Hadoop编译安装指南(centos 7)
1 hadoop编译
1.1 为什么需要编译?
我们都知道hadoop使用JAVA语言来编写的,而官方提供的是.java文件,我们需要编译成能够被JVM可执行的.class文件。才能够再JVM上运行,才能够正常安装。
1.2我们需要准备哪些工具?
1.2.1 protobuf
1.2.1.1 protobuf简介
protobuf是由google公司贡献的开源序列化框架,类似与XML和JSON数据表示语言。而protobuf最大的特点就是基于二进制,因此效率会比XML高得多。而hadoop中的RPC实现是基于protobuf的,所以我们在编译时需要预先安装protobuf。
protobuf开源网址为:https://github.com/google/protobuf
protobuf各个版本的zip包:https://github.com/google/protobuf/releases
1.2.1.2 protobuf编译安装
根据上述提供的网址下载protobuf的预编译包。本次下载的版本是protobuf-2.5.0.tar.gz(在文件夹中提供,由于官网不支持2.5.0版本的下载,而hadoop2.7.3版本要求必须为2.5.0)。
具体安装步骤如下:
1、安装protobuf所需的依赖包
yuminstall autoconf automake libtool curl make g++ gcc-c++ unzip
2、将下载的protobuf包放到cenos7服务器中。
3、解压压缩包tarzxvf protobuf-2.5.0.tar.gz
4、进入到protobuf目录cd protobuf-2.5.0
5、从github下载的souce包需要先直行脚本autogen.sh,下载一些相关文件
./ autogen.sh
6、直行编译安装
1)./configure
2)make
3)make check
4)sudo make install
5)sudo ldconfig # refresh shared library cache
安装完成之后,可以使用protoc –version查看版本号。
1.2.2 maven
1.2.2.1 maven简介
Maven是一个项目管理和综合工具。Maven提供了开发人员构建一个完整的生命周期框架。开发团队可以自动完成项目的基础工具建设,Maven使用标准的目录结构和默认构建生命周期。
在多个开发团队环境时,Maven可以设置按标准在非常短的时间里完成配置工作。由于大部分项目的设置都很简单,并且可重复使用,Maven让开发人员的工作更轻松,同时创建报表,检查,构建和测试自动化设置。
概括地说,Maven简化和标准化项目建设过程。处理编译,分配,文档,团队协作和其他任务的无缝连接。 Maven增加可重用性并负责建立相关的任务。
1.2.2.2 maven安装
maven的安装可以直接使用yum install maven命令安装。
安装完成之后可以通过mvn–version命令去查看是否正常安装。
1.3 编译hadoop
做好上述准备工作之后(自动安装的maven的时候会安装jdk和ant,如果手动安装,请注意安装这两个工具),我们就可以去编译Hadoop了。hadoop编译需要的各个工具的版本,在BUILDING.txt文件中会有详细说明。(2.7.3版本中,ProtocolBuffer要求必须为2.5.0)
首先我们需要从apache官网下载hadoop的源码包。在此我下载的版本是hadoop-2.7.3-src.tar.gz。
hadoop源码下载连接:http://hadoop.apache.org/releases.html#Download
具体编译过程如下:
1、将源码包上传到服务器上。
2、解压文件包tar zxvf hadoop-2.7.3-src.tar.gz
3、进入源码包cd hadoop-2.7.3-src
4、运行编译命令mvn package -Pdist -DskipTests –Dtar
经过漫长的等待之后,编译成功后会显示以下信息:
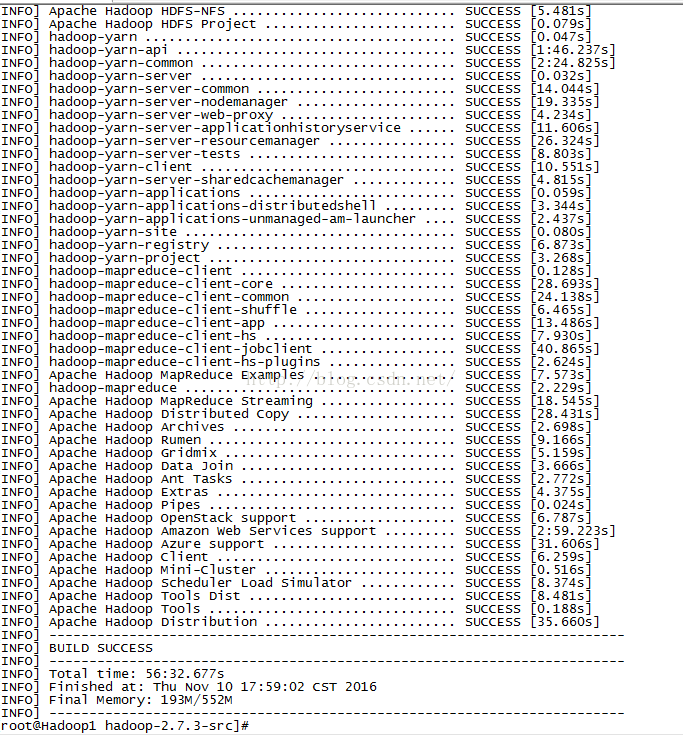
从提示信息我们可以看到编译好的hadoop压缩包存放的目录,直接取出使用。大功告成!
2 hadoop安装(分布式)
2.1 环境说明
1、系统环境:centos 7
2、java版本:jdk 1.8
3、hadoop版本:2.7.3
2.2 节点配置
Master: 192.168.1.10 (hadoopmaster)
Hadoopslave: 192.168.1.11(hadoopslave1)
Hadoopslave: 192.168.1.12(hadoopslave2)
2.3 安装步骤
2.3.1 安装jdk
1、下载安装包,本次下载的是:jdk-8u111-linux-x64.tar.gz下载地址为:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2、创建文件夹 mkdir /usr/local/java
3、将安装包上传至目录/usr/local/java
4、解压安装包tar zxvf jdk-8u111-linux-x64.tar.gz
5、配置环境变量在/etc/profile文件的末尾添加
JAVA_HOME=/usr/local/java/jdk1.8.0_111
JRE_HOME=/usr/local/java/jdk1.8.0_111/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
PATH=$PATH:$JAVA_HOME/bin
6、让环境变量及时生效source /etc/profile
7、查看java版本信息 java –version
2.3.2 添加用户
新建一个hadoop用户,用于管理和维护hadoop相关的操作。
useradd -m hadoop -s /bin/bash
修改用户登陆密码
passwd hadoop
连续两次输入密码
添加用户完成!
2.3.3 ssh免密登陆
1、切换到hadoop用户
2、在192.168.1.10机器(master)中执行命令
①cd ~/.ssh (进入用户目录下的隐藏文件.ssh,若没有该目录,请先执行一次ssh localhost)
②ssh-keygen-t rsa (用rsa生成密钥)
③cpid_rsa.pub authorized_keys(把公钥复制一份,并改名为authorized_keys,这步执行完,应该ssh localhost可以无密码登录本机了,可能第一次要密码)
④scp authorized_keys [email protected]:/home/hadoop/.ssh(把重命名后的公钥通过ssh提供的远程复制文件复制到从机slave1上面)
⑤chmod 600authorized_keys (更改公钥的权限,也需要在从机slave1中执行同样代码)
⑥ssh 192.168.1.11(可以远程无密码登录slave1这台机子了,注意是ssh不是sudo ssh。)
3、如果有其他的子节点,则直行相同的操作
2.3.4 安装hadoop
1、上传编译好的hadoop包,并解压tar zxvf hadoop-2.7.3.tar.gz
2、修改解压后的文件夹名称mv hadoop-2.7.3 hadoop
3、修改文件夹权限chown -R hadoop:hadoop hadoop

4、修改hadoop的JAVA_HOME :vi etc/hadoop/hadoop-env.sh将JAVA_HOME修改为绝对路径
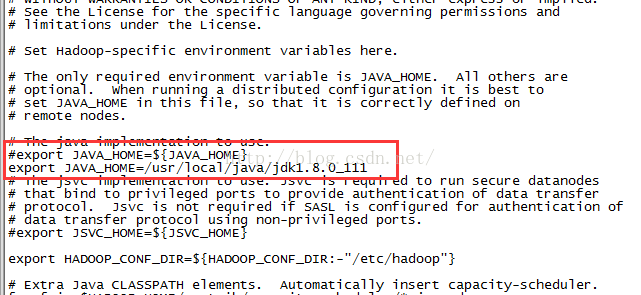
5、查看hadoop版本./bin/hadoop version
6、增加hadoop环境变量 vi ~/.bashrc
# Hadoop EnvironmentVariables
exportHADOOP_HOME=/hadoop/hadoop
exportHADOOP_INSTALL=$HADOOP_HOME
exportHADOOP_MAPRED_HOME=$HADOOP_HOME
exportHADOOP_COMMON_HOME=$HADOOP_HOME
exportHADOOP_HDFS_HOME=$HADOOP_HOME
exportYARN_HOME=$HADOOP_HOME
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportPATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
7、使环境变量即时生效source ~/.bashrc
8、测试环境变量是否生效 hadoop verison
2.3.5 配置hadoop集群
搭建集群需要修改hadoop/etc/hadoop下面的共五个配置文件,更多高级选项设置,可以参见官网说明。这里仅设置了一些必要的设置。
1、slave文件
该文件是配置叶子节点。默认文件只有一行localhsot,这里一行代表一个叶子节点。根据我们的节点配置安排,我们再次配置如下:
2、core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.10:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/hadoop/hadoop/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
3、hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.10:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4、mapred-site.xml 文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.10:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.10:19888</value>
</property>
</configuration>
5、 yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.10</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6、将配置好的hadoop拷贝到叶子节点的服务器中
①将文件夹压缩tar-zcf /hadoop/hadoop.master.tar.gz /hadoop/hadoop
②将压缩文件拷贝到叶子节点服务器
scphadoop.master.tar.gz [email protected]:/hadoop
scphadoop.master.tar.gz [email protected]:/hadoop
③在叶子节点服务器中解压文件夹 tar zxvf hadoop.master.tar.gz
④修改文件夹权限chown-R hadoop:hadoop hadoop
⑤设置hadoop环境变量(参考2.3.4 第六点)
7、增加主机名静态查询表 vi /etc/hosts所有服务器都需要
192.168.1.10hadoop.master
192.168.1.11 hadoop.slave1
192.168.1.12 hadoop.slave2
8、初始化hdfs:hdfsnamenode –format
2.4 启动hadoop
经过上述准备我们的hadoop集群就搭建完成了。接下来我们可以来到mater主服务器来启动hadoop。
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.shstart historyserver
然后我们可以通过jps命令查看各个服务器的启动进程。
主服务器(master)下可以看到如下进程:
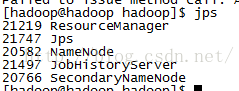
叶子节点的服务器可以看到如下进程:

我们也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:
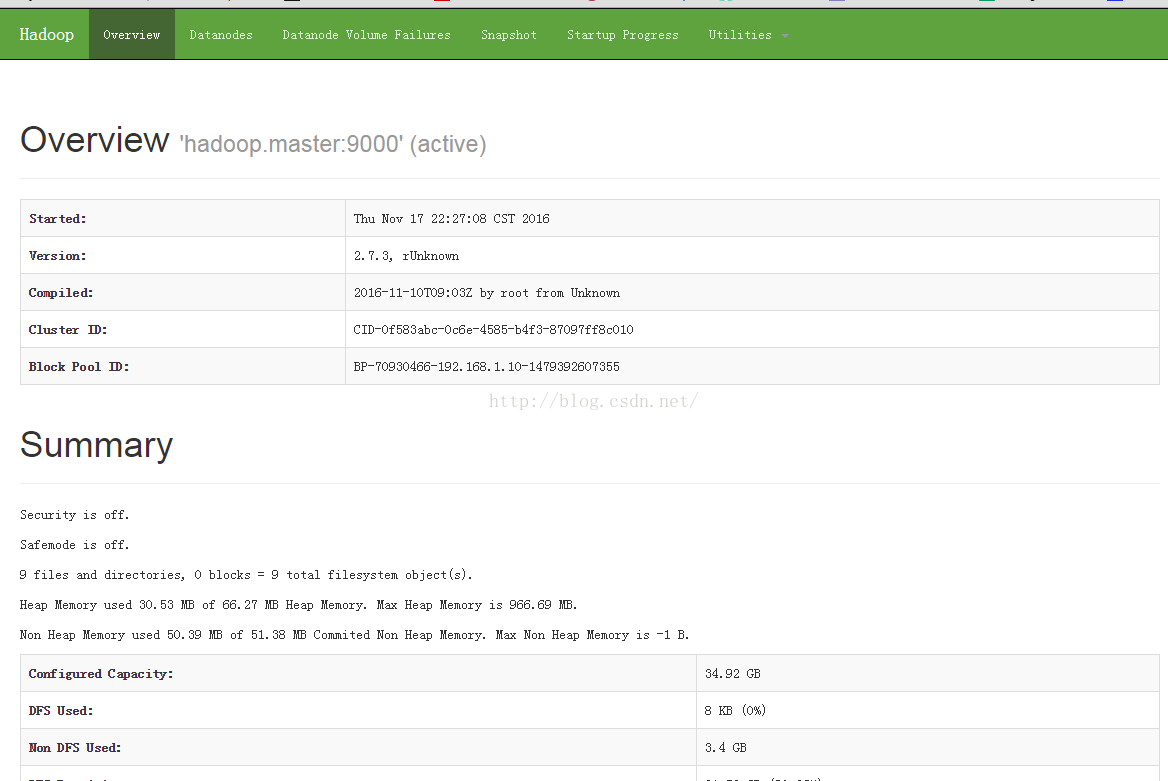
2.5 关闭hadoop集群
关闭集群也是在主服务器(master)上执行命令:
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.shstop historyserver