFd, myevent_s *ev) -
{ -
struct epoll_event epv = {0, {0}}; -
if(ev->status != 1) return; -
epv.data.ptr = ev; -
ev->status = 0; -
epoll_ctl(epollFd, EPOLL_CTL_DEL, ev->fd, &epv); -
} -
int g_epollFd; -
myevent_s g_Events[MAX_EVENTS+1]; // g_Events[MAX_EVENTS] is used by listen fd -
void RecvData(int fd, int events, void *arg); -
void SendData(int fd, int events, void *arg); -
// accept new connections from clients -
void AcceptConn(int fd, int events, void *arg) -
{ -
struct sockaddr_in sin; -
socklen_t len = sizeof(struct sockaddr_in); -
int nfd, i; -
// accept -
if((nfd = accept(fd, (struct sockaddr*)&sin, &len)) == -1) -
{ -
if(errno != EAGAIN && errno != EINTR) -
{ -
} -
printf("%s: accept, %d", __func__, errno); -
return; -
} -
do -
{ -
for(i = 0; i < MAX_EVENTS; i++) -
{ -
if(g_Events[i].status == 0) -
{ -
break; -
} -
} -
if(i == MAX_EVENTS) -
{ -
printf("%s:max connection limit[%d].", __func__, MAX_EVENTS); -
break; -
} -
// set nonblocking -
int iret = 0; -
if((iret = fcntl(nfd, F_SETFL, O_NONBLOCK)) < 0) -
{ -
printf("%s: fcntl nonblocking failed:%d", __func__, iret); -
break; -
} -
// add a read event for receive data -
EventSet(&g_Events[i], nfd, RecvData, &g_Events[i]); -
EventAdd(g_epollFd, EPOLLIN, &g_Events[i]); -
}while(0); -
printf("new conn[%s:%d][time:%d], pos[%d]\n", inet_ntoa(sin.sin_addr), -
ntohs(sin.sin_port), g_Events[i].last_active, i); -
} -
// receive data -
void RecvData(int fd, int events, void *arg) -
{ -
struct myevent_s *ev = (struct myevent_s*)arg; -
int len; -
// receive data -
len = recv(fd, ev->buff+ev->len, sizeof(ev->buff)-1-ev->len, 0); -
EventDel(g_epollFd, ev); -
if(len > 0) -
{ -
ev->len += len; -
ev->buff[len] = '\0'; -
printf("C[%d]:%s\n", fd, ev->buff); -
// change to send event -
EventSet(ev, fd, SendData, ev); -
EventAdd(g_epollFd, EPOLLOUT, ev); -
} -
else if(len == 0) -
{ -
close(ev->fd); -
printf("[fd=%d] pos[%d], closed gracefully.\n", fd, ev-g_Events); -
} -
else -
{ -
close(ev->fd); -
printf("recv[fd=%d] error[%d]:%s\n", fd, errno, strerror(errno)); -
} -
} -
// send data -
void SendData(int fd, int events, void *arg) -
{ -
struct myevent_s *ev = (struct myevent_s*)arg; -
int len; -
// send data -
len = send(fd, ev->buff + ev->s_offset, ev->len - ev->s_offset, 0); -
if(len > 0) -
{ -
printf("send[fd=%d], [%d<->%d]%s\n", fd, len, ev->len, ev->buff); -
ev->s_offset += len; -
if(ev->s_offset == ev->len) -
{ -
// change to receive event -
EventDel(g_epollFd, ev); -
EventSet(ev, fd, RecvData, ev); -
EventAdd(g_epollFd, EPOLLIN, ev); -
} -
} -
else -
{ -
close(ev->fd); -
EventDel(g_epollFd, ev); -
printf("send[fd=%d] error[%d]\n", fd, errno); -
} -
} -
void InitListenSocket(int epollFd, short port) -
{ -
int listenFd = socket(AF_INET, SOCK_STREAM, 0); -
fcntl(listenFd, F_SETFL, O_NONBLOCK); // set non-blocking -
printf("server listen fd=%d\n", listenFd); -
EventSet(&g_Events[MAX_EVENTS], listenFd, AcceptConn, &g_Events[MAX_EVENTS]); -
// add listen socket -
EventAdd(epollFd, EPOLLIN, &g_Events[MAX_EVENTS]); -
// bind & listen -
sockaddr_in sin; -
bzero(&sin, sizeof(sin)); -
sin.sin_family = AF_INET; -
sin.sin_addr.s_addr = INADDR_ANY; -
sin.sin_port = htons(port); -
bind(listenFd, (const sockaddr*)&sin, sizeof(sin)); -
listen(listenFd, 5); -
} -
int main(int argc, char **argv) -
{ -
unsigned short port = 12345; // default port -
if(argc == 2){ -
port = atoi(argv[1]); -
} -
// create epoll -
g_epollFd = epoll_create(MAX_EVENTS); -
if(g_epollFd <= 0) printf("create epoll failed.%d\n", g_epollFd); -
// create & bind listen socket, and add to epoll, set non-blocking -
InitListenSocket(g_epollFd, port); -
// event loop -
struct epoll_event events[MAX_EVENTS]; -
printf("server running:port[%d]\n", port); -
int checkPos = 0; -
while(1){ -
// a simple timeout check here, every time 100, better to use a mini-heap, and add timer event -
long now = time(NULL); -
for(int i = 0; i < 100; i++, checkPos++) // doesn't check listen fd -
{ -
if(checkPos == MAX_EVENTS) checkPos = 0; // recycle -
if(g_Events[checkPos].status != 1) continue; -
long duration = now - g_Events[checkPos].last_active; -
if(duration >= 60) // 60s timeout -
{ -
close(g_Events[checkPos].fd); -
printf("[fd=%d] timeout[%d--%d].\n", g_Events[checkPos].fd, g_Events[checkPos].last_active, now); -
EventDel(g_epollFd, &g_Events[checkPos]); -
} -
} -
// wait for events to happen -
int fds = epoll_wait(g_epollFd, events, MAX_EVENTS, 1000); -
if(fds < 0){ -
printf("epoll_wait error, exit\n"); -
break; -
} -
for(int i = 0; i < fds; i++){ -
myevent_s *ev = (struct myevent_s*)events[i].data.ptr; -
if((events[i].events&EPOLLIN)&&(ev->events&EPOLLIN)) // read event -
{ -
ev->call_back(ev->fd, events[i].events, ev->arg); -
} -
if((events[i].events&EPOLLOUT)&&(ev->events&EPOLLOUT)) // write event -
{ -
ev->call_back(ev->fd, events[i].events, ev->arg); -
} -
} -
} -
// free resource -
return 0;
类似博客参考:https://www.cnblogs.com/Anker/p/3265058.html
5.Linux下的内存分配和管理
一、进程与内存
所有进程(执行的程序)都必须占用一定数量的内存,它或是用来存放从磁盘载入的程序代码,或是存放取自用户输入的数据等等。不过进程对这些内存的管理方式因内存用途不一而不尽相同,有些内存是事先静态分配和统一回收的,而有些却是按需要动态分配和回收的。对任何一个普通进程来讲,它都会涉及到5种不同的数据段;
-
代码段:代码段是用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作——它是不可写的。
-
数据段:数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
-
BSS段:BSS段包含了程序中未初始化的全局变量,在内存中 bss段全部置零。
-
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
-
栈:栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
上述几种内存区域中数据段、BSS和堆通常是被连续存储的——内存位置上是连续的,而代码段和栈往往会被独立存放。有趣的是,堆和栈两个区域关系很“暧昧”,他们一个向下“长”(i386体系结构中栈向下、堆向上),一个向上“长”,相对而生。但你不必担心他们会碰头,因为他们之间间隔很大(到底大到多少,你可以从下面的例子程序计算一下),绝少有机会能碰到一起。
[cpp] view plain copy
- #include<stdio.h>
- #include<malloc.h>
- #include<unistd.h>
- int bss_var;
- int data_var0=1;
- int main(int argc,char **argv)
- {
- printf("below are addresses of types of process's mem\n");
- printf("Text location:\n");
- printf("\tAddress of main(Code Segment):%p\n",main);
- printf("____________________________\n");
- int stack_var0=2;
- printf("Stack Location:\n");
- printf("\tInitial end of stack:%p\n",&stack_var0);
- int stack_var1=3;
- printf("\tnew end of stack:%p\n",&stack_var1);
- printf("____________________________\n");
- printf("Data Location:\n");
- printf("\tAddress of data_var(Data Segment):%p\n",&data_var0);
- static int data_var1=4;
- printf("\tNew end of data_var(Data Segment):%p\n",&data_var1);
- printf("____________________________\n");
- printf("BSS Location:\n");
- printf("\tAddress of bss_var:%p\n",&bss_var);
- printf("____________________________\n");
- char *b = sbrk((ptrdiff_t)0);
- printf("Heap Location:\n");
- printf("\tInitial end of heap:%p\n",b);
- brk(b+4);
- b=sbrk((ptrdiff_t)0);
- printf("\tNew end of heap:%p\n",b);
- return 0;
- }
它的结果如下
below are addresses of types of process's mem
Text location:
Address of main(Code Segment):0x8048388
____________________________
Stack Location:
Initial end of stack:0xbffffab4
new end of stack:0xbffffab0
____________________________
Data Location:
Address of data_var(Data Segment):0x8049758
New end of data_var(Data Segment):0x804975c
____________________________
BSS Location:
Address of bss_var:0x8049864
____________________________
Heap Location:
Initial end of heap:0x8049868
New end of heap:0x804986c
利用size命令也可以看到程序的各段大小,比如执行size example会得到
text data bss dechex filename
1654 280 8 1942 796 example
但这些数据是程序编译的静态统计,而上面显示的是进程运行时的动态值,但两者是对应的。
从用户向内核看,所使用的内存表象形式会依次经历“逻辑地址”——“线性地址”——“物理地址”几种形式(关于这三者的解释)
逻辑地址经段机制转化成线性地址;线性地址又经过页机制转化为物理地址。(但是我们要知道Linux系统虽然保留了段机制,但是将所有程序的段地址都定死为0-4G,所以虽然逻辑地址和线性地址是两种不同的地址空间,但在linux中逻辑地址就等于线性地址,它们的值是一样的)
二、虚拟内存空间
Linux操作系统采用虚拟内存管理技术,使得每个进程都有各自互不干涉的进程地址空间。该空间是块大小为4G的线性虚拟空间,用户所看到和接触到的都是该虚拟地址,无法看到实际的物理内存地址。利用这种虚拟地址不但能起到保护操作系统的效果(用户不能直接访问物理内存),而且更重要的是,用户程序可使用比实际物理内存更大的地址空间(具体的原因请看硬件基础部分)。
在讨论进程空间细节前,这里先要澄清下面几个问题:
- 第一、4G的进程地址空间被人为的分为两个部分——用户空间与内核空间。用户空间从0到3G(0xC0000000),内核空间占据3G到4G。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
- 第二、用户空间对应进程,所以每当进程切换,用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程改变,是固定的。内核空间地址有自己对应的页表(init_mm.pgd),用户进程各自有不同的页表。
- 第三、每个进程的用户空间都是完全独立、互不相干的。不信的话,你可以把上面的程序同时运行10次(当然为了同时运行,让它们在返回前一同睡眠100秒吧),你会看到10个进程占用的线性地址一模一样。
1)进程内存管理
进程内存管理的对象是进程线性地址空间上的内存镜像,这些内存镜像其实就是进程使用的虚拟内存区域(memory region)。进程虚拟空间是个32或64位的“平坦”(独立的连续区间)地址空间(空间的具体大小取决于体系结构)。要统一管理这么大的平坦空间可绝非易事,为了方便管理,虚拟空间被划分为许多大小可变的(但必须是4096的倍数)内存区域,这些区域在进程线性地址中像停车位一样有序排列。这些区域的划分原则是“将访问属性一致的地址空间存放在一起”,所谓访问属性在这里无非指的是“可读、可写、可执行等”。
如果你要查看某个进程占用的内存区域,可以使用命令cat /proc/<pid>/maps获得(pid是进程号,你可以运行上面我们给出的例子——./example &;pid便会打印到屏幕),你可以发现很多类似于下面的数字信息。
由于程序example使用了动态库,所以除了example本身使用的的内存区域外,还会包含那些动态库使用的内存区域(区域顺序是:代码段、数据段、bss段)。
我们下面只抽出和example有关的信息,除了前两行代表的代码段和数据段外,最后一行是进程使用的栈空间。
-------------------------------------------------------------------------------
08048000 - 08049000 r-xp 00000000 03:03 439029 /home/mm/src/example
08049000 - 0804a000 rw-p00000000 03:03 439029 /home/mm/src/example
……………
bfffe000 - c0000000 rwxpffff000 00:00 0
----------------------------------------------------------------------------------------------------------------------
每行数据格式如下:
(内存区域)开始-结束 访问权限 偏移 主设备号:次设备号 i节点 文件。
注意,你一定会发现进程空间只包含三个内存区域,似乎没有上面所提到的堆、bss等,其实并非如此,程序内存段和进程地址空间中的内存区域是种模糊对应,也就是说,堆、bss、数据段(初始化过的)都在进程空间中由数据段内存区域表示。
在Linux内核中对应进程内存区域的数据结构是: vm_area_struct, 内核将每个内存区域作为一个单独的内存对象管理,相应的操作也都一致。采用面向对象方法使VMA结构体可以代表多种类型的内存区域--比如内存映射文件或进程的用户空间栈等,对这些区域的操作也都不尽相同。
vm_area_strcut结构比较复杂,关于它的详细结构请参阅相关资料。我们这里只对它的组织方法做一点补充说明。vm_area_struct是描述进程地址空间的基本管理单元,对于一个进程来说往往需要多个内存区域来描述它的虚拟空间,如何关联这些不同的内存区域呢?大家可能都会想到使用链表,的确vm_area_struct结构确实是以链表形式链接,不过为了方便查找,内核又以红黑树(以前的内核使用平衡树)的形式组织内存区域,以便降低搜索耗时。并存的两种组织形式,并非冗余:链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域的时候。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
下图反映了进程地址空间的管理模型:

进程的地址空间对应的描述结构是“内存描述符结构”,它表示进程的全部地址空间,——包含了和进程地址空间有关的全部信息,其中当然包含进程的内存区域。
三、系统物理内存管理
1)物理内存管理
Linux内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数个4k(在i386体系结构中)大小的页,从而分配和回收内存的基本单位便是内存页了。利用分页管理有助于灵活分配内存地址,因为分配时不必要求必须有大块的连续内存,系统可以东一页、西一页的凑出所需要的内存供进程使用。虽然如此,但是实际上系统使用内存时还是倾向于分配连续的内存块,因为分配连续内存时,页表不需要更改,因此能降低TLB的刷新率(频繁刷新会在很大程度上降低访问速度)。
鉴于上述需求,内核分配物理页面时为了尽量减少不连续情况,采用了“伙伴”关系来管理空闲页面(内存分配-----伙伴算法和slab算法)。伙伴关系分配算法大家应该不陌生——几乎所有操作系统方面的书都会提到,我们不去详细说它了,如果不明白可以参看有关资料。这里只需要大家明白Linux中空闲页面的组织和管理利用了伙伴关系,因此空闲页面分配时也需要遵循伙伴关系,最小单位只能是2的幂倍页面大小。内核中分配空闲页面的基本函数是get_free_page/get_free_pages,它们或是分配单页或是分配指定的页面(2、4、8…512页)。
注意:get_free_page是在内核中分配内存,不同于malloc在用户空间中分配,malloc利用堆动态分配,实际上是调用brk()系统调用,该调用的作用是扩大或缩小进程堆空间(它会修改进程的brk域)。如果现有的内存区域不够容纳堆空间,则会以页面大小的倍数为单位,扩张或收缩对应的内存区域,但brk值并非以页面大小为倍数修改,而是按实际请求修改。因此Malloc在用户空间分配内存可以以字节为单位分配,但内核在内部仍然会是以页为单位分配的。
另外,需要提及的是,物理页在系统中由页结构struct page描述,系统中所有的页面都存储在数组mem_map[]中,可以通过该数组找到系统中的每一页(空闲或非空闲)。而其中的空闲页面则可由上述提到的以伙伴关系组织的空闲页链表(free_area[MAX_ORDER])来索引。
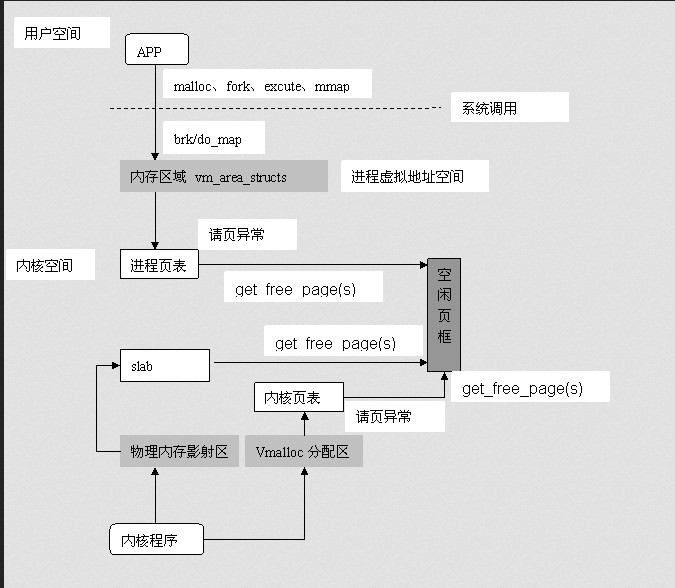
2)内核内存使用
- Slab
所谓尺有所长,寸有所短。以页为最小单位分配内存对于内核管理系统中的物理内存来说的确比较方便,但内核自身最常使用的内存却往往是很小(远远小于一页)的内存块——比如存放文件描述符、进程描述符、虚拟内存区域描述符等行为所需的内存都不足一页。这些用来存放描述符的内存相比页面而言,就好比是面包屑与面包。一个整页中可以聚集多个这些小块内存;而且这些小块内存块也和面包屑一样频繁地生成/销毁。
为了满足内核对这种小内存块的需要,Linux系统采用了一种被称为slab分配器的技术。Slab分配器的实现相当复杂,但原理不难,其核心思想就是“存储池”的运用。内存片段(小块内存)被看作对象,当被使用完后,并不直接释放而是被缓存到“存储池”里,留做下次使用,这无疑避免了频繁创建与销毁对象所带来的额外负载。
Slab技术不但避免了内存内部分片(下文将解释)带来的不便(引入Slab分配器的主要目的是为了减少对伙伴系统分配算法的调用次数——频繁分配和回收必然会导致内存碎片——难以找到大块连续的可用内存),而且可以很好地利用硬件缓存提高访问速度。
Slab并非是脱离伙伴关系而独立存在的一种内存分配方式,slab仍然是建立在页面基础之上,换句话说,Slab将页面(来自于伙伴关系管理的空闲页面链表)撕碎成众多小内存块以供分配,slab中的对象分配和销毁使用kmem_cache_alloc与kmem_cache_free。
- Kmalloc
Slab分配器不仅仅只用来存放内核专用的结构体,它还被用来处理内核对小块内存的请求。当然鉴于Slab分配器的特点,一般来说内核程序中对小于一页的小块内存的请求才通过Slab分配器提供的接口Kmalloc来完成(虽然它可分配32 到131072字节的内存)。从内核内存分配的角度来讲,kmalloc可被看成是get_free_page(s)的一个有效补充,内存分配粒度更灵活了。
有兴趣的话,可以到/proc/slabinfo中找到内核执行现场使用的各种slab信息统计,其中你会看到系统中所有slab的使用信息。从信息中可以看到系统中除了专用结构体使用的slab外,还存在大量为Kmalloc而准备的Slab(其中有些为dma准备的)。
- 内核非连续内存分配(Vmalloc)
伙伴关系也好、slab技术也好,从内存管理理论角度而言目的基本是一致的,它们都是为了防止“分片”,不过分片又分为外部分片和内部分片之说,所谓内部分片是说系统为了满足一小段内存区(连续)的需要,不得不分配了一大区域连续内存给它,从而造成了空间浪费;外部分片是指系统虽有足够的内存,但却是分散的碎片,无法满足对大块“连续内存”的需求。无论何种分片都是系统有效利用内存的障碍。slab分配器使得一个页面内包含的众多小块内存可独立被分配使用,避免了内部分片,节约了空闲内存。伙伴关系把内存块按大小分组管理,一定程度上减轻了外部分片的危害,因为页框分配不在盲目,而是按照大小依次有序进行,不过伙伴关系只是减轻了外部分片,但并未彻底消除。你自己比划一下多次分配页面后,空闲内存的剩余情况吧。
所以避免外部分片的最终思路还是落到了如何利用不连续的内存块组合成“看起来很大的内存块”——这里的情况很类似于用户空间分配虚拟内存,内存逻辑上连续,其实映射到并不一定连续的物理内存上。Linux内核借用了这个技术,允许内核程序在内核地址空间中分配虚拟地址,同样也利用页表(内核页表)将虚拟地址映射到分散的内存页上。以此完美地解决了内核内存使用中的外部分片问题。内核提供vmalloc函数分配内核虚拟内存,该函数不同于kmalloc,它可以分配较Kmalloc大得多的内存空间(可远大于128K,但必须是页大小的倍数),但相比Kmalloc来说,Vmalloc需要对内核虚拟地址进行重映射,必须更新内核页表,因此分配效率上要低一些(用空间换时间)
与用户进程相似,内核也有一个名为init_mm的mm_strcut结构来描述内核地址空间,其中页表项pdg=swapper_pg_dir包含了系统内核空间(3G-4G)的映射关系。因此vmalloc分配内核虚拟地址必须更新内核页表,而kmalloc或get_free_page由于分配的连续内存,所以不需要更新内核页表。
vmalloc分配的内核虚拟内存与kmalloc/get_free_page分配的内核虚拟内存位于不同的区间,不会重叠。因为内核虚拟空间被分区管理,各司其职。进程空间地址分布从0到3G(其实是到PAGE_OFFSET, 在0x86中它等于0xC0000000),从3G到vmalloc_start这段地址是物理内存映射区域(该区域中包含了内核镜像、物理页面表mem_map等等)比如我使用的系统内存是64M(可以用free看到),那么(3G——3G+64M)这片内存就应该映射到物理内存,而vmalloc_start位置应在3G+64M附近(说"附近"因为是在物理内存映射区与vmalloc_start期间还会存在一个8M大小的gap来防止跃界),vmalloc_end的位置接近4G(说"接近"是因为最后位置系统会保留一片128k大小的区域用于专用页面映射,还有可能会有高端内存映射区,这些都是细节,这里我们不做纠缠)。

上图是内存分布的模糊轮廓
由get_free_page或Kmalloc函数所分配的连续内存都陷于物理映射区域,所以它们返回的内核虚拟地址和实际物理地址仅仅是相差一个偏移量(PAGE_OFFSET),你可以很方便的将其转化为物理内存地址,同时内核也提供了virt_to_phys()函数将内核虚拟空间中的物理映射区地址转化为物理地址。要知道,物理内存映射区中的地址与内核页表是有序对应的,系统中的每个物理页面都可以找到它对应的内核虚拟地址(在物理内存映射区中的)。
而vmalloc分配的地址则限于vmalloc_start与vmalloc_end之间。每一块vmalloc分配的内核虚拟内存都对应一个vm_struct结构体(可别和vm_area_struct搞混,那可是进程虚拟内存区域的结构),不同的内核虚拟地址被4k大小的空闲区间隔,以防止越界——见下图)。与进程虚拟地址的特性一样,这些虚拟地址与物理内存没有简单的位移关系,必须通过内核页表才可转换为物理地址或物理页。它们有可能尚未被映射,在发生缺页时才真正分配物理页面。

单例模式*
都是从网上学得,整理下自己的理解。
单例模式有两种实现模式:
1)懒汉模式: 就是说当你第一次使用时才创建一个唯一的实例对象,从而实现延迟加载的效果。
2)饿汉模式: 就是说不管你将来用不用,程序启动时就创建一个唯一的实例对象。
所以,从实现手法上看, 懒汉模式是在第一次使用单例对象时才完成初始化工作。因为此时可能存在多线程竞态环境,如不加锁限制会导致重复构造或构造不完全问题。
饿汉模式则是利用外部变量,在进入程序入口函数之前就完成单例对象的初始化工作,此时是单线程所以不会存在多线程的竞态环境,故而无需加锁。
二、静态局部变量的懒汉模式 ,而不是new在堆上创建对象,避免自己回收资源。
这里仍然要注意的是局部变量初始化的线程安全性问题,在C++0X以后,要求编译器保证静态变量初始化的线程安全性,可以不加锁。但C++ 0X以前,仍需要加锁。
以下是典型的几种实现
class Singleton
{
public:
static Singleton* GetInstance()
{
Lock(); // not needed after C++0x
static Singleton instance;
UnLock(); // not needed after C++0x
return &instance;
}
private:
Singleton() {};
Singleton(const Singleton &);
Singleton & operator = (const Singleton &);
};
三、饿汉模式,基础版本
因为程序一开始就完成了单例对象的初始化,所以后续不再需要考虑多线程安全性问题,就可以避免懒汉模式里频繁加锁解锁带来的开销。

class Singleton
{
public:
static Singleton* GetInstance()
{
return &m_instance;
}
private:
Singleton(){};
Singleton(Singleton const&);
Singleton& operator=(Singleton const&);
static Singleton m_instance;
};
Singleton Singleton::m_instance; // 在程序入口之前就完成单例对象的初始化