学习如何用神经网络来解决分类问题。
开始都会说什么是机器学习?机器学习的应用是什么?用机器在海量数据中学习得到可以解决一类问题的办法,这就是我的理解。图像处理、文本处理、无人驾驶、等,深度学习最热门的应用就是无人驾驶。而深度学习的核心是神经网络。神经网络就是模拟人的大脑工作。所以神经网络很重要、
神经网络是机器学习中的一个模型,可以用于两类问题的解答:
- 分类:把数据划分成不同的类别
- 回归:建立数据间的连续关系
1、分类问题
录取与不录取的问题:
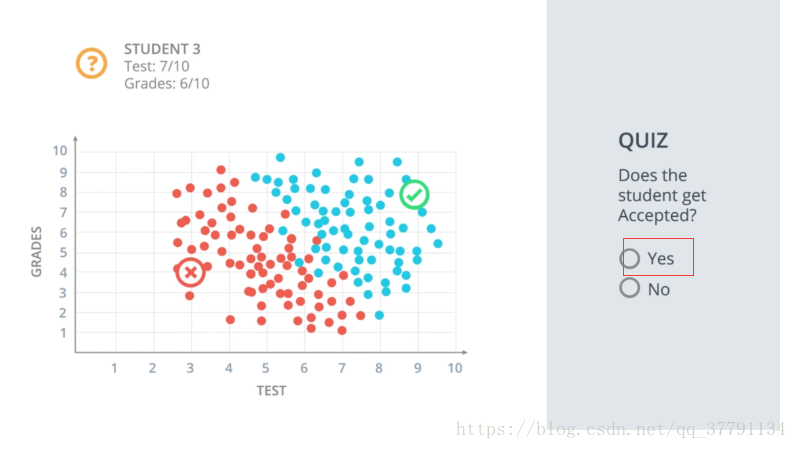

如何让电脑找到这条线呢? 所以接下来我们要学习找到这条线的算法。
2、线性界限月更高维度的界限
对于二维数据是线性界限。
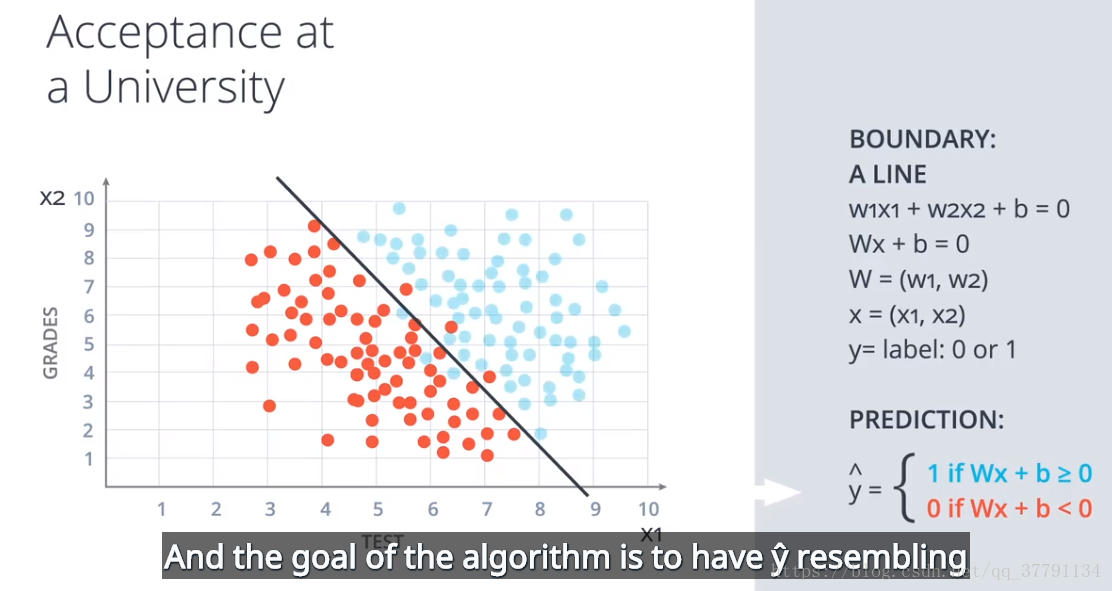
对于更高维度的界限。需要平面,甚至曲面。
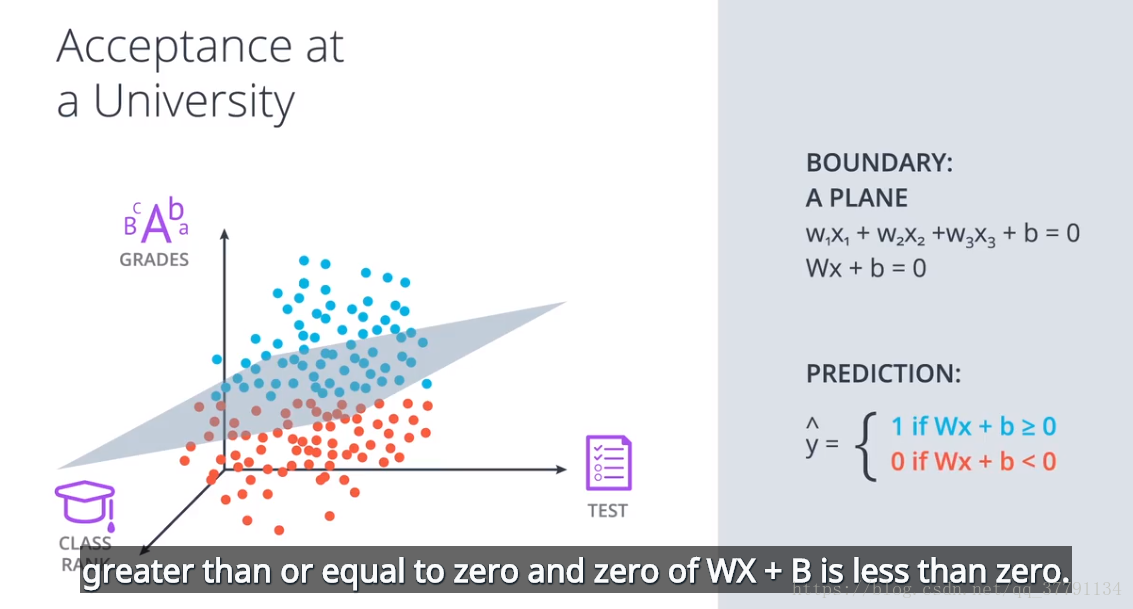

3、Logistics(对数概率)感知器
感知器由两个节点构成,第一个是线性求和,第二个是对线性求和的结果进行阶跃,从而得到0、1
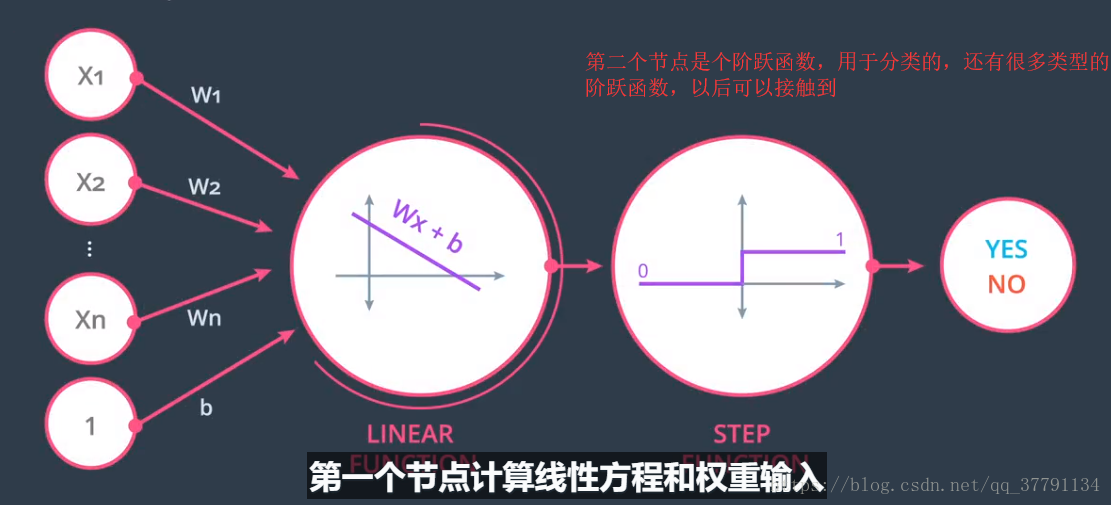
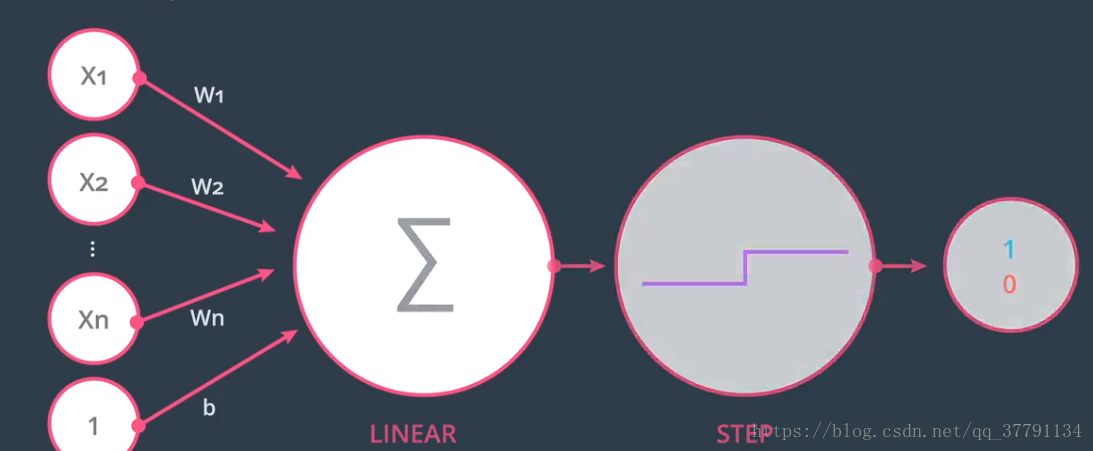
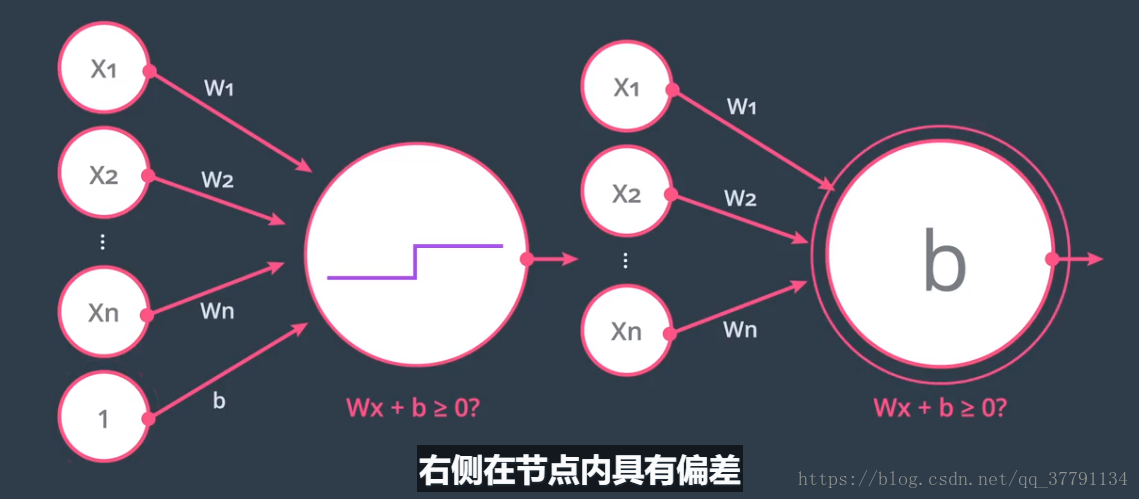
两种格式,一般是左边。
4、为何是神经网络
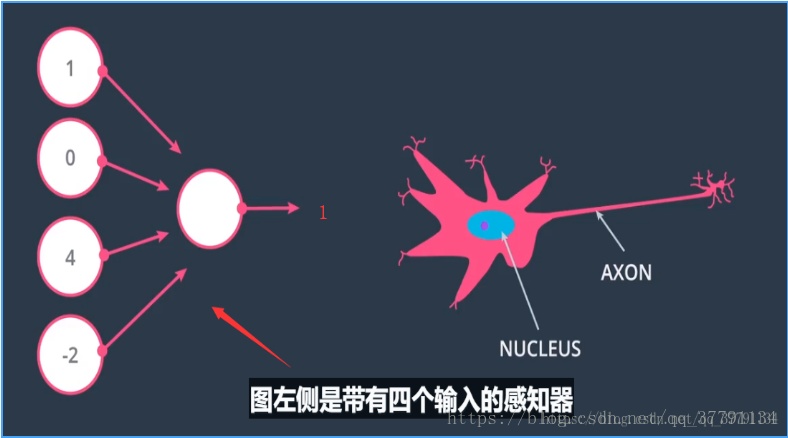
感知器的结果和人体大脑神经元很相似,这个感知器和人体大脑的神经元的链接方式类似。我们会连接这些感知器来创建神经网络,与大脑神经原连接方式很相似,都是一个神经元的输出作为一个神经元的输入。
5、作为Logistic(对数概率)运算符的感知器
我们将见到感知器的很多强大应用之一。作为逻辑运算符!你将有机会为最常见的逻辑运算符创建感知器:AND、OR 和 NOT 运算符。然后,我们将看看如何处理比较难处理的 XOR 运算符。
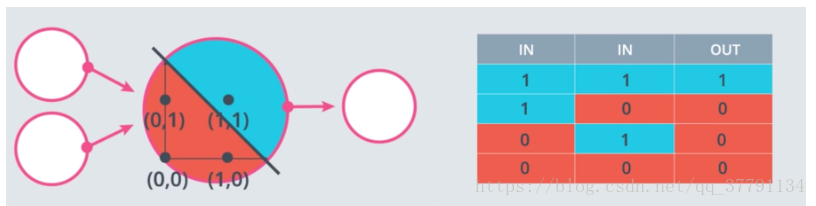
AND 感知器的权重和偏差是什么?
将权重(weight1、weight2)和偏差 bias 设为正确的值,以便如上所示地计算 AND 运算。
import pandas as pd
# TODO: Set weight1, weight2, and bias
weight1 = 2.0
weight2 = 2.0
bias = -3.0
# DON'T CHANGE ANYTHING BELOW
# Inputs and outputs
test_inputs = [(0, 0), (0, 1), (1, 0), (1, 1)]
correct_outputs = [False, False, False, True]
outputs = []
# Generate and check output
for test_input, correct_output in zip(test_inputs, correct_outputs):
linear_combination = weight1 * test_input[0] + weight2 * test_input[1] + bias
output = int(linear_combination >= 0)
is_correct_string = 'Yes' if output == correct_output else 'No'
outputs.append([test_input[0], test_input[1], linear_combination, output, is_correct_string])
# Print output
num_wrong = len([output[4] for output in outputs if output[4] == 'No'])
output_frame = pd.DataFrame(outputs, columns=['Input 1', ' Input 2', ' Linear Combination', ' Activation Output', ' Is Correct'])
if not num_wrong:
print('Nice! You got it all correct.\n')
else:
print('You got {} wrong. Keep trying!\n'.format(num_wrong))
print(output_frame.to_string(index=False))
OR 感知器
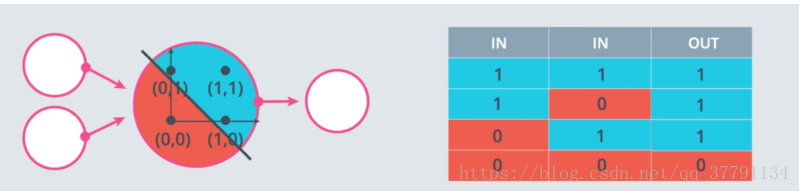
OR 感知器和 AND 感知器很相似。在下图中,OR 感知器和 AND 感知器的直线一样,只是直线往下移动了。你可以如何处理权重和/或偏差以实现这一效果?请使用下面的 AND 感知器来创建一个 OR 感知器。
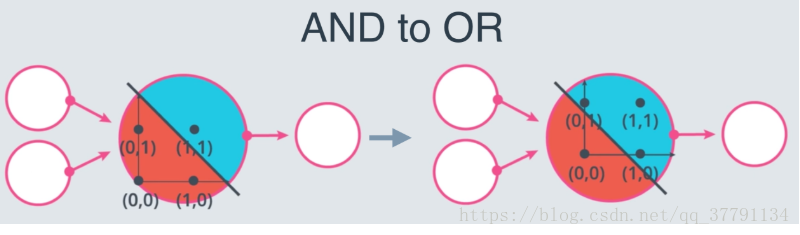

NOT 感知器
和我们刚刚研究的其他感知器不一样,NOT 运算仅关心一个输入。如果输入是 1,则运算返回 0,如果输入是 0,则返回 1。感知器的其他输入被忽略了。
在此测验中,你将设置权重(weight1、weight2)和偏差 bias,以便对第二个输入进行 NOT 运算,并忽略第一个输入。
import pandas as pd
# TODO: Set weight1, weight2, and bias
weight1 = 0.0
weight2 = -4.0
bias = 3.0
# DON'T CHANGE ANYTHING BELOW
# Inputs and outputs
test_inputs = [(0, 0), (0, 1), (1, 0), (1, 1)]
correct_outputs = [True, False, True, False]
outputs = []
# Generate and check output
for test_input, correct_output in zip(test_inputs, correct_outputs):
linear_combination = weight1 * test_input[0] + weight2 * test_input[1] + bias
output = int(linear_combination >= 0)
is_correct_string = 'Yes' if output == correct_output else 'No'
outputs.append([test_input[0], test_input[1], linear_combination, output, is_correct_string])
# Print output
num_wrong = len([output[4] for output in outputs if output[4] == 'No'])
output_frame = pd.DataFrame(outputs, columns=['Input 1', ' Input 2', ' Linear Combination', ' Activation Output', ' Is Correct'])
if not num_wrong:
print('Nice! You got it all correct.\n')
else:
print('You got {} wrong. Keep trying!\n'.format(num_wrong))
print(output_frame.to_string(index=False))XOR 感知器
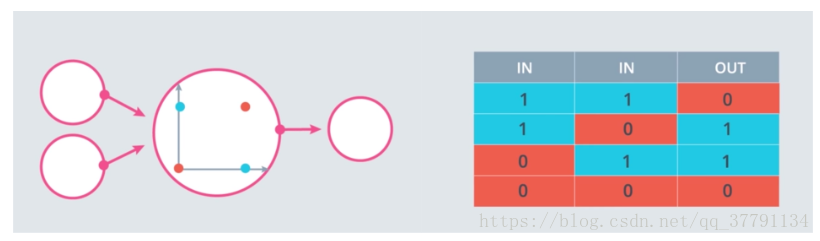
测验:构建一个 XOR 多层感知器
现在我们使用 AND、NOT 和 OR 感知器构建一个多层感知器,以便创建 XOR 逻辑!
下面的神经网络包含三个感知器:A、B 和 C。最后一个 (AND) 已经提供给你了。神经网络的输入来自第一个节点。输出来自最后一个节点。
上面的多层感知器计算出 XOR。每个感知器都是 AND、OR 和 NOT 的逻辑运算。但是,感知器 A、B、C 和 D 并不表明它们的运算。在下面的测验中,请为四个感知器设置正确的运算,以便计算 XOR。
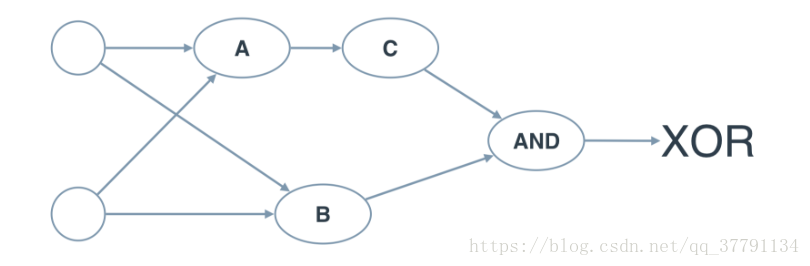
在 XOR 神经网络中为感知器设置运算
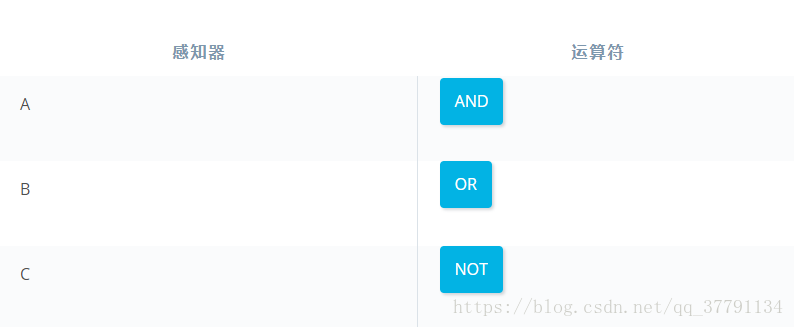
6、感知器技巧 - 计算机如何“学习”分类?
在上一部分,你使用你自己的逻辑和数学知识为某些最常见的逻辑运算符创建了感知器。 但是在现实生活中,除了这些非常简单的形式,我们人类是无法靠自己构建这些感知器函数,找到用于分类的曲线的。
计算机如何根据我们人类给出的结果,来自己进行构建感知器函数。对于这一点,有一个非常棒的技巧会帮到我们。就是希望离我们越来越近,
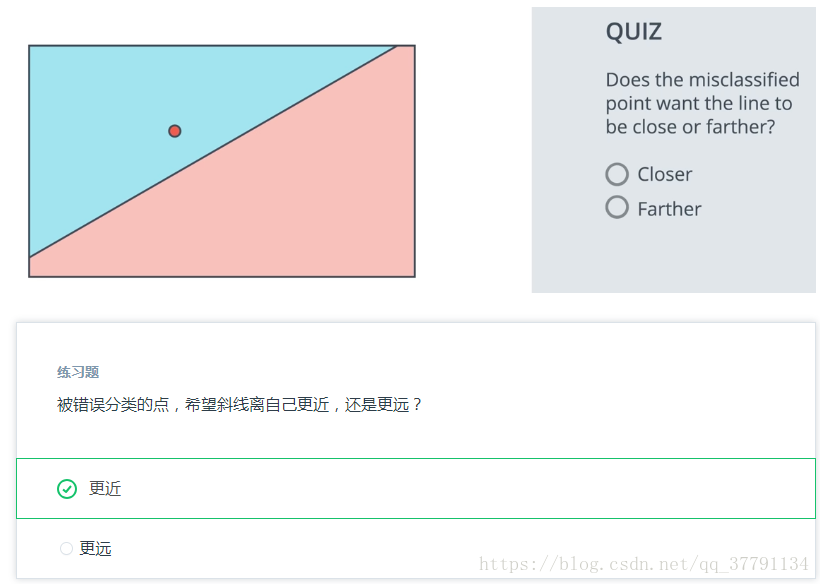
介绍一个让直线离点近些的诀窍。
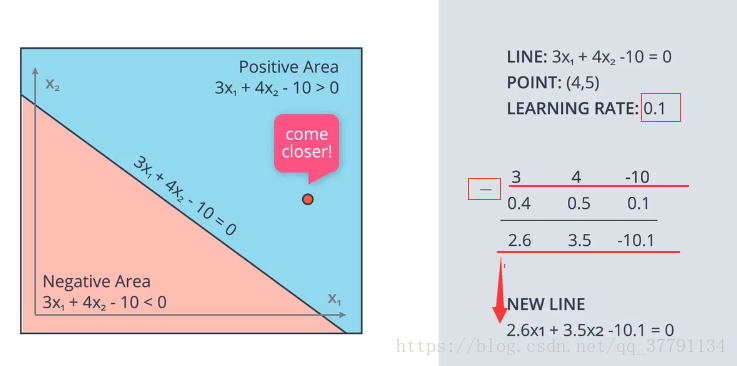
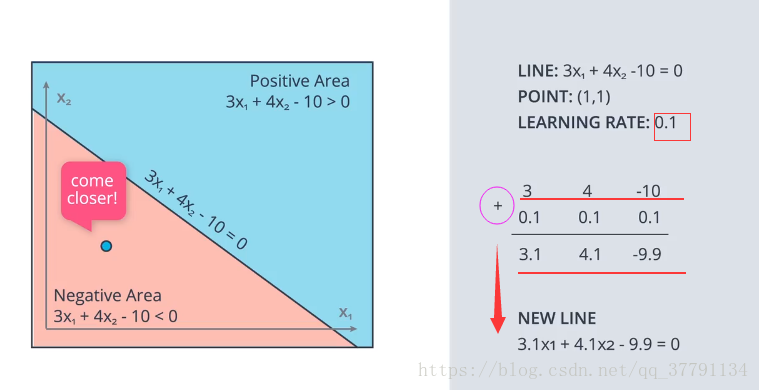
上面就是去改变这条直线可是怎么改变呢?就是让原本是1的点归化为0的点,使得 w、b 都减去一个学习率,然后得到新直线,看是否会越来近。同理原本是0的点归为1的点,使得w,b都加上一个学习率。
整个数据集中的每一个点都会把分类的结果提供给感知器(分类函数),并调整感知器。——这就是计算机在神经网络算法中,找寻最优感知器的原理。
7、感知器算法
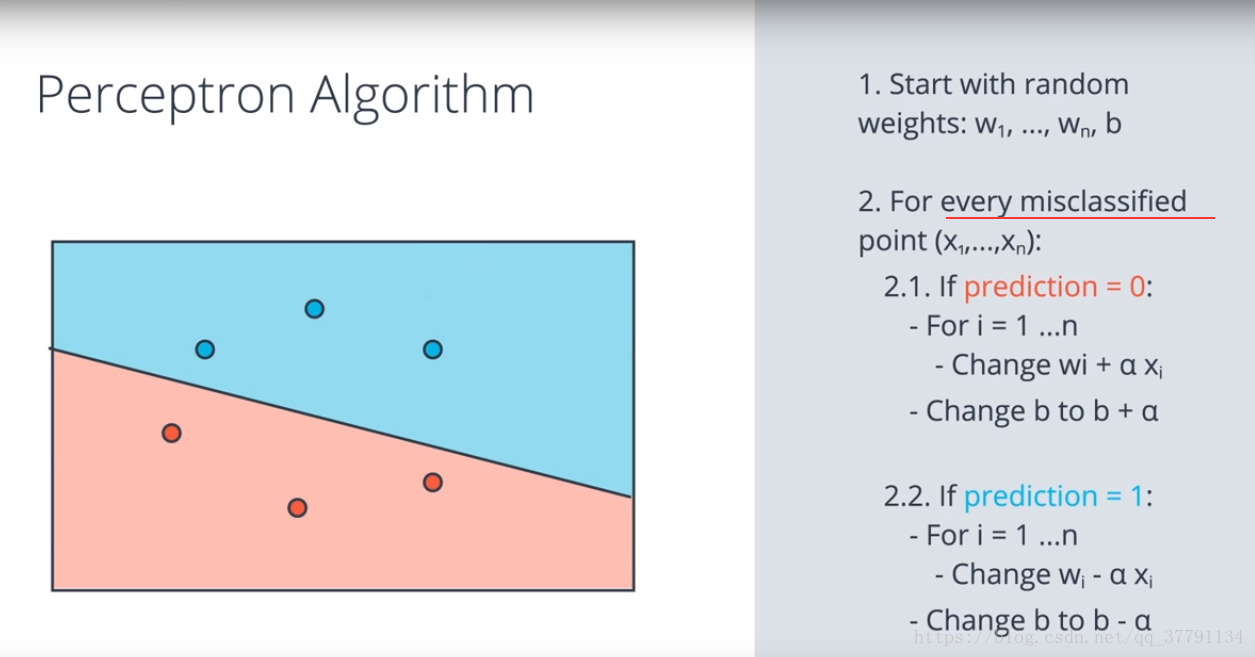
掌握了感知器技巧后,我们就可以编写完整的感知器运算的算法了!
该编写代码了!在此练习中,你将实现感知器算法以分类下面的数据(位于文件 data.csv 中)。
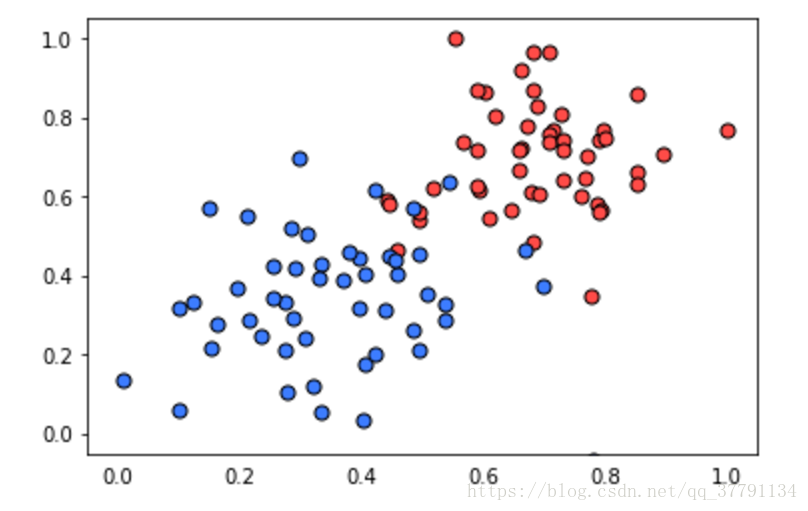

运行结果将绘出感知器算法给出的解决方案。它实际上会画出一组虚线,显示算法如何接近最佳解决方案(用黑色实线表示)。
import numpy as np
# Setting the random seed, feel free to change it and see different solutions.
np.random.seed(42)
def stepFunction(t):
if t >= 0:
return 1
return 0
def prediction(X, W, b):
return stepFunction((np.matmul(X,W)+b)[0])
# TODO: Fill in the code below to implement the perceptron trick.
# The function should receive as inputs the data X, the labels y,
# the weights W (as an array), and the bias b,
# update the weights and bias W, b, according to the perceptron algorithm,
# and return W and b.
def perceptronStep(X, y, W, b, learn_rate = 0.05):
# Fill in code
for i in range(len(X)):
y_hat = prediction(X[i],W,b)
if y[i]-y_hat == 1:
W[0] += X[i][0]*learn_rate
W[1] += X[i][1]*learn_rate
b += learn_rate
elif y[i]-y_hat == -1:
W[0] -= X[i][0]*learn_rate
W[1] -= X[i][1]*learn_rate
b -= learn_rate
return W, b
# This function runs the perceptron algorithm repeatedly on the dataset,
# and returns a few of the boundary lines obtained in the iterations,
# for plotting purposes.
# Feel free to play with the learning rate and the num_epochs,
# and see your results plotted below.
def trainPerceptronAlgorithm(X, y, learn_rate = 0.01, num_epochs = 25):
x_min, x_max = min(X.T[0]), max(X.T[0])
y_min, y_max = min(X.T[1]), max(X.T[1])
W = np.array(np.random.rand(2,1))
b = np.random.rand(1)[0] + x_max
# These are the solution lines that get plotted below.
boundary_lines = []
for i in range(num_epochs):
# In each epoch, we apply the perceptron step.
W, b = perceptronStep(X, y, W, b, learn_rate)
boundary_lines.append((-W[0]/W[1], -b/W[1]))
return boundary_linesdata.csv数据
0.78051,-0.063669,1
0.28774,0.29139,1
0.40714,0.17878,1
0.2923,0.4217,1
0.50922,0.35256,1
0.27785,0.10802,1
0.27527,0.33223,1
0.43999,0.31245,1
0.33557,0.42984,1
0.23448,0.24986,1
0.0084492,0.13658,1
0.12419,0.33595,1
0.25644,0.42624,1
0.4591,0.40426,1
0.44547,0.45117,1
0.42218,0.20118,1
0.49563,0.21445,1
0.30848,0.24306,1
0.39707,0.44438,1
0.32945,0.39217,1
0.40739,0.40271,1
0.3106,0.50702,1
0.49638,0.45384,1
0.10073,0.32053,1
0.69907,0.37307,1
0.29767,0.69648,1
0.15099,0.57341,1
0.16427,0.27759,1
0.33259,0.055964,1
0.53741,0.28637,1
0.19503,0.36879,1
0.40278,0.035148,1
0.21296,0.55169,1
0.48447,0.56991,1
0.25476,0.34596,1
0.21726,0.28641,1
0.67078,0.46538,1
0.3815,0.4622,1
0.53838,0.32774,1
0.4849,0.26071,1
0.37095,0.38809,1
0.54527,0.63911,1
0.32149,0.12007,1
0.42216,0.61666,1
0.10194,0.060408,1
0.15254,0.2168,1
0.45558,0.43769,1
0.28488,0.52142,1
0.27633,0.21264,1
0.39748,0.31902,1
0.5533,1,0
0.44274,0.59205,0
0.85176,0.6612,0
0.60436,0.86605,0
0.68243,0.48301,0
1,0.76815,0
0.72989,0.8107,0
0.67377,0.77975,0
0.78761,0.58177,0
0.71442,0.7668,0
0.49379,0.54226,0
0.78974,0.74233,0
0.67905,0.60921,0
0.6642,0.72519,0
0.79396,0.56789,0
0.70758,0.76022,0
0.59421,0.61857,0
0.49364,0.56224,0
0.77707,0.35025,0
0.79785,0.76921,0
0.70876,0.96764,0
0.69176,0.60865,0
0.66408,0.92075,0
0.65973,0.66666,0
0.64574,0.56845,0
0.89639,0.7085,0
0.85476,0.63167,0
0.62091,0.80424,0
0.79057,0.56108,0
0.58935,0.71582,0
0.56846,0.7406,0
0.65912,0.71548,0
0.70938,0.74041,0
0.59154,0.62927,0
0.45829,0.4641,0
0.79982,0.74847,0
0.60974,0.54757,0
0.68127,0.86985,0
0.76694,0.64736,0
0.69048,0.83058,0
0.68122,0.96541,0
0.73229,0.64245,0
0.76145,0.60138,0
0.58985,0.86955,0
0.73145,0.74516,0
0.77029,0.7014,0
0.73156,0.71782,0
0.44556,0.57991,0
0.85275,0.85987,0
0.51912,0.62359,0这份代码我有几个不明白的,
- 怎么又两个学习率?
- 为什么不用写函数就能运行函数,难道定义了函数就可以用吗?这是就是python语句?我不信
- 大致意思知道,可是每个语句就不知道了。尴尬
8、非线性界限
就是这样,如果有个学生是给的条件是9,1,就是平时成绩是1,考试成绩为9,但是也被录取了,显然就不合适了,所以要把线性变成曲线,圆,或者别的函数关系,只要更加好就行,我们需要开发更为复杂的算法来解决这个问题。我们需要重新定义感知器算法,使其能泛化到除直线以外的其他类型曲线。
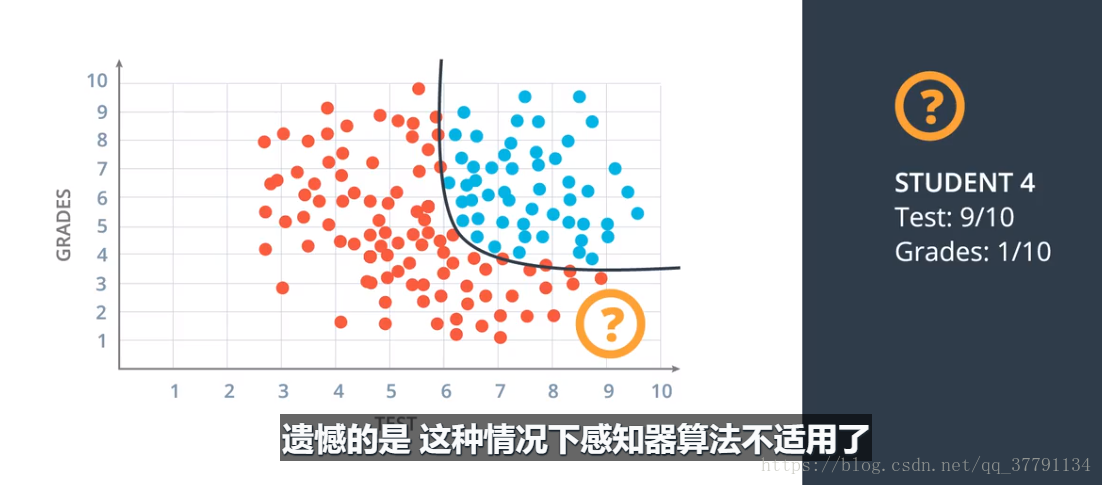
9、Logistic(对数概率)误差函数-初探
刚刚的感知器算法实现告诉我们,获取正确分类的方式,就是通过每一个错误分类的点,评估错误点位置与我们期望位置之间的差异,来慢慢的修正我们分类函数。
因为误差暗示了如何进行正确的分类,因此误差的定义就变得尤为重要,这也被称为误差函数。
10、Logistic(对数概率)误差函数与梯度下降-初探
误差函数提供给我们的预测值与实际值之间的差异,但是这个差异如何指导我们权重的更新呢?我们的目标是找到最小的误差函数值来找到与实际值误差最小的预测值。
在简单的线性方程中,我们可以通过判断“预测值与实测值相比是大了还是小了”来决定权重是增加还是减少。但是在更为复杂的非线性环境中呢?复杂的数学问题,我们就直接来看看学者们的解决策略。
假设一维问题是一条直线,那么二维问题就是一个平面,而三维问题就是一个曲面。曲面可以理解为有山峰也有低谷的地面,误差最小的地方就是低谷处,我们希望计算机找到的就是这个低谷的值。为了找到这个低谷,学者们发明了梯度下降。
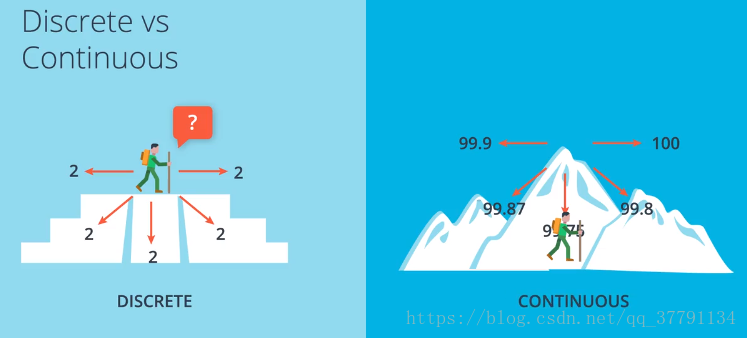
如果仅仅是距离的话,那么正巧都是2 那么如何选择,那么就无法选择了,所以科学家们想到了梯度,变化最快的那个方向,因为梯度所以不能时离散函数,必须是连续的哦。
我们的目需要找到用什么误差函数?
当点分类错误时,惩罚值等于点离直线的距离。将所有点的误差相加,得到总误差,两个错误的点使得误差很大,需要移动直线,降低误差,现在可以实现误差函数连续变化了,我们队直线参数进行小改动,使得误差函数产生一些小的变化,移动直线时,虽然有些误差变大了,但是总得误差减少了,而且还都分开了,能够构建具有这一属性的误差函数后,借可以使用梯度下降来解决我们的问题了。
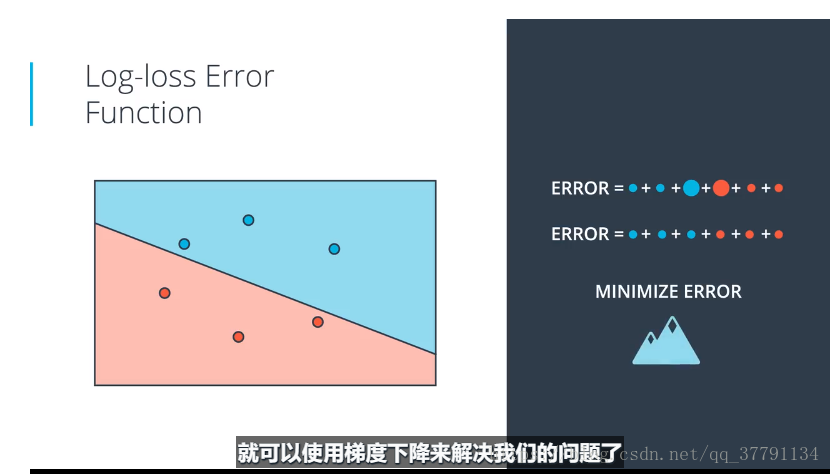

现在的问题是我们如何定义该误差函数??看下一博文介绍吧、
作业:
- 课堂上我们接触了神经网络的二分类问题,其实神经网络同样可以处理多分类问题,能思考一下他是如何处理多分类问题的嘛?
- 课堂上我们接触的都是分类问题,但是神经网络也可以处理回归问题,请思考或查询处理回归问题的例子
- 我们学习的是深度学习,但我们同样知道还有机器学习,机器学习与深度学习间有着怎样的关系呢?
- 我们在第一课中接触的均是神经网络,好像并不是深度学习,那么深度学习与神经网络有着怎样的关系呢?
- 感知器作为最基本的神经网络模型,有着悠久的历史,请查询并给出感知器模型的发明者与年份
- 机器学习除了分类和回归的划分,也可以分为监督学习和无监督学习,我们在课上接触的分类问题属于哪一类呢?
- 机器学习除了分类和回归的划分,也可以分为监督学习和无监督学习,我们在课上接触的分类问题属于监督学习,那么神经网络是否可以处理无监督学习问题呢?
- 一个最基本的感知器是由几部分组成的?他们都是什么?
- 感知器模型是一种典型的线性分类器,线性分类器是什么呢?其他典型的线性分类器有什么呢?
- 感知器模型是一种典型的线性分类器,与之相对应,自然会有非线性分类器,什么是非线性分类器呢?典型的非线性分类器有那些呢?
- 我们在课程中使用感知器模型实现了AND,OR,NOT和XOR的操作,但是其中一个很明显与其它三类不一样,请挑出它,并说明哪里不一样
- 在构建XOR感知器模型时我们使用了多层感知器,请思考我们能用最基本的单层感知器实现它吗?如果能,请给出模型,如果不能,思考为什么
- 在编写感知器算法时,有一个参数--epoch,这一参数在算法中起到了什么样的作用呢?
- 在编写感知器算法时,有一个参数--学习率,这一参数在算法中起到了什么样的作用呢?
- 学习率越大越好还是越小越好呢?这是一个很困难的问题,借助最后一课的“误差之巅”,思考一下什么时候学习率的大小对我们达到误差最小的帮助