2.request
首先上实例
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
与之前一样生成了python官网的内容,但这次我们构造的是一个Request类,我们可以将请求独立成一个对象,也可以配置参数
class.urllib.request.Request(url , data = None , headers = {} , origin_req_host = None , unverifiable = False , method = None)
- 第一个参数为必传参数,其他都为可选参数。
- 第二个data如果要传,必须以字节流(bytes)的类型传,如果为字典,可以先用urllib.parse模块里的urlencode()编码
- 第三个headers参数为一个字典,就是请求头,可用add_header()添加,可通过修改User-Agent来伪装成浏览器,比如要伪装成火狐浏览器,可以
Mozilla/5.0 (X11;U;Linux i686) Gecko/20071127 Firefox/2.0.0.11
- 第四个是请求方的host名称或者IP地址
- 第五个表示这个请求是无法验证的,默认为False,比如我们要抓取某文档的图片,但没有自动获取的权限,这是该参数为TRUE
- 第六个为一个字符串,用来只是请求使用的方法,比如GET,POST,PUT等
import urllib
from urllib import parse,request
url = 'http://httpbin.org/post'
headers = {
'User-agent':'Mozilla/4.0(compatible;MSIE 5.5 ;Windows NT)'
'host = httpbin.org'
}
dict = {'name':'Germey'}
data = bytes(parse.urlencode(dict),encoding='utf-8')
req = urllib.request.Request(url=url , data = data , headers = headers , method = 'POST')
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
===================== RESTART: F:\Python\exercise\ok.py =====================
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "Germey"
},
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/4.0(compatible;MSIE 5.5 ;Windows NT)host = httpbin.org"
},
"json": null,
"origin": "182.110.15.26",
"url": "http://httpbin.org/post"
}
>>>
bytes()函数的API为:
class bytes([source[, encoding[, errors]]])
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
而parse下的urlencode函数,可以把key-value这样的键值对转换成我们想要的格式,返回的是a=1&b=2这样的字符串
Request类也可以通过add_header('User-agent':'Mozilla/4.0(compatible;MSIE 5.5 ;Windows NT)
下面介绍一些更高级的用法,我们的工具Handle上场了
首先需要了解一下所有Handler的父类Basehandler类,他有很多子类:
- HTTPDefaultErrorHandler:用于处理HTTP响应错误,错误会抛出HTTPError异常
- HTTPRedirectHandler:用于处理定向
- HTTPCookieProcessor:用于处理Cookies
- ProxyHandler:用于设置代理,默认代理为空
- HTTPPasswordMgr:用于管理密码,维护了用户名和密码的表
- HTTPBasicAuthHandler:用于管理认证,链接打开时需要认证,可用他来解决认证问题
还有OpenerDirector类,之前使用的urlopen其实就是打开了opener类,前面的urlopen就相当于封装好了请求方法,现在这个相当于更深一步配置请求功能,用到了opener类
其可以使用open方法,虽然返回的类型与urlopen()的一致
- 验证
HTTPBasicAuthHandler处理器(Web客户端授权验证)
有些网站打开时会进行身份验证,提示输入用户名和密码

import urllib.request
from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener
from urllib.error import URLError
username = 'username'
password = 'password'
url = 'http://localhost:4000/'
#构建一个密码管理对象,用来保存需要处理的用户名和密码
p = urllib.request.HTTPPasswordMgrWithDefaultRealm()
#添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管都是None,后面三个参数分别是Web服务器,用户名,密码
p.add_password(None, url, username, password)
#构建一个HTTP基础用户名/密码验证的HTTPBasicAuthHandler处理器对象,参数是创建的密码管理对象
auth_handler=HTTPBasicAuthHandler(p)
#通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler
opener = build_opener(auth_handler)
#然后直接在Opener发送请求时就相当于已经验证成功了
try:
urllib.request.install_opener(opener)
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
except URLError as e:
print(e.reason)
===================== RESTART: F:\Python\exercise\ok.py =====================
[WinError 10061] 由于目标计算机积极拒绝,无法连接。
- 代理
ProxyBasicAuthHandler(代理授权验证)
使用了ProxyHandler函数处理,直接上代码
import urllib.request # 私密代理授权的账户 user = "mr_mao_hacker" # 私密代理授权的密码 passwd = "sffqry9r" # 私密代理 IP proxyserver = "61.158.163.130:16816" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求
#这里构造的Request类相当于一个自定义的请求,但自定义只定义了他的URL,与只输入URL没有区别
request = urllib.request.Request("http://www.baidu.com/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read().decode('uft-8'))
关于代理的还可以参考这篇文章:https://blog.csdn.net/qq_32252917/article/details/79074219
首先,啥是Cookies呢,Cookies就是服务器暂存放在你的电脑里的资料(.txt格式的文本文件),好让服务器用来辨认你的计算机。当你在浏览网站的时候,Web服务器会先送一小小资料放在你的计算机上,Cookies 会帮你在网站上所打的文字或是一些选择都记录下来。当下次你再访问同一个网站,Web服务器会先看看有没有它上次留下的Cookies资料,有的话,就会依据Cookie里的内容来判断使用者,送出特定的网页内容给你。
先上一个实例如何将网站的Cookies弄下来:
import http.cookiejar,urllib.request #首先必须声明一个CookieJar对象
cookie = http.cookiejar.CookieJar() handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open('http://www.baidu.com') for item in cookie: print (item.name+"="+item.value) ====================== RESTART: F:\Python\exercise\1.py ====================== BAIDUID=76B5F4D5A2EF8ADD2571BABCBAA63F79:FG=1 BIDUPSID=76B5F4D5A2EF8ADD2571BABCBAA63F79 H_PS_PSSID=1993_1454_21093_26350_26922_22158 PSTM=1534469599 BDSVRTM=0 BD_HOME=0 delPer=0
然后根据网上一个博主的博客,进行其他一些学习https://blog.csdn.net/c406495762/article/details/69817490
接着我保存cookie的信息
import http.cookiejar,urllib.request
filename = 'cookies.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.build_opener(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard = True , ignore_expires = True)
发现程序显示为
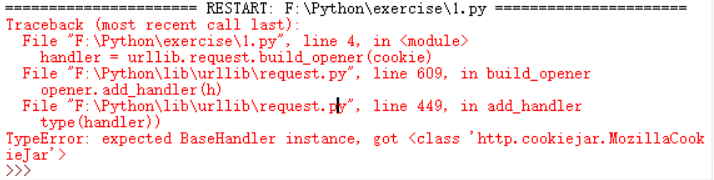
这个坑先留到这里,如果哪位大神知道我哪里错了,还请能帮忙指出