OpenTSDB旨在在查询执行的过程中有效地组合多个不同的时间序列。原因在于:当用户查看他们的数据,他们通常会从高层的角度开始提问,例如“数据中心的总吞吐量是多少”或“当前地区用电量是多少”。在查看到这些高层次的值之后,可能会出现一个或多个值,以便用户深入查看更细化的数据集,例如“我的LAX数据中心每台主机的吞吐量是多少”。我们希望能够轻松地回答这些高层次的问题,也仍然允许深入了解更多的细节。
但是,如何将多个单独的时间序列合并成一系列的数据?聚合函数提供了将不同时间序列合并成一个的数学方法。过滤器用于按标签对结果进行分组,然后将聚合应用与每个分组。聚合类似于SQL的Group By子句,其中用户选择预定义的聚合函数将多个记录合并为单个结果。但是,在TSD中,按照每个时间戳分组聚合一系列记录为一组。
每个聚合器都有两个组件:
- 函数:应用的数学计算方法,如将所有的值累加在一起,计算出平均值或者筛选出最高(大)值。
- 插值:处理缺失值的一种方法。例如将时间序列A在T1有值,但时间序列B没有值。
本章将重点介绍在group by上下文中如何使用聚合,例如:即合并多个时间序列为一个时。另外,可以使用聚合器对时间序列进行降采样(即返回一组分辨率较低的结果)。有关更多信息,请参阅降采样。聚合
将每个时间序列集合聚合或者分组到一个中时,每个时间序列中的时间戳都对齐。然后对于每个时间戳,所有时间序列中的值将聚合为一个新的数值。也就是说,聚合将会在每个时间戳的时间序列上工作。将原始数据视作矩阵或者表,如以下示例所示,该图说明了sum聚合器在两个时间序列上的工作原理,A与B合并生成新的Output时间序列。
| 时间序列 | T0 | T0+10s | T0+20s | T0+30s | T0+40s | T0+50s |
|---|---|---|---|---|---|---|
| A | 5 | 5 | 10 | 15 | 20 | 5 |
| B | 10 | 5 | 20 | 15 | 10 | 0 |
| Output | 15 | 15 | 10 | 30 | 30 | 5 |
对于时间戳T0的数据点A和B进行求和,即5+10=15,在SQL中:
select sum(value) from ts_table group by timestamp
插值
在上面的例子中,时间序列A和B每个时间戳都有数据点,他们排列整齐。然而,当两个序列不会排队时会发生什么?同步所有数据源并同时进行写入可能很困难,有时甚至是不希望的。例如,如果我们有10,000个服务器每5分钟发送100个系统指标标准,那么将在一秒钟内突发10M的数据点。我们需要一个非常强大的网络和群集来适应这种流量。更不用说系统会闲置4分59秒。相反,随着时间的推移张开写入更有意义,因此我们平均每秒写入3,333次写入,以减少对硬件和网络的要求。
如何汇总聚合或找到一个不存在的数值的平均值?第一步就是返回有效的数据点并完成它。然而,如果像上面那样处理了数千个简单未对其的数据点的数据源呢?例如:下图展示了未对齐写入的时间序列,引起的锯齿状线条令人困惑: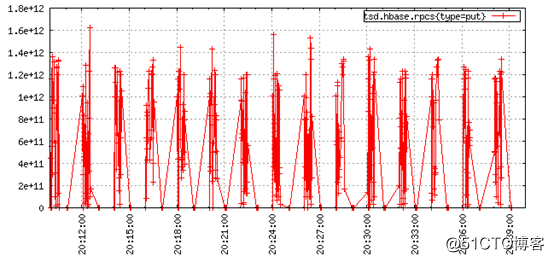
- 缺失数据:
通过“缺失”,只是表示时间序列在给定的时间戳出没有数据点。通常,数据在请求的时间戳之前或者之后简单地进行时间移位,但如果源或TSD遇到错误并且数据未被记录,它实际上可能会丢失。一些时间序列数据库可能允许在时间戳中用NaN存储一个表示不可记录的值,但OpenTSDB不允许这样做。
或者,可以简单的忽略任意缺少数据的给定时间戳的所有时间序列的数据点。但是,如果有两个时间序列,并且它们只是简单的未对齐,即使在存储中有正常的数据,查询也会返回一个空的数据集,所以这不一定非常有用。
另外一个选项是定义一个标量值(如0或者Long型的最大值),以便在数据点丢失时使用。OpenTSDB2.0和更高版本提供了一些聚合函数,用于替代丢失数据点的标量值,实际上,上图是使用zimsum聚合器生成的,该聚合使用0替换未对齐的值。当处理不同值的时间序列时,这种替代可能非常有用,例如在给定时间内的总销售数量,但在处理平均值或验证可视化图表看起来不错(平缓)时不起作用。
OpenTSDB提供的一个解决方案是使用定义良好的插值数值分析方法来猜测该时间点的值。插值使用现有的时间序列数据点来计算所需时间戳的最佳猜测值。使用OpenTSDB的线性插值,可以平滑未对齐的图,得到:
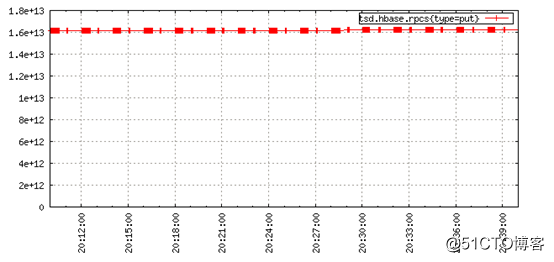
对于一个数值例子,看看这两个时间序列,其中源没20秒发出一个值,数据简单的偏移10秒:
| 时间序列 | T0 | T0+10s | T0+20s | T0+30s | T0+40s | T0+50s | T0+60s |
|---|---|---|---|---|---|---|---|
| A | na | 5 | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | 10 | na | 20 |
当OpenTSDB计算聚合时,它会从任何序列的第一个数据点开始,在这种情况下,它将是B序列的t0数据点。我们需要时间序列A在t0的值,但此处没有任何数据。我们知道时间序列A在t0+10秒有数据值。但由于在此之前我们没有任何值,所以我们不能猜测它会是什么。因此,我们只能返回时间序列B的值。
接下来我们在时间戳t0+10秒,请求时间序列B在t0+10秒的值,但是没有。但是时间序列B在t0+20秒有一个值,同时在t0也有一个值,因此我们现在可以计算猜测t0+10秒的值。线性插值的公式是y=y0+(y1-y0)((x-x0)/(x1-x0)),对序列B来说,y0=10, y1=20, x=t0+10(或10), x0=t0(或0), x1=t0+20(或20),因此:y=10+(20-10)((10-0)/(20-0))=15。因此序列B在t0+10秒给我们一个估计值15。
对于作为查询的一部分返回的每个序列找到数据点的每个时间戳都会继续进行迭代。使用sum聚合器生成的结果序列将如下所示:
| 时间序列 | T0 | T0+10s | T0+20s | T0+30s | T0+40s | T0+50s | T0+60s |
|---|---|---|---|---|---|---|---|
| A | na | 5 | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | 10 | na | 20 |
| 插值A | 10 | 10 | |||||
| 插值B | 15 | 15 | 15 | ||||
| B | 10 | na | 20 | 15 | 10 | na | 20 |
| Summed Result | 10 | 20 | 30 | 20 | 20 | 20 | 20 |
原文表格如下: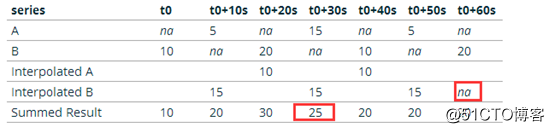
更多示例:
对于图形倾斜我们有以下示例。在OpenTSDB中记录了一个虚构的指标m。“sum of m”是由查询start=1h-ago&m=sum:m产生的顶部的蓝线。它是由红线host=foo和绿线host=bar的和组成的。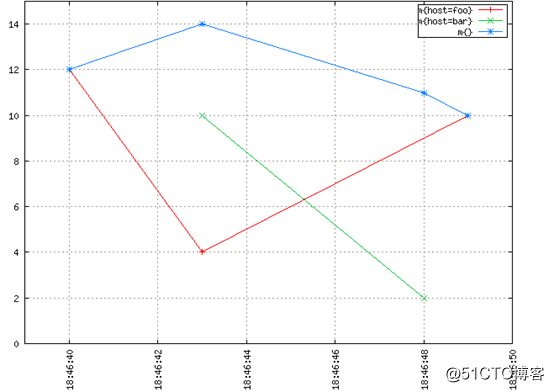
从上面的图像看起来很直观,如果“叠加”红线和绿线,会得到蓝线。在任何离散的时间点,蓝线的值等于当时红线值和绿线值的和。如果没有插值,会得到一些比较不直观的东西,这样很难理解,而且它也没有那么有意义和有用。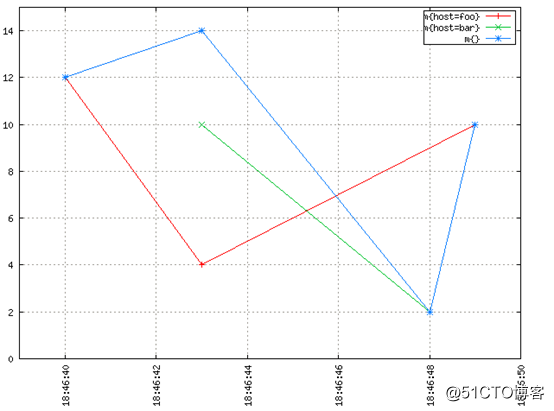
注意18:46:48蓝线如何下降到绿色数据点。不需要成为一名数学家,也不需要高级数学课程才能看到需要进行插值,才能将多个时间序列正确的聚合在一起并获得有意义的结果。
目前OpenTSDB主要支持线性插值(缩写”lerp”)以及一些简单的替换0或最大值或最小值的聚合器。欢迎大家添加其他插值算法来修补程序。
插值仅在查询时发现多个时间序列与查询匹配时执行。许多指标采集系统在写入是进行插值,以便您永远不会记录原始值。OpenTSDB存储原始值,并且可以随时检索它。
这是来自邮件列表的另一个稍微复杂的例子,描述了多个时间序列按照平均值聚合的情况: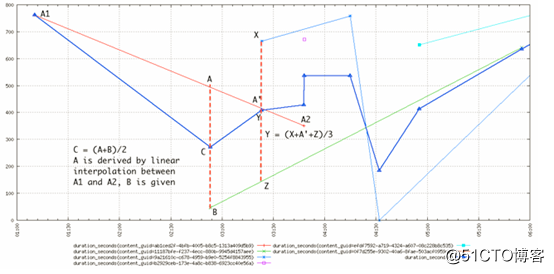
带有三角形的粗蓝线是根据查询(start=1h-ago&m=avg:duration_seconds)具有多个时间序列avg函数的聚合。正如我们所看到的,由此产生的时间序列在其聚合的所有基础时间序列的每个时间戳上都有一个数据点,并且该数据点是通过取得该时间戳的所有时间序列值的平均值来计算的。对于紫色方形的孤独数据点也是如此,这样将暂时提高平均值知道下个数据点。
注意:
聚合函数根据输入数据点返回整数或者双精度值。如果两个原值在存储中均为整数,则计算结果将为整数。这意味着由计算得到的任何小数值将被删除,不会发生舍入。如果任一数据点是浮点值,则结果将是浮点数。但是如果启用降采样或者Rate,结果将始终为浮点数。
降采样
如上所述,插值是处理丢失数据的一种手段。但有些用户不喜欢线性插值,它是一种产生lie数据的方式,会产生幻像值。相反,处理未对齐值的另一种方法是通过降采用。例如:源每分钟报告一个值,但是在那一分钟内他们会发生时间偏移,那么对于源数据中的每个查询,在1分钟内提供一次降采用。这将在每个时间序列有显著的值,使用与插值相同的时间戳大多是可以避免的。当降采样的桶丢失一个值时,插值仍然会发生。
有关避免插值的详细信息和示例,请参见降采样。
注意:
总体来说,对于包含多个时间序列的每个查询进行降采样是一个很好的理想选择 。
可用聚合器
以下是对OpenTSDB中可用的聚合函数描述。请注意,有些应该只用于分组,其他则用于降采样。
| 聚合器 | TSD版本 | 描述 | 插值 |
|---|---|---|---|
| avg | 1.0 | 数据点平均值 | 线性插值 |
| count | 2.2 | 集合中原始数据点的数量 | 0替换缺失值 |
| dev | 1.0 | 计算标准差 | 线性插值 |
| Ep50r3 | 2.2 | 使用R-3方法计算估计的50% | 线性插值 |
| Ep50r7 | 2.2 | 使用R-7方法计算估计的50% | 线性插值 |
| Ep75r3 | 2.2 | 使用R-3方法计算估计的75% | 线性插值 |
| Ep75r7 | 2.2 | 使用R-7方法计算估计的75% | 线性插值 |
| Ep90r3 | 2.2 | 使用R-3方法计算估计的90% | 线性插值 |
| Ep90r7 | 2.2 | 使用R-7方法计算估计的90% | 线性插值 |
| Ep95r3 | 2.2 | 使用R-3方法计算估计的95% | 线性插值 |
| Ep95r7 | 2.2 | 使用R-7方法计算估计的95% | 线性插值 |
| Ep99r3 | 2.2 | 使用R-3方法计算估计的99% | 线性插值 |
| Ep99r7 | 2.2 | 使用R-7方法计算估计的99% | 线性插值 |
| Ep999r3 | 2.2 | 使用R-3方法计算估计的999% | 线性插值 |
| Ep999r7 | 2.2 | 使用R-7方法计算估计的999% | 线性插值 |
| first | 2.3 | 返回集合中的第一个数据点。仅仅对降采样有用,对聚合无用 | 不定 |
| last | 2.3 | 返回集合中的最后一个数据点。仅仅对降采样有用,对聚合无用 | 不定 |
| mimmin | 2.0 | 筛选最小的数据点 | 线性插值 |
| mimmax | 2.0 | 筛选最大的数据点 | 线性插值 |
| min | 1.0 | 筛选最小的数据点 | 线性插值 |
| max | 1.0 | 筛选最大的数据点 | 线性插值 |
| none | 2.3 | 通过所有时间序列的聚合跳过组 | 0替换缺失值 |
| p50 | 2.3 | 计算50% | 线性插值 |
| p75 | 2.3 | 计算75% | 线性插值 |
| p90 | 2.3 | 计算90% | 线性插值 |
| p95 | 2.3 | 计算95% | 线性插值 |
| p99 | 2.3 | 计算99% | 线性插值 |
| p999 | 2.3 | 计算999% | 线性插值 |
| sum | 1.0 | 将数据点一起求和 | 线性插值 |
| zimsum | 1.0 | 将数据点一起求和 | 0替换缺失值 |
获取百分比计算,阅读维基百科文章。对高基数的计算,使用估计百分比性能更好。
Avg
计算降采样桶或跨多个时间序列所有值的平均值。该函数将在事件序列上执行线性插值。这对于查看gauge指标非常有用。
注意:
即使计算通常会导致浮点值,但如果数据点以整数记录,则会返回一个整数,从而失去一些精度。
Count
返回存储在序列或者范围中的数据点的数量。当用于聚合多个序列是,将使用0替换缺失值。与将采样一起使用时,它将反映每个降采样桶中数据点的数量。用于分组聚合时,反映了给定时间的值与时间序列的数量。
Dev
计算一个桶或时间序列的标准差。该函数将在事件序列上执行线性插值。这对于查看gauge指标非常有用。
注意:
即使计算通常会导致浮点值,但如果数据点以整数记录,则会返回一个整数,从而失去一些精度。
Estimated Percentiles
使用算法选择计算各种百分比。这些对于有很多数据点的序列很有用,因为有些数据可能会被踢出计算。用于聚合多个序列时,该函数将执行线性插值。详情请参阅维基百科。实现是通过Apache Math库实现的。
First &Last
这两个聚合器将返回降采样间隔中的第一个或最后一个数据点。例如,如果降采样桶由序列2, 6, 1, 7组成,那么first聚合器将返回2(原文为1),last聚合器将返回7。注意该聚合器仅仅对降采样有用。
警告:
当用作group-by聚合器时,结果是不确定的,因为从存储中检索读取并保存在内存中的时间序列排序从TSD到TSD或从执行到执行不一致。
Min
返回所有时间序列或时间范围内最小的数据点。该函数将在事件序列上执行线性插值。查看gauge指标的下限很有用处。
Max
与min相反,返回所有时间序列或时间范围内最大的数据点。该函数将在事件序列上执行线性插值。查看gauge指标的上限很有用处。
MimMin
“缺失最小值时的最大值”函数仅返回所有时间序列或时间范围内的最小数据点。该函数不会执行插值,而是会返回指定的数据类型的最大值(如果值缺失)。这将返回整数Long.MaxValue或浮点值Double.MaxValue。详情请参阅原始数据类型。这对于查看gauge指标的下限非常有用。
MimMax
“缺失最大值时的最大值”函数仅返回所有时间序列或时间范围内的最大数据点。该函数不会执行插值,而是会返回指定的数据类型的最小值(如果值缺失)。这将返回整数Long.MinValue或浮点值Double.MinValue。详情请参阅原始数据类型。这对于查看gauge指标的上限非常有用。
None
通过聚合跳过组。此聚合器对于从存储中获取原始数据非常有用,因为它将为每个匹配过滤器的时间序列返回一个结果集。请注意:查询将在与降采样器一起使用时引发异常。
Percentiles
计算各种百分比。用于聚合多个序列时,该函数将执行线性插值。实现是通过Apache Math库实现的。
Sum
如果降采样,计算所有时间序列或时间范围内的所有数据点的总和。它是GUI的默认聚合函数,因为它在组合多个时间序列(例如gauges或count)时通常最有用。当数据点无法排列时,它执行线性插值。如果有不同序列的值,你又想求和时不需要插值,看一下zimsum函数。
ZimSum
根据所有时间序列或时间范围内指定的时间戳计算所有数据点的总和。此函数不能进行插值,而是一个用0替代缺失的数据点。这在使用离散值时很有用。
聚合器列表
在启用HTTP API的TSD中调用HTTP接口/api/aggregators,将列出TSD实现的聚合器列表。