引言
泛型实现了参数化类型的概念,使代码可以应用于多种类型,通过解耦类或方法与所使用的类型之间的约束来实现。java泛型设计的一个很重要原因就是容器类。
1.简单的泛型
泛型的主要目的之一就是用来指定容器要持有什么类型的对象,而且由编译器来保证类型的正确性。泛型类型也就是另一种类型罢了,只是用来限制类型,容易误导的一点,类字面常量 .class用法是:类.class,不可用于泛型。
下面来看一个简单的例子:
public class B{
public void f(){
System.out.println("b.f()");
}
}
public class A<T> {
private T obj;
public A(T x){
obj=x;
}
//Eror :cannot find symbol:method f():
public void test(){
//obj.f();//error
//new T();//error
//T.class;//error
//new T[2];//error
}
public static void main(String[] args) {
B b=new B();
A<B> a=new A<B>(b);
a.test();
}
}我们可以看到在A的test()方法中,不能通过类型参数来new一个新对象,也不能使用.class字面量,更不能创建数组。这是因为类型参数T只是一个符号,他可以指代任何对象类型,哦,基本类型不能用作类型参数,但是由于擦除的原因,我们在A中的看不到任何B的类型信息。
2.泛型接口
泛型也可以应用于接口。例如生成器,这是一种专门负责创建对象的类。实际上,这是工厂方法设计模式的一种应用。不过,当使用生成器创建新的对象的时候,它不需要任何参数,而工厂方法一般需要参数。也就是说,生成器无需额外的信息就知道如何创建新对象。
一般而言,一个生成器制定以一个方法,以该方法用以产生新的对象。在这里,就是next方法。
public interface Generator<T> {
T next();
}方法next()的返回函数是参数化的T。正如你所见到的,接口使用泛型与类使用泛型没有什么区别。
3.泛型方法
泛型既可以应用于整个类上,也可以在类中包含参数化方法,而这个方法所在的类可以是泛型类,也可以不是泛型类。也就是说,是否拥有泛型方法,与其所在的类是否是泛型没有关系。
泛型方法使得该方法能够独立于类而产生变化。以下是一个基本的指导原则:无论何时,只要你能做到,你就应该尽量使用泛型方法。对于一个static的方法而言,无法访问泛型类的类型参数,所以,如果static方法需要使用泛型能力,就必须使其成为泛型方法。
要定义泛型方法,只需要将泛型参数列表置于返回值之前,就像下面一样。
public class GenericMethods {
public <T> void f(T t){
System.out.println(t.getClass().getName());
}
public <T,U,V> void g(T t,U u,V v){
System.out.println("1:"+t.getClass().getName()+"\r2:"
+u.getClass().getName()+"\r3:"+v.getClass().getName());
}
public <T,U> void h(T t,U u,String v){
System.out.println("1:"+t.getClass().getName()+"\r2:"
+u.getClass().getName());
}
public static void main(String[] args){
GenericMethods gm=new GenericMethods();
gm.f("123");
gm.f(0.1);
gm.f(0.1f);
gm.f('a');
gm.f(gm);
gm.g("123", 'b',0.1);
gm.h(0.2, 0.4f, "123");
}
}GenericMethods并不是参数化的,尽管这个类和其内部的方法可以被同时参数化,但是在这个例子中,只有f()拥有类型参数。这是由该方法的返回类型前面的类型参数列表指明的。
注意,当使用泛型类时,必须在创建对象的时候指定类型参数的值,如果没有指定类型参数,那就和使用object类型一样。而使用泛型方法的时候,通常不必指明参数类型,因为编译器会为我们找到具体的类型。这称为类型参数推断。因此,我们可以像调用普通方法一样调用f(),而且就好像f()被无限次的重载过。他甚至可以接受GenericMethods作为类型参数。如果调用f()时传入基本类型,自动打包机制就会介入其中,将基本类型的值包装为对应的对象。事实上,泛型方法与自动打包避免了以前我们不得不自己编写出来的代码。
3.1 杠杆利用类型参数推断
人们对类型有一个抱怨,就是有时候需要向程序中加入更多的代码,例如创建一个持有List的Map,就要向下面这样:
Map<Person,List<? extends Pet>> petPeople=new HashMap<Person,List<? extends Pet>>();
看到了吧,你在重复自己做过的事情,编译器本来应该能够从泛型参数列表中的一个参数推断出另一个参数,但是编译期目前还做不到。然而,在泛型方法中,类型参数推断可以为我们简化一部分工作。例如,我们可以编写一个工具类,它包含各种各样的static方法,专门用来创建各种常用的容器对象:
public class New {
public static <K,V> Map<K,V> map(){
return new HashMap<K,V>();
}
public static <T> List<T> list(){
return new ArrayList<T>();
}
public static <T> LinkedList<T> lList(){
return new LinkedList<T>();
}
public static <T> Queue<T> queue(){
return new LinkedList<T>();
}
public static void main(String[] args) {
Map<String,String> map=New.map();
List<Integer> list=New.list();
LinkedList llist=New.lList();
Queue<String> queue=New.queue();
}
}Main方法演示了如何使用这个工具类,类型参数推断避免了重负的类型参数列表。对于类型参数推断而言,这是一个有趣的例子。不过,很难说他为们带了了多少好处。类型推断只对赋值操作有效,其他时候并不起作用,如果你将一个泛型方法调用的结果(例如New.map())作为参数,传递给另一个方法,这时编译器并不会执行类型推断。在这种情况下,编译器认为:调用泛型方法后,其返回值被赋值给了Object类型的变量。下面的例子证明了这一点:
public class LimitsOfInference {
static void f(Map<People,List<? extends Pet>> petPeople){
}
public static void main(String[] args) {
//!f(New.map());无法编译
}
}(2)显示的类型说明
在泛型方法中,可以显示的指明类型,不过这种语法很少使用。要显示的指明类型,必须在点操作符与方法名之间插入尖括号,然后将类型置于尖括号中。如果在定义该方法的类的内部,必须在点操作符之前使用this关键字,如果是使用了static的方法,必须在点操作符之前加上类名。使用这种语法,可以解决LimitsOfInfereace.java中的问题:
public class ExplicitTypeSpecification {
static void f(Map<People,List<Pet>> petPeople){
}
public static void main(String[] args) {
f(New.<People,List<Pet>>map());
}
}3.2 可变参数与泛型方法
泛型方法与可变参数列表能够很好的共存:
public class GenericVarargs {
public static <T> List<T> createList(T...args){
List<T> list=new ArrayList<T>();
for(T t:args)
list.add(t);
return list;
}
public static void main(String[] args) {
List ls=createList("a");
System.out.println(ls);
ls=createList("a","b","c");
System.out.println(ls);
}
}CreateList()方法展示了与标准类库中java.util.Arrays.asList()方法相同的功能。
总结:泛型方法最重要的就是利用赋值操作(传入的参数类型和函数返回类型)来进行类型推断,简化代码书写.
4.泛型-擦出的神秘之处
当你开始更深入地钻研泛型时,会发现有大量的东西初看起来是没有意义的。例如,尽管可以声明ArrayList.class,但是不能声明ArrayList<Integer>.class。请考虑下面的情况:
public class ErasedTypeEquivalence {
public static void main(String[] args) {
Class c1=new ArrayList<String>().getClass();
Class c2=new ArrayList<Integer>().getClass();
System.out.println(c1==c2);
}
}ArrayList<String>和ArrayList<Integer>很容易被认为是不同的类型。不同的类型在行为方面肯定不同,例如,如果尝试将一个Integer放入ArrayList<String>,所得到的行为(将失败)与把一个Integer放入ArrayList<Integer>(将成功)得到的行为完全不同。但是上面的程序会认为他们是相同的类型。
下面的示例是对这个谜题的一个补充:
public class LostInformation {
public static void main(String[] args) {
List<Frob> list=new ArrayList<Frob>();
Map<Frob,Fnorkle> map=new HashMap<Frob,Fnorkle>();
Quark<Fnorkle> quark=new Quark<Fnorkle>();
Particle<Long,Double> p=new Particle<Long,Double>();
System.out.println(Arrays.toString(list.getClass().getTypeParameters()));
System.out.println(Arrays.toString(map.getClass().getTypeParameters()));
System.out.println(Arrays.toString(quark.getClass().getTypeParameters()));
System.out.println(Arrays.toString(p.getClass().getTypeParameters()));
}
}
class Frob{}
class Fnorkle{}
class Quark<Q>{}
class Particle<POSITION,MOMENTUM>{}
输出结果为:
[E]
[K, V]
[E]
[POSITION, MOMENTUM]根据JDK文档的描述,Class.getTypeParameters()将“返回一个TypeVariable对象数组,表示有泛型声明所声明的类型参数.....”这好像是在暗示你可能发现参数类型的信息,但是,正如你输出看到的,你能够发现的只是用作参数占位符的标识符,这并非是有用的信息。
因此,残酷的现实是:
在泛型内部,无法获得任何有关泛型参数类型的信息。
因此,你可以知道诸如类型参数标识符和泛型类型边界这类的信息--你却无法知道用来创建某个特定实例的实际的类型参数。如果你曾经是C++程序员,那么这个事实肯定让你觉得很沮丧,在使用Java泛型工作时它是必须处理的最基本的问题。
Java泛型是使用擦除来实现的,这意味着当你在使用泛型时,任何具体的类型信息都将擦出了,你唯一知道的就是你在使用一个对象。因此List<String>和List<Integer>在运行时事实上是相同的类型。这两种形式都被擦除他们的“原生”类型,即List。理解擦出以及应该如何处理它,是你在学习Java泛型时面临的最大的障碍。
4.1 泛型-擦除的问题
擦除的主要的正当理由是从非泛化代码到泛化代码的转变过程,以及在不破坏现有类库的情况下,将泛型融入到Java语言。擦除使得现有的非泛型客户端代码能够在不改变的情况下继续使用,直至客户端准备好用泛型重写这些代码。这是一个崇高的动机,因为他不会突然间破坏现有所有的代码。
擦除的代价是显著的。泛型不能用于显式地引用运行时类型的操作之中,例如转型,instanceof操作和new表达式。因为所有关于参数的类型信息都丢失了,无论何时,当你在编写泛型代码时,必须时刻提醒自己,你只是看起来好像拥有有关参数的类型信息而已。因此,如果你编写了下面这样的代码段:
Class Foo<T>{
T var;
}那么看起来当你在创建Foo的实例时:
Foo<Cat> f=new Foo<Cat>();Class Foo中的代码应该知道现在工作于Cat之上,而泛型语法也在强烈暗示:在整个类中的各个地方,类型T都在被替换。但是事实并非如此,无论何时,当你在编写这个类的代码时,必须提醒自己:“不,他只是个Object”
另外,擦除和迁移兼容性意味着,使用泛型并不是强制的,尽管你可能希望这样:
public class GenericBase<T>{
private T element;
public void set(T arg){
arg=element;
}
public T get(){
return element;
}
}
public class Derived1<T> extends GenericBase<T>{
}
public class Derived2 extends GenericBase{
@SuppressWarnings("unchecked")
public static void main(String[] args) {
Derived2 d2=new Derived2();
Object obj=d2.get();
d2.set(obj);
}
}Derived2继承自GenericBase,但是没有任何泛型参数,而编译器不会发出任何警告。警告在set()被调用时候才会出现。
为了关闭警告,Java提供了一个注解,我们可以在列表中看到它(这个注解在JavaSE5之前的版本中不支持);@SuppressWarnings("unchecked")
注意,这个注解被放置在可以产生这类警告的方法之上,而不是整个类上。当你要关闭警告时,最好是尽可能的“聚焦”,这样就不会因为过于宽泛的关闭警告,而导致意外地遮蔽掉真正的问题。
当你希望将类型参数不要仅仅当做Object处理时,就需要付出额外的努力来管理边界。并且与在C++,Ada和Eiffel这样的语言中获得参数化类型相比,你需要付出多得多的努力来获得少的少的回报。这就是说,对于大多数的编程问题而言,这些语言通常都会比Java更得心应手,这就是说,他们的参数化类型机制比Java的更灵活,更强大。
4.2 边界处的动作
正是因为有了擦除,我发现泛型最令人困惑的方面源自这样一个事实,即可以表示任何没有意义的事物。例如:
public class ArrayMaker<T> {
private Class<T> kind;
public ArrayMaker(Class<T> kind){
this.kind=kind;
}
@SuppressWarnings("uncheckd")
T[] create(int size){
return (T[])Array.newInstance(kind, size);
}
public static void main(String[] args){
ArrayMaker<String> stringMaker=new ArrayMaker<String>(String.class);
String[] stringArray=stringMaker.create(9);
System.out.println(Arrays.toString(stringArray));
}
}即使kind被存储为Class<T>,擦除也意味着它实际被存储为Class,没有任何参数。因此当你在使用它时,例如在创建数组时,Array.newInstance()实际上并未拥有kind所蕴含的类型信息,因此这不会产生具体的结果,所以必须转型,这将产生一条令你无法满意的警告。
注意,对于在泛型中创建数组,使用Array.newInstance()是推荐的方式。
如果我们创建的是一个容器而不是数组,情况就有些不同了:
public class ListMaker<T> {
List<T> create(){
return new ArrayList<T>();
}
public static void main(String args){
ListMaker<String> stringMaker=new ListMaker<String>();
List<String> stringList=stringMaker.create();
}
}编译器不会给出任何警告,尽管我们(从擦除中)知道在create()内部的new ArrayList<T>中的<T>被移除了-在运行时,这个类的内部没有任何<T>,因此这看起来毫无意义。但是如果你遵从这种思路,并将这个表达式改为new ArrayList(),编译器就会给出警告。
在本例中,这是否真的毫无意义呢?如果返回List之前,将某些对象放入其中,就会像下面这样,情况又会如何呢?
public class FilledListMaker<T> {
List<T> create(T t,int n){
List<T> result=new ArrayList<T>();
for(int i=0;i<n;i++){
result.add(t);
}
return result;
}
public static void main(String[] args) {
FilledListMaker<String> stringMaker=new FilledListMaker<String>();
List<String> list=stringMaker.create("Hello",4);
System.out.println(list);
}
}即使编译器无法知道有关create()中的T的任何信息,但是他仍旧可以在编译期确保你设置到result中的对象具有T类型,使其适合ArrayList<T>。因此,即使擦除在方法或者类内部移除了有关实际类型的信息,编译器仍旧可以确保在方法或者类中使用的类型的内部一致性。
因为擦除在方法体中移除了类型信息,所以在运行时的问题就是边界:即对象进入和离开方法的地点。这些正是编译器在编译期执行类型检查并插入代码的地点。请考虑下面的非泛型示例:
public class SimpleHolder {
private Object obj;
public void set(Object obj){
this.obj=obj;
}
public Object get(){
return obj;
}
public static void main(String[] args) {
SimpleHolder holder=new SimpleHolder();
holder.set("Item");
String s=(String)holder.get();
}
}如果用javap -c SimpleHolder反编译这个类,就可以得到下面的内容
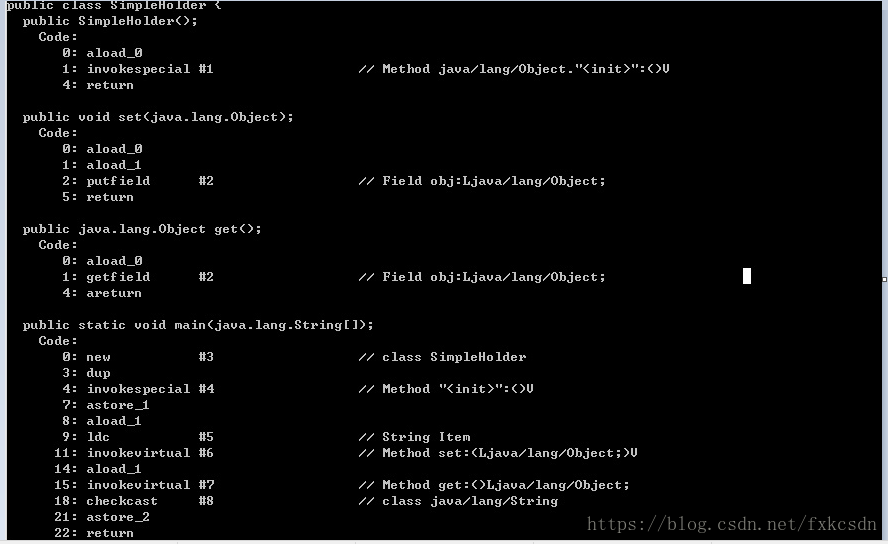
Set()和get()方法将直接存储和产生值,而转型是在调用get()的时候接受检查的。
现在将泛型合并到上面的代码中:
public class GenericHolder<T> {
private T obj;
public void set(T obj){
this.obj=obj;
}
public T get(){
return obj;
}
public static void main(String[] args) {
GenericHolder<String> holder=new GenericHolder<String>();
holder.set("item");
String s=holder.get();
}
}从get()返回之后的转型消失了,但是我们还知道传递给set()的值是在编译器会接受检查。下面是相关的字节码:
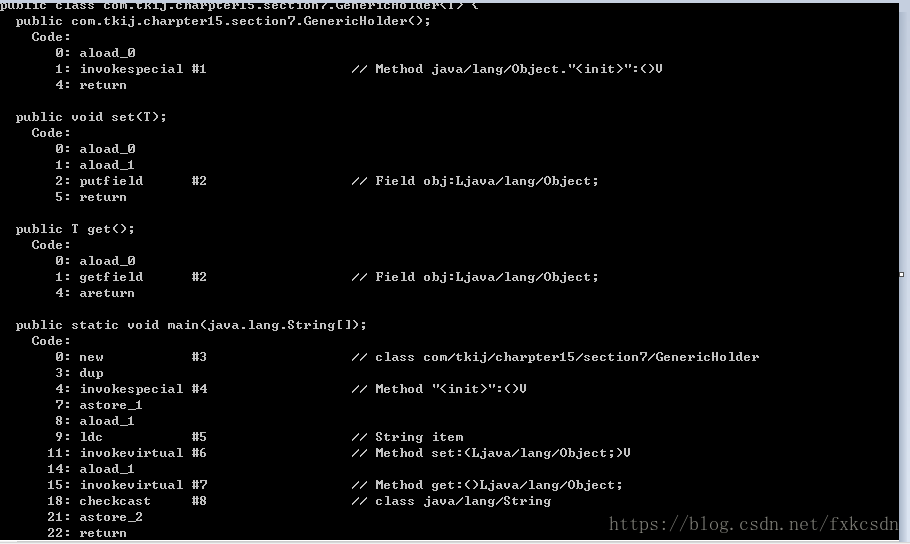
所产生的字节码是相同的。对进入set()的类型进行检查是不需要的。因为这将由编译器执行。而对从get()返回值进行转型仍旧是需要的,但这与你自己必须执行操作是一样的-此处它将由编译器自动插入,因此你写入(和读写)代码的噪声将更小。
由于所产生的get()和set()的字节码相同,所以在泛型中的所有动作都发生在边界处--对传递进来的值进行额外的编译期检查,并插入对传递出来的值的转型。这有助于澄清对擦除的混淆,记住。“边界就是发生动作的地方。”
泛型最重要的就是擦除和转型,而这些泛型动作都发生在边界处。
java编译器是通过先检查代码中泛型的类型,然后再进行类型擦除,在进行编译的。
而真正涉及类型检查的是它的引用//兼容老代码
泛型的擦除让类内部失去了泛型T的类型信息,指的是如果不通过传值给T,那么T就没有类型信息,也就不能用.class,new ,instanceOf等运行时关键字,
A<Integer> a = new A<Integer>();
if(a instanceof A<Integer>){ }//编译报错但是我们可以通过给T赋值,在构造器中传个Class<T> kind给Class<T> kind,那么kind就可以保存类型信息了。下面另一种就是多此一举:
public class ArrayMaker2<T> {
private T kind;
public ArrayMaker2(T kind){
this.kind=kind;
}
@SuppressWarnings("uncheckd")
T create(int size){
try{
kind.getClass().newInstance();
}catch(Exception e){
}
}如果这样做在new ArrayMaker2(new String())时还需要创建一个对象传进去,浪费空间,还不如直接用第一种方法,new ArrayMaker(String.class)直接把类信息传进去.
5.泛型数组
正如你在Erased.java所见到的,不能创建泛型数组。一般解决方案是在任何想要创建泛型数组的地方都使用ArrayList:
public class ListOfGenerics<T> {
private List<T> array=new ArrayList<T>();
public void add(T item){
array.add(item);
}
public T get(int index){
return array.get(index);
}
}这里你将获得数组的行为,以及由泛型提供的编译期的类型安全。
有时,你仍旧希望创建泛型类型的数组(例如,ArrayList内部使用的是数组)。有趣的是,可以按照编译器喜欢的方式来定义一个引用,例如:
public class ArrayOfGenericReference {
static Generic<Integer>[] gia;
}编译器将接受这个程序,而不会产生任何警告。但是,永远都不能创建这个确切类型的数组,因此这一点有点令人困惑。既然所有的数组无论他们持有的类型如入,都具有相同的结构(每个数组槽位的尺寸和数组的布局),那么看起来你应该能够创建一个Object数组,并将其转型为所希望的数组类型。事实上这可以通过 编译,但是不能运行,他将产生ClassCaseException:
public class ArrayOfGeneric {
static final int SIZE=100;
static Generic<Integer>[] gia;
@SuppressWarnings("unchecked")
public static void main(String[] args) {
//!gia=(Generic<Integer>[])new Object[SIZE];//类型转化异常
gia=(Generic<Integer>[])new Generic[SIZE];
System.out.println(gia.getClass().getSimpleName());
gia[0]=new Generic<Integer>();
//!gia[1]=new Object[];编译期异常
//!gia[2]=new Generic<Double>();编译期-类型不匹配
}
}问题在于数组将跟踪他们的实际类型,而这个类型是在数组被创建时确定的,因此,即使gia已经被转型为Generic<Integer>[],但是这个信息只存在于编译期。在运行时,它仍旧是Generic数组,而这将引发问题。成功创建泛型数组的唯一方式就是创建一个被擦除类型的新类型,然后对其转型。
让我们来看一个更复杂的实例,考虑一个简单的泛型数组包装器:
public class GenericArray<T> {
private T[] array;
@SuppressWarnings("unchecked")
public GenericArray(int size){
array=(T[])new Object[size];
}
public void put(int index,T item){
array[index]=item;
}
public T get(int index){
return array[index];
}
public T[] rep(){
return array;
}
public static void main(String[] args) {
GenericArray<Integer> gai=new GenericArray<Integer>(10);
//Integer[] ia=gai.rep();//this causes a classCastException
Object[] oa=gai.rep();//this is ok;
}
}与前面相同,我们并不能声明T[] array=new T[sz],因此我们创建了一个对象数组,然后将其转型。
Rep()方法将返回T[],它在main()中将用于gai,因此应该是Integer[],但是如果调用它,并尝试将结果作为Integer[]引用来捕获,就会得到ClassCastException,这是因为实际的运行时类型是Object[].
因为有了擦除,数组的运行时类型就只能是Object[]。如果我们立即将其转型为T[],那么在编译期该数组的实际类型就将丢失,而编译器可能会错过某些潜在的类型错误检查。正因为这样,最好在集合内部使用Object[],然后当你使用数组元素时,添加一个对T的转型。让我们看看这是如何作用于GenericArray.java示例的:
public class GenericArray2<T> {
private Object[] array;
public GenericArray2(int size){
array=new Object[size];
}
public void put(int index,T item){
array[index]=item;
}
public T get(int index){
return (T)array[index];
}
public T[] rep(){
return (T[])array;
}
public static void main(String[] args) {
GenericArray2<Integer> gai=new GenericArray2<Integer>(10);
for(int i=0;i<10;i++){
gai.put(i, i);
}
for(int i=0;i<10;i++){
System.out.println(gai.get(i)+"");
}
System.out.println();
try{
Integer[] ia=gai.rep();
}catch(Exception e){
System.out.println(e);
}
}
}初看起来,这好像没多大的变化,只是转型挪了地方。如果但是现在的内部表示是Object[]而不是T[]。当get()被调用时,他将对象转型为T,这实际上是正确的类型,因此这是安全的。然而,如果你调用rep(),他还是尝试着将Object[]转型为T[],这仍旧是不正确的,将在编译期产生警告,在运行时产生异常。因此,没有任何方式可以推翻底层的数组类型,他只能是Object[].在内部将array当作Object[]而不是T[]处理的优势是:我们不太可能忘记这个数组的运行时类型,从而意外的引入缺陷。
对于新代码,应该传递一个类型标记。在这种情况下,GenericArray看起来就会像下面这样:
public class GenericArrayWithTypeToken<T> {
private T[] array;
@SuppressWarnings("unchecked")
public GenericArrayWithTypeToken(Class<T> type,int sz){
//array=(T[])new Object[sz];//会丢失类型信息
array=(T[])Array.newInstance(type,sz);
}
public void put(int index,T item){
array[index]=item;
}
public T get(int index){
return array[index];
}
public T[] rep(){
return array;
}
public static void main(String[] args) {
GenericArrayWithTypeToken<Integer> gai=new GenericArrayWithTypeToken<Integer>(Integer.class,10);
Integer[] ia=gai.rep();
System.out.println(java.util.Arrays.asList(ia));
}
}类型标记Class<T>被传递到构造其中,以便在擦除中恢复,使得我们可以创建需要的实际类型的数组,一旦我们获得了实际类型,就可以返回他,并获得想要的结果,就会在main()中看到的那样,该数组的运行时类型是确切类型T[].
6.泛型边界
边界使得你可以在用于泛型的类型参数上设置限制条件。尽管这使得你可以强制规定泛型可以应用的类型,但是其潜在的一个更重要的效果是你可以按照自己的边界类型来调用方法。
因为擦除移除了类型信息,所以,可以用无界泛型参数调用的方法只是那些可以用Object
调用的方法。但是i,如果能够将这个参数限制为某个类型的子集,那么你就可以用这些类型子集来调用方法。为了执行这种限制,Java泛型重用了extends关键字。对你来说这一点很重要,即要理解extends关键字在泛型边界上下文环境中和普通情况下所具有的意义完全不同。下面的示例展示了边界的基本要素:
interface HasColor{
java.awt.Color getColor();
}
class Colored<T extends HasColor>{
T item;
Colored(T item){
this.item=item;
}
T getItem(){
return item;
}
java.awt.Color color(){
return item.getColor();
}
}
class Dimension{
public int x,y,z;
}
class ColoredDimension<T extends Dimension&HasColor>{
T item;
ColoredDimension(T item){
this.item=item;
}
T getItem(){
return item;
}
java.awt.Color color(){
return item.getColor();
}
int getX(){
return item.x;
}
int getY(){
return item.y;
}
int getZ(){
return item.z;
}
}
interface Weight{
int weight();
}
class Solid<T extends Dimension&HasColor&Weight>{
T item;
Solid(T item){
this.item=item;
}
T getItem(){
return item;
}
java.awt.Color color(){
return item.getColor();
}
int getX(){
return item.x;
}
int getY(){
return item.y;
}
int getZ(){
return item.z;
}
int weight(){
return item.weight();
}
}
class Bounded extends Dimension implements HasColor,Weight{
public java.awt.Color getColor(){
return null;
}
public int weight(){
return 0;
}
}
public class BasicBounds {
public static void main(String[] args) {
Solid<Bounded> solid=new Solid<Bounded>(new Bounded());
solid.color();
solid.getY();
solid.weight();
}
}你可能已经观察到了,BasicBounds.java看上去包含可以通过继承消除的冗余,下面,可以看到如何在继承的每个层次上添加边界限制:
class HoldItem<T>{
T item;
HoldItem(T item){
this.item=item;
}
T getItem(){
return item;
}
}
class Colored2<T extends HasColor> extends HoldItem<T>{
Colored2(T item){
super(item);
}
java.awt.Color color(){
return item.getColor();
}
}
class ColoredDimension2<T extends Dimension&HasColor> extends Colored2<T>{
ColoredDimension2(T item){
super(item);
}
int getX(){
System.out.println("123");
return item.x;
}
int getY(){
return item.y;
}
int getZ(){
return item.z;
}
}
class Solid2<T extends Dimension&HasColor&Weight> extends ColoredDimension2<T>{
Solid2(T item){
super(item);
}
int weight(){
return item.weight();
}
}
public class InheritBounds {
public static void main(String[] args) {
Solid2<Bounded> solid2=new Solid2<Bounded>(new Bounded());
solid2.weight();
solid2.getX();
solid2.color();
}
}HoldItem直接持有一个对象,因此这种行为被继承到了Colored2中,他要求其参数与HasColor一致。ColoredDimension2和Solid2进一步扩展了这个层次结构,并在每个层次都添加了边界。
7.泛型通配符
我们开始入手的实例要展示数组的一种特殊行为:可以向导出类型的数组赋予基类型的数组引用:
class Fruit{}
class Apple extends Fruit{}
class Jonathan extends Apple{}
class Orange extends Fruit{}
public class CovariantArrays {
public static void main(String[] args) {
Fruit[] fruit=new Apple[10];//数组貌似支持向上转型(实际并不支持转型)
fruit[0]=new Apple();
fruit[1]=new Jonathan();
try{
fruit[0]=new Fruit();
}catch(Exception e){
System.out.println(e);
}
try{
fruit[0]=new Orange();
}catch(Exception e){
System.out.println(e);
}
}
}Main()中的第一行创建了一个Apple数组,并将其赋值给一个Fruit数组引用.这是有意义的,因为Apple也是一种Fruit,因此Apple数组应该也是一个Fruit数组。
但是,如果实际的数组类型是Apple[],你应该只能在其中放置Apple或者Apple的子类型,这在编译器和运行期都可以工作。但是请注意,编译器允许你将Fruit放置到这个数组中,这对于编译器来说是有意义的,因为它有一个Fruit[]引用-他有什么理由不允许将Fruit对象或者任何从Fruit继承出来的对象(例如Orange),放置到这个数组中呢?因此,在编译期,这是允许的。但是运行时的数组机制知道他要处理的是Apple[],因此会在向数组中放置异构类型时抛出异常。
实际上,向上转型不适合用在这里。你真正做的是将一个数组赋值给另一个数组。数组的行为应该是它可以持有其他类型,这里只是我们能够向上转型而已,所以很明显,数组对象可以保留有关他们包含的对象类型的规则。就好像数组对他们持有的对象是有意识的,因此在编译期检查和运行期检查之间,你不能滥用他们。
对数组的这种赋值并不是那么可怕,因为在运行时可以发现你已经插入了不正确的类型。
但是泛型的主要目标之一是将这种错误检测移入到编译器。因此当我们试图使用泛型容器来代替数组时,会发生什么?
public class NonCovariantGenerics {
//编译错误,类型转换错误
//!List<Fruit> flist=new ArrayList<Apple>();
public static void main(String[] args) {
List<Fruit> flist=new ArrayList<Fruit>();
flist.add(new Apple());
}
}尽管你在第一次阅读这段代码时会认为:“不能将一个Apple容器赋值给Fruit容器”。
别忘了,泛型不仅和容器相关正确的说法是“不能将一个涉及Apple的泛型赋值给一个涉及Fruit的泛型”,如果就像数组的情况中一样,编译器对代码的了解足够多,可以确定多涉及到的容器,那么他可能会留下一些余地。但是他不知道任何有关这方面的信息,因此他拒绝向上转型。然而实际上这根本不是向上转型-Apple的list不是Fruit的List.Apple的list将持有Apple和Apple的子类型,而Fruit的list将持有任何类型的Fruit,诚然,这包括Apple在内,但是他不是一个Apple的List,他仍旧是Fruit的List。Apple的list在类型上不等价于Fruit的List,即使Apple是一种Fruit类型.
真正的问题是我们在谈论容器的类型,而不是容器持有的类型。与数组不同,泛型没有内建的协变类型。这是因为数组在语言中是完全定义的,因此可以内建了编译期和运行时的检查,但是在使用泛型时,编译器和运行时系统都不知道你想用类型做些什么,以及应该采用什么样的规则。
但是,有时你想要在两个类型之间建立某种关系的向上转型关系,这正是通配符所允许的:
public class GenericsAndCovariance {
public static void main(String[] args) {
List<? extends Fruit> flist=new ArrayList<Apple>();
//complie error:can't add any type of object
//!flist.add(new Apple());
//!flist.add(new Fruit());
//!flist.add(new Object());
flist.add(null);//legal but uninteresting
//wo know that it returns at least Fruit;
Fruit f=flist.get(0);
}
}Flist类型现在时List<? extends Fruit>,你可以将其读作“具有任何从Fruit继承的类型的列表也包括Fruit”.但是,这实际上并不意味着这个List将持有任何类型的Fruit。通配符引用的是明确的类型,因此它意味着“某种flist”引用没有指定的具体类型。因此这个被赋值的List必须持有诸如Fruit或者Apple这样的某种指定类型,但是为了向上转型为flist。这个类型是什么并没有人关心。
如果唯一的限制是这个List要持有某种具体的Fruit或者Fruit的子类型,但是你实际上并不关心他是什么,那么你能用这样的List做什么呢?如果不知道List持有的是什么类型,那么你怎样才能安全的向其中添加对象呢?就像CovariantArrays.java中向上转型数组一样,你不能,除非编译器而不是运行时系统可以阻止这种操作的发生。你很快就会发现这一个问题。
你可能认为,事情变得有点走极端了,因为现在你甚至不能向刚刚声明过的持有Apple对象的List放置一个Apple对象了。是的,但是编译器并不知道这一点。List<? extends Fruit>可以合法地指向一个List<Orange>。一旦执行这种类型的向上转型,你就丢失掉向其中传递任何对象的能力,甚至是传递Object也不行。
另一方面,如果你调用了一个返回Fruit的方法,则是安全的,因为你知道这个List中的任何对象至少具有Fruit类型,因此编译器将允许这么做。
7.1 编译器有多聪明
现在,你可能会猜想自己被阻止去掉用任何接收参数的方法,但是请考虑下面的程序:
public class CompilerIntelligence {
public static void main(String[] args) {
List<? extends Fruit> flist=Arrays.asList(new Apple());
Apple a=(Apple)flist.get(0);
flist.contains(new Apple());
flist.indexOf(new Apple());
}
}你可以看到,对contains()和indexOf()调用,这两个方法都接受Apple对象作为参数,而这些调用都可以正常执行。这是否意味着编译器实际上将检查代码,以查看是否有某个特定的方法修改了它的对象?
通过查看ArrayList的文档,我们发现,编译器并没有那么聪明,尽管add()将接受一个具有泛型参数类型的参数,但是contains()和indexOf()将接受Object类型的参数。因为当你指定一个ArrayList<? extends Fruit>时,add()的参数就变成了“? extends Fruit”。
从这个描述中,编译器并不能了解这里需要Fruit的那个具体子类型,因此他将不会接受任何类型的Fruit。(向下转型不安全,如果? extends Fruit是Apple的子类甚至多重孙子,那么你传递一个Orange对象进去,显然不可以,也就是? extends fruit根本不知道是那个具体子类,所以你传递任何Fruit子类对象都不可以,思考:如果是? super Fruit呢,是不是就可以传递Fruit子类对象了呢,答案见下一节,逆变)
7.2 泛型逆变-超类型通配符
还可以走另一条路,即使用超类型通配符。这里,可以声明通配符是由某个特定类的任何基类来界定的,方法是指定<? super MyClass>,甚至或者使用类型参数:<? super T>(尽管你不能对泛型参数给出一个超类型边界;既不能声明<T super MyClass>.这使得你可以安全地传递一个类型对象到泛型类型中。因此,有了超类型通配符,就可以向Collection写入了:
public class SuperTypeWildcards {
static void writeTo(List<? super Apple> apples){
apples.add(new Apple());
apples.add(new Jonathan());
//!apples.add(new Fruit());//Error
}
}参数Apple是Apple的某种基类型的List,这样你就知道向其中添加Apple或者Apple的子类型是安全的。但是,既然Apple是下界,那么你就可以知道向这样的List中添加Fruit是不安全的,因为这将使这个List敞开口子,从而可以向其中添加非Apple类型的对象,而这是违反静态类型安全的。
因此你可能会根据如何能够向一个泛型类型“写入”(传递给一个方法),以及如何能够从一个泛型类型中“读取”(从一个方法中返回),来着手子类型和超类型边界。
超类型边界放松了在可以向方法传递的参数上所做的限制:
public class GenericWriting {
static <T> T readExact(List<T> list){
return list.get(0);
}
static List<Apple> apples=Arrays.asList(new Apple());
static List<Fruit> fruit=Arrays.asList(new Fruit());
static void f1(){
Apple a=readExact(apples);
Fruit f=readExact(fruit);
f=readExact(apples);
}
static class Reader<T>{
T readExact(List<T> list){
return list.get(0);
}
}
static void f2(){
Reader<Fruit> fruitReader=new Reader<Fruit>();
Fruit f=fruitReader.readExact(fruit);
readExact(fruit);
//Fruit a=fruitReader.readExact(apples);//error
}
static class CovariantReader<T>{
T readCovariant(List<? extends T> list){
return list.get(0);
}
}
static void f3(){
CovariantReader<Fruit> fruitReader=new CovariantReader<Fruit>();
Fruit f=fruitReader.readCovariant(fruit);
Fruit a=fruitReader.readCovariant(apples);
}
public static void main(String[] args) {
f1();f2();f3();
}
}与前面一样,第一个方法readExact()中使用了精确的类型。因此如果使用这个没有任何通配符的精确类型,就可以向List中写入和读取这个精确类型。另外,对于返回值,静态的泛型方法readExact()可以有效地“适应”每个方法的调用,并能够从List<Apple>中返回一个Apple,从List<Fruit>中返回一个Fruit,就像在f1()中看到的那样。因此,如果可以摆脱静态泛型方法,那么当只是读取时,就不需要协变类型了。
但是,如果有一个泛型类,那么当你创建这个类的实例时,要为这个类确定参数。就像在f2()中看到的,fruitReader实例可以从List<Fruit>中读取一个Fruit,因为这就是他的确切类型。但是List<Apple>还应该产生Fruit对象,而fruitReader不允许这么做。
为了修正这个问题,CovariantReader.readCovcariant()方法将接受List<? extends T>,因此从这个列表中读取一个T是安全的(你知道在这个类表中的所有对象至少是一个T,并且可能是从T导出的某种对象).在f3()中,你可以看到现在可以从List<Apple>中读取Fruit了。
总结如下:
泛型上下界,? extends Myclass 即是上界,对于此种泛型参数,只可以读取,不可以赋值,读取时用 Myclass c=get();自动向上转型。? super Myclass即是下界,对于此种泛型参数,只可以赋值,不可读取,赋值时可以将Myclass类及其子类赋值给类型参数。其实都是向下转型在作怪。
package com.ray.ch13;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) {
ArrayList<? super Fruit> list = new ArrayList<Fruit>();
// ArrayList<? super Fruit> list2 = new ArrayList<Apple>();//error
}
}
class Fruit {
}
class Apple extends Fruit {
}
class Fuji extends Apple {
}
注意:使用超类通配符,前后的边界必须保持一致,不然抛异常。
8.泛型问题汇总
8.1 任何基本类型不能作为类型参数
因此不能创建ArrayList<int>之类的东西。解决之道是使用基本类型的包装器类以及JavaSE5的自动包装机制,如果创建一个ArrayList<Integer>,并将其基本类型Int应用于这个容器,那么你就会发现自动包装机制将自动的实现Int到Integer的双向转换--因此,这几乎就像是有一个ArrayList<int>一样
8.2 实现参数化接口
一个类不能实现同一个泛型接口的两种变体,由于擦除的原因,这两个变体会成为相同的接口。下面是产生这种冲突的情况:
interface Payable<T>{}
//class Employee implements Payable<Employee>{}
//public class Hourly extends Employee implements Payable<Hourly> {
//
//}
class Employee implements Payable{}
public class Hourly extends Employee implements Payable {
}Hourly不能编译,因为擦除会将Payable<Employee>和Payable<Hourly>化简为相同的类型Payable,这样,上面的代码就意味着在重复两次的实现相同的接口。十分有趣的是,如果从Payable的两种用法中都移除掉泛型参数(就像编译器在擦除阶段所做的那样)这段代码就可以编译。
8.3 重载
下面的程序是不能同构编译的,即使编译它也是一种合理的尝试:
public class UserList<W,T>{
void f(List<T> v{}
void f(List<W> v{}
}由于擦除的原因,重载方法将产生相同的类型签名。
于此不同的是,当被擦除的参数不能产生唯一的参数列表,必须提供明显有区别的方法名:
public class UserList<W,T>{
void f(List<T> v{}
void g(List<W> v{}
}