1、背景简介
在数据分析工作中,经常需要对原始的数据集进行清洗、整理以及变换。常用的数据整理与变换工作主要包括:特定分析变量的选取、满足条件的数据记录的筛选、按某一个或几个变量排序、对原始变量进行加工处理并生成新的变量、对数据进行汇总以及分组汇总,比如计算各组的平均值等。
其实,上述的数据处理与变换工作在任何一种SQL语言(如Oracle,MySQL)中都非常容易处理,但是R语言作为一门编程语言,如何高效地完成上述类似SQL语言的数据处理功能?本文介绍的R语言dplyr包正是这方面工作的有力武器之一。
dplyr包是 Hadley Wickham (ggplot2包的作者,被称作“一个改变R的人”)的杰作, 并自称 a grammar of data manipulation, 他将原本plyr 包中的ddply()等函数进一步分离强化,专注接受dataframe对象, 大幅提高了速度, 并且提供了更稳健的与其它数据库对象间的接口。
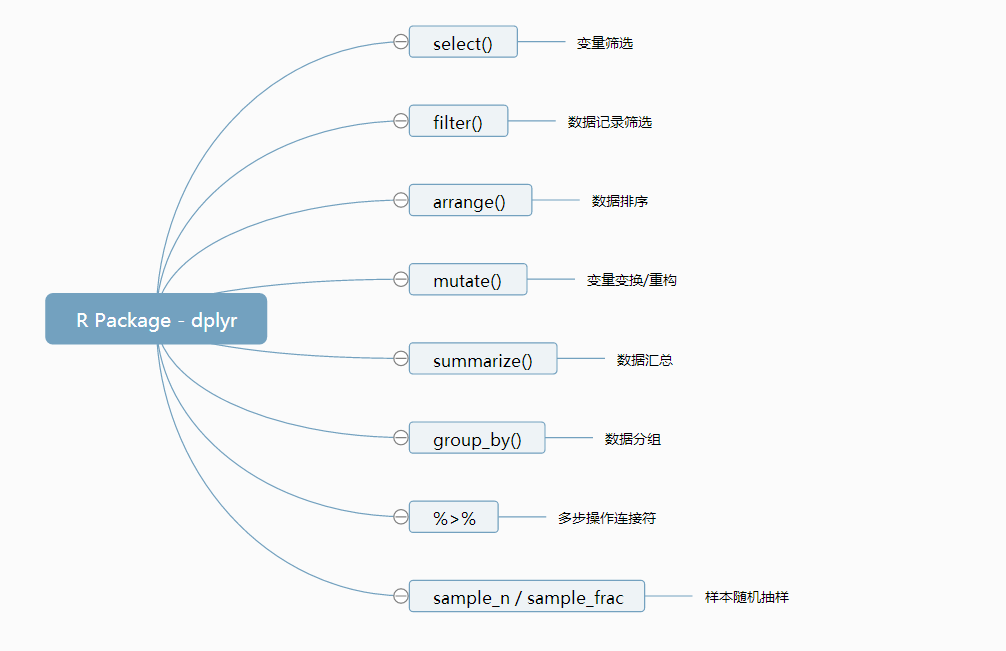
本文试图对该dplyr包的一些基础且常用的功能做简要介绍。主要包括:
- 变量筛选函数 select
- 记录筛选函数 filter
- 排序函数 arrange
- 变形(计算)函数 mutate
- 汇总函数 summarize
- 分组函数 group_by
- 多步操作连接符 %>%
- 随机抽样函数 sample_n,sample_frac
001.png
2、dplyr包使用介绍 2.1 dplyr包的安装加载与示例数据准备
安装dplyr包。
install.packages("dplyr") library(dplyr)
安装hflights包,该软件包中的飞机航班数据将用于本文中dplyr包各个函数的演示。
install.packages("hflights") library(hflights)
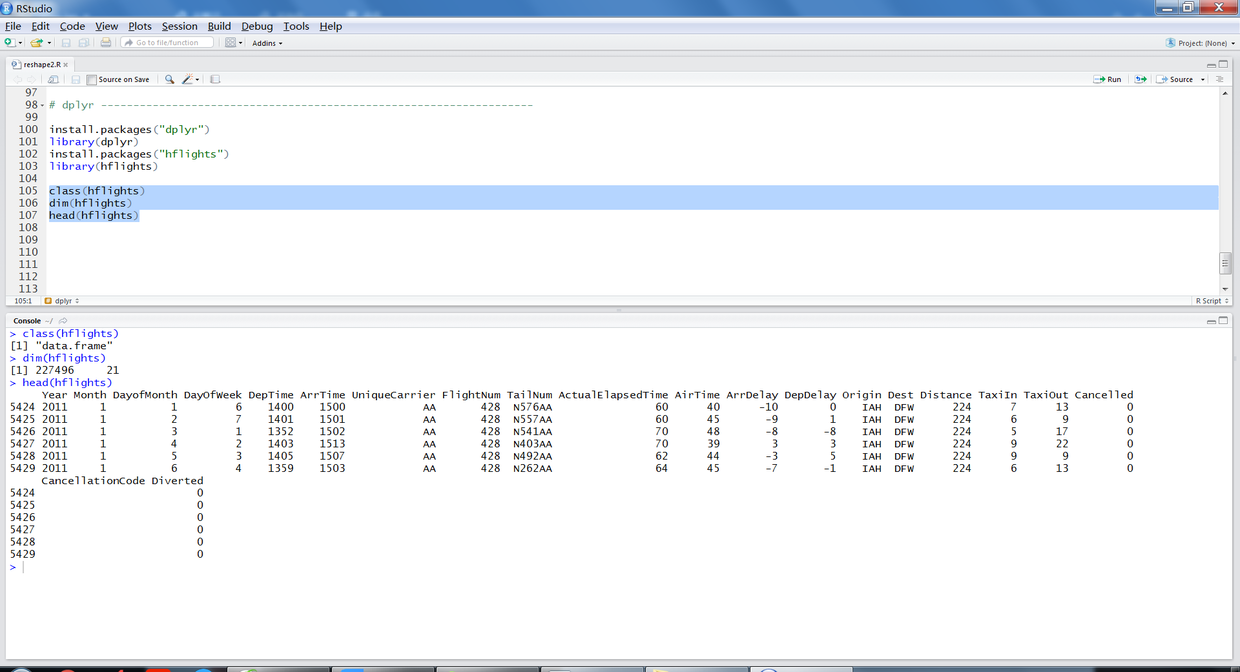
通过以下代码,简单了解示例数据集hflights。
class(hflights);dim(hflights) head(hflights)
输出结果如下:hflights是一个data.frame类型的对象,包含227496条数据记录、21个变量,head函数展示了前6条数据记录。
03.png
在利用dplyr包处理数据之前,需要将数据装载成dplyr包的一个特定对象类型(data frame tbl / tbl_df),也称作 tibble 类型,可以用 tbl_df函数将数据框类型的数据装载成 tibble 类型的数据对象。
packageVersion("dplyr") tbl_hflights<-tbl_df(hflights) class(tbl_hflights) tbl_hflights
输出结果如下:可以看到,将hflights转换成tbl_df类型后,R语言打印数据集tbl_hflights的数据时,仅打印了适合屏幕宽度的数据,屏幕显示不下的剩余两个变量的数据(CancellationCode , Diverted )并没有打印出来,这使得屏幕上打印出来的数据可读性更强,也更美观。此外,还在每一列变量名称的下面显示了变量的类型。

04.png
==p.s. 可以用packageVersion函数查看dplyr包的版本==
2.2 变量筛选select
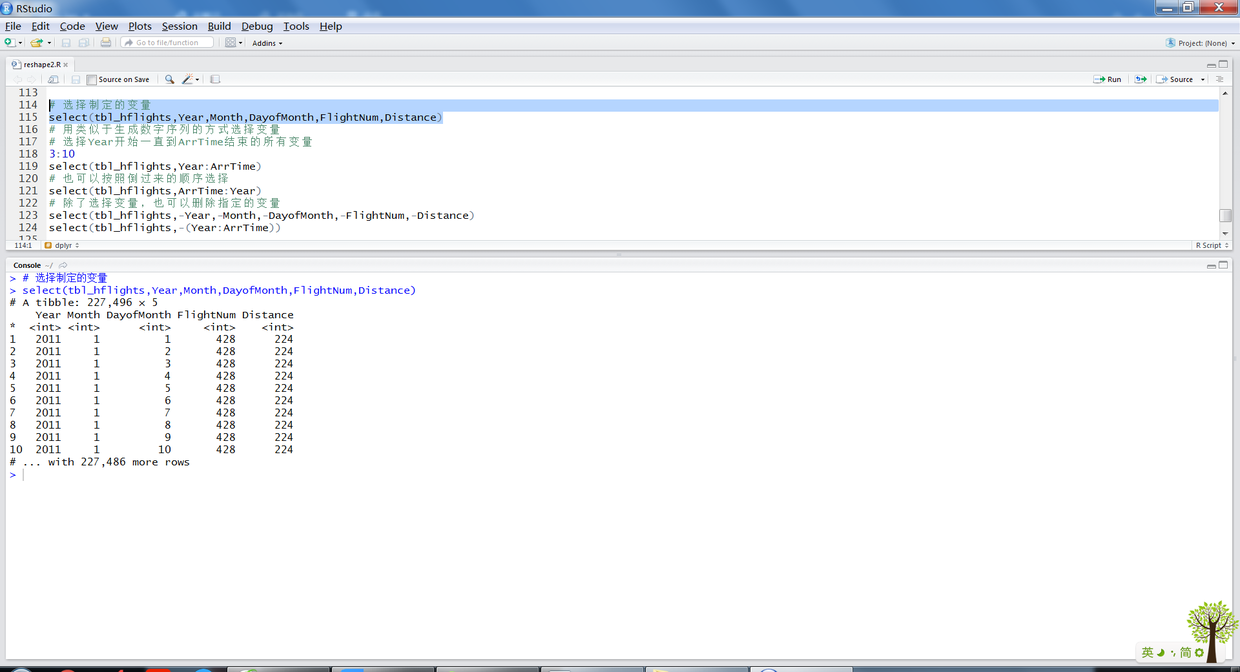
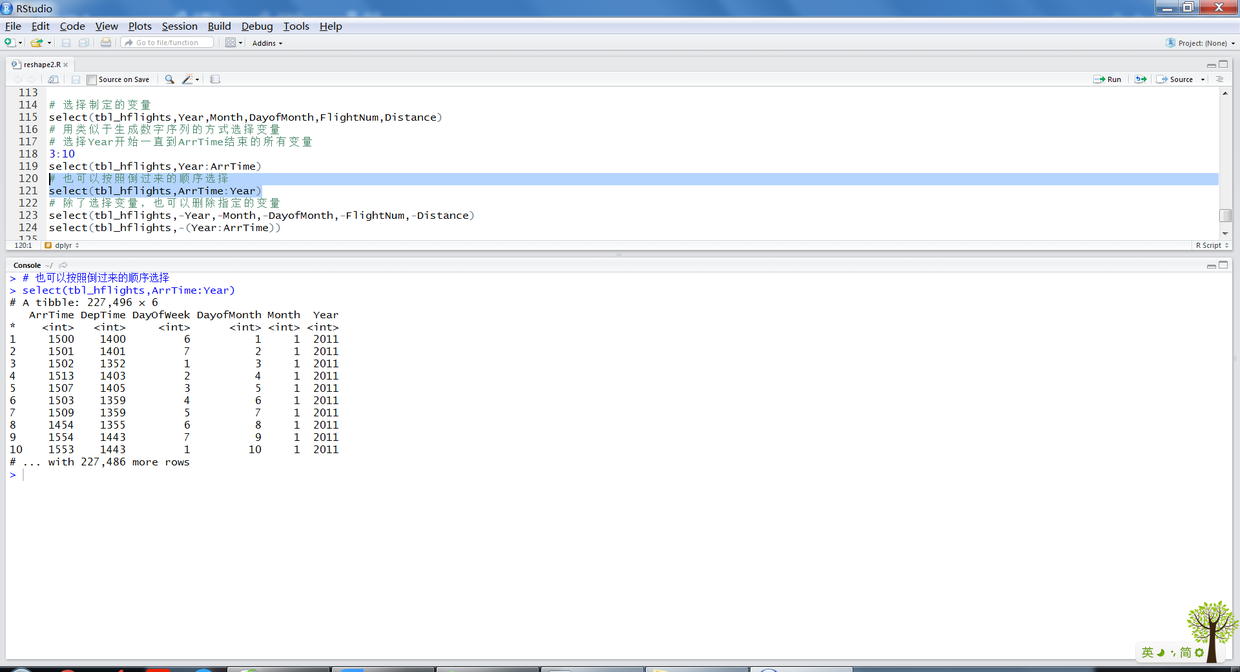
select函数可以通过指定列名选择指定的变量进行分析。
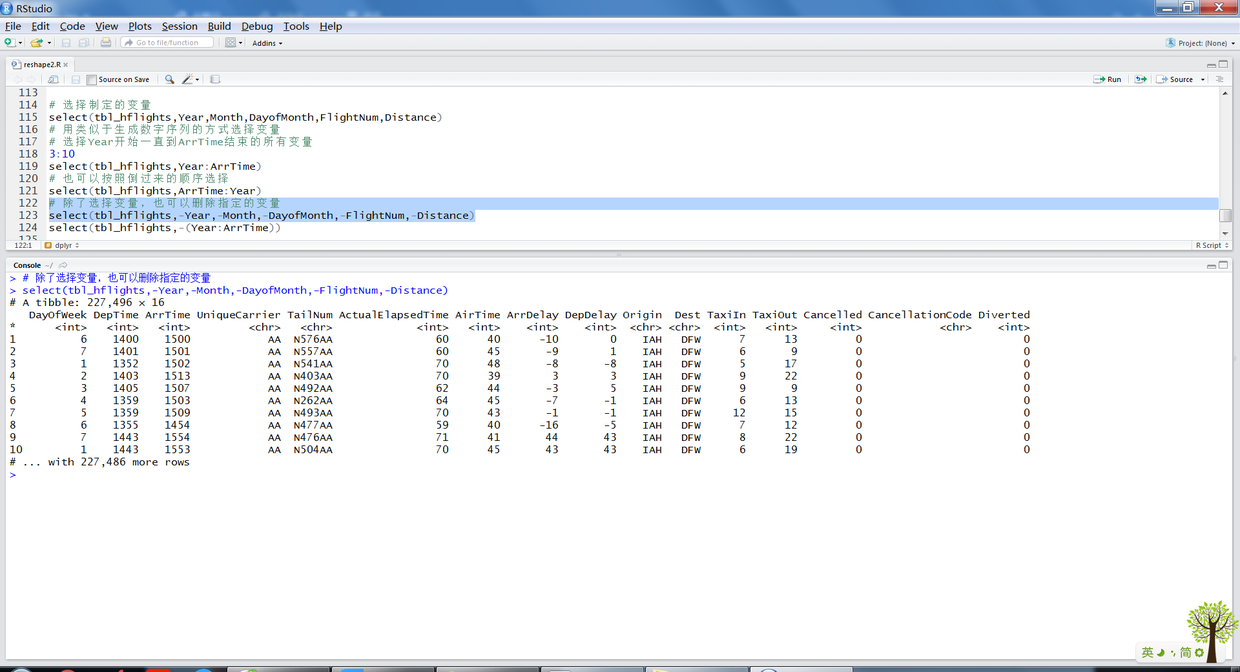
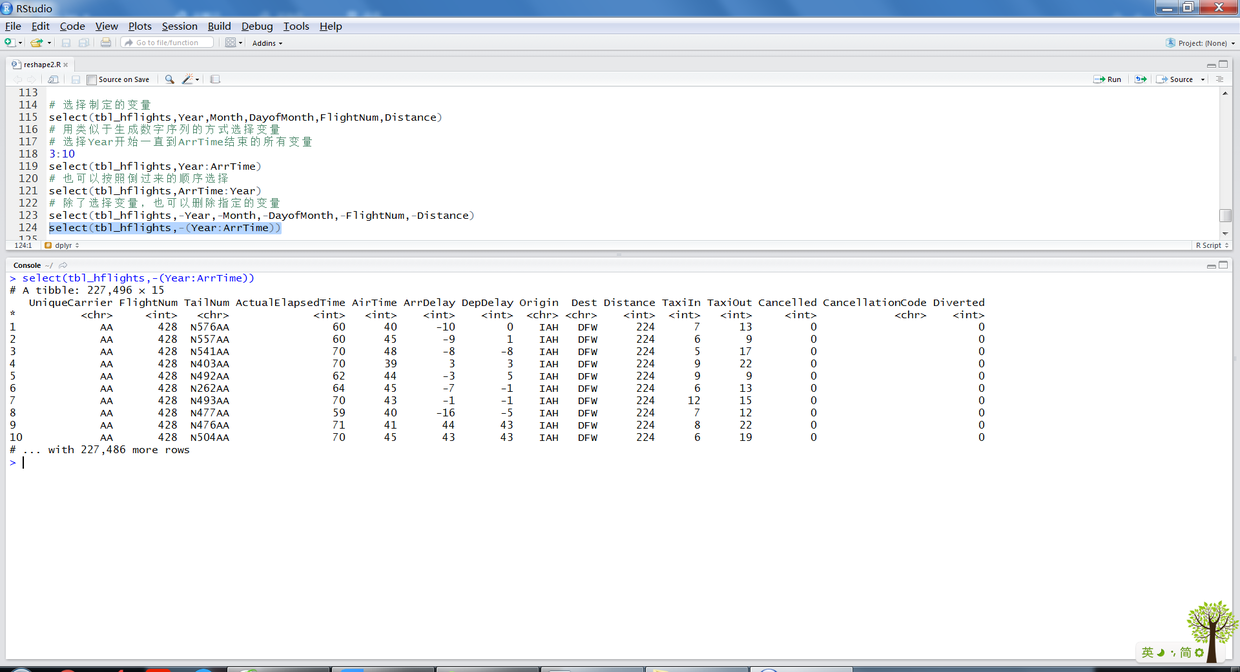
# 选择制定的变量 select(tbl_hflights,Year,Month,DayofMonth,FlightNum,Distance) # 用类似于生成数字序列的方式选择变量 # 选择Year开始一直到ArrTime结束的所有变量 3:10 select(tbl_hflights,Year:ArrTime) # 也可以按照倒过来的顺序选择 select(tbl_hflights,ArrTime:Year) # 除了选择变量,也可以删除指定的变量 select(tbl_hflights,-Year,-Month,-DayofMonth,-FlightNum,-Distance) select(tbl_hflights,-(Year:ArrTime))
05.png

06.png
07.png
08.png
09.png
2.3 数据记录筛选filter
filter函数按照指定的条件筛选符合条件中逻辑判断要求的数据记录,类似于SQL语句中的where语句中的筛选条件。
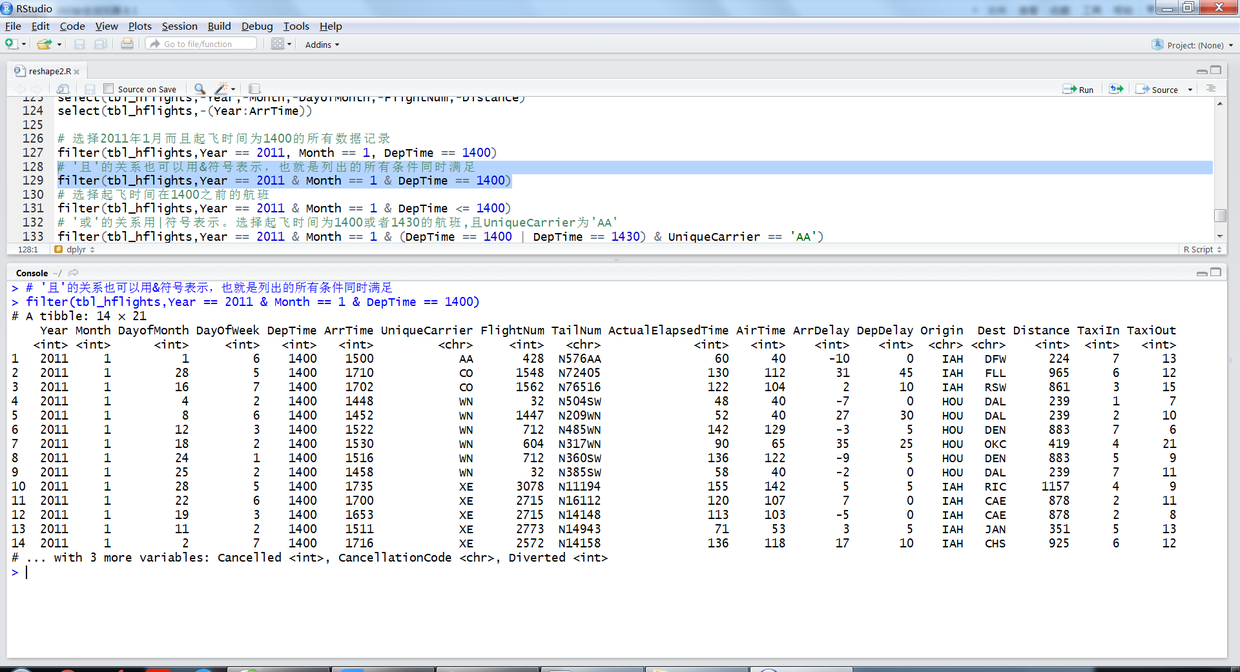
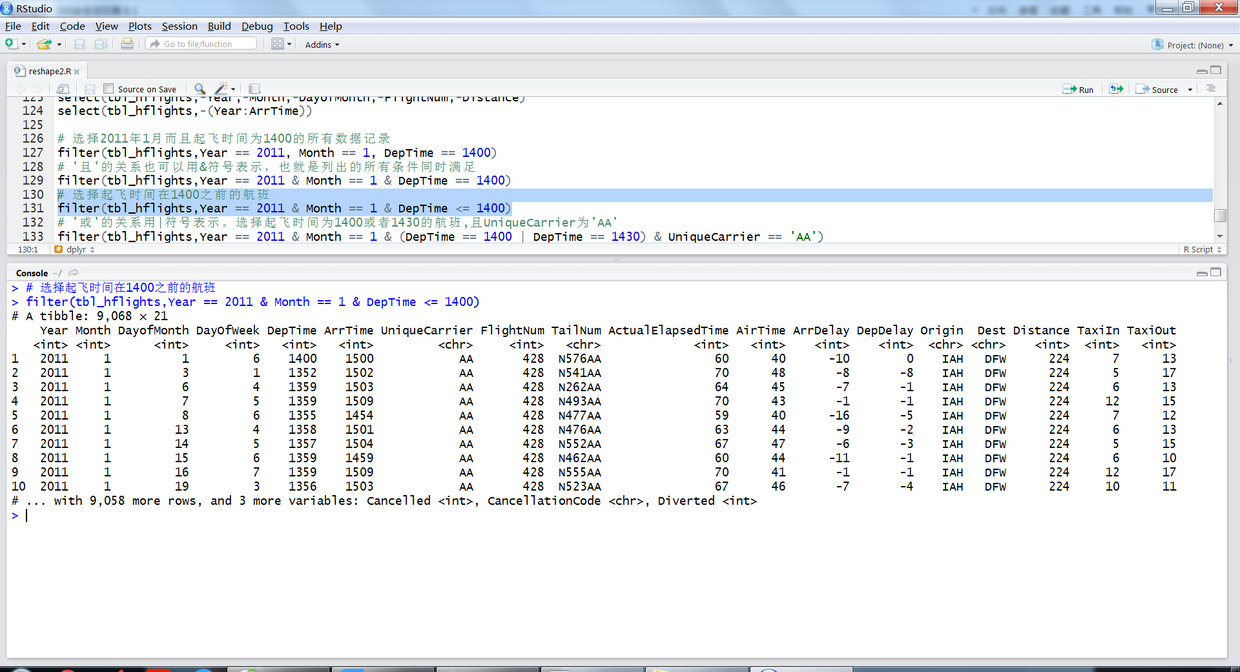
# 选择2011年1月而且起飞时间为1400的所有数据记录 filter(tbl_hflights,Year == 2011, Month == 1, DepTime == 1400) # '且'的关系也可以用&符号表示,也就是列出的所有条件同时满足 filter(tbl_hflights,Year == 2011 & Month == 1 & DepTime == 1400) # 选择起飞时间在1400之前的航班 filter(tbl_hflights,Year == 2011 & Month == 1 & DepTime <= 1400) # '或'的关系用|符号表示。选择起飞时间为1400或者1430的航班,且UniqueCarrier为'AA' filter(tbl_hflights,Year == 2011 & Month == 1 & (DepTime == 1400 | DepTime == 1430) & UniqueCarrier == 'AA')
上述R语句输出结果如下:

10.png
11.png
12.png

13.png
2.4 数据排序arrange
arrange函数按给定的列名进行排序,默认为升序排列,也可以对列名加desc()进行降序排序。
tbl_hflights1<-select(filter(tbl_hflights,Year == 2011 & Month == 1 & DepTime == 1400),Year:ArrTime,AirTime) # 将数据按照ArrTime升序排序 arrange(tbl_hflights1,ArrTime) # 将数据先按照AirTime降序,再按照ArrTime升序排列 arrange(tbl_hflights1,desc(AirTime),ArrTime)
上述R语句输出结果如下:
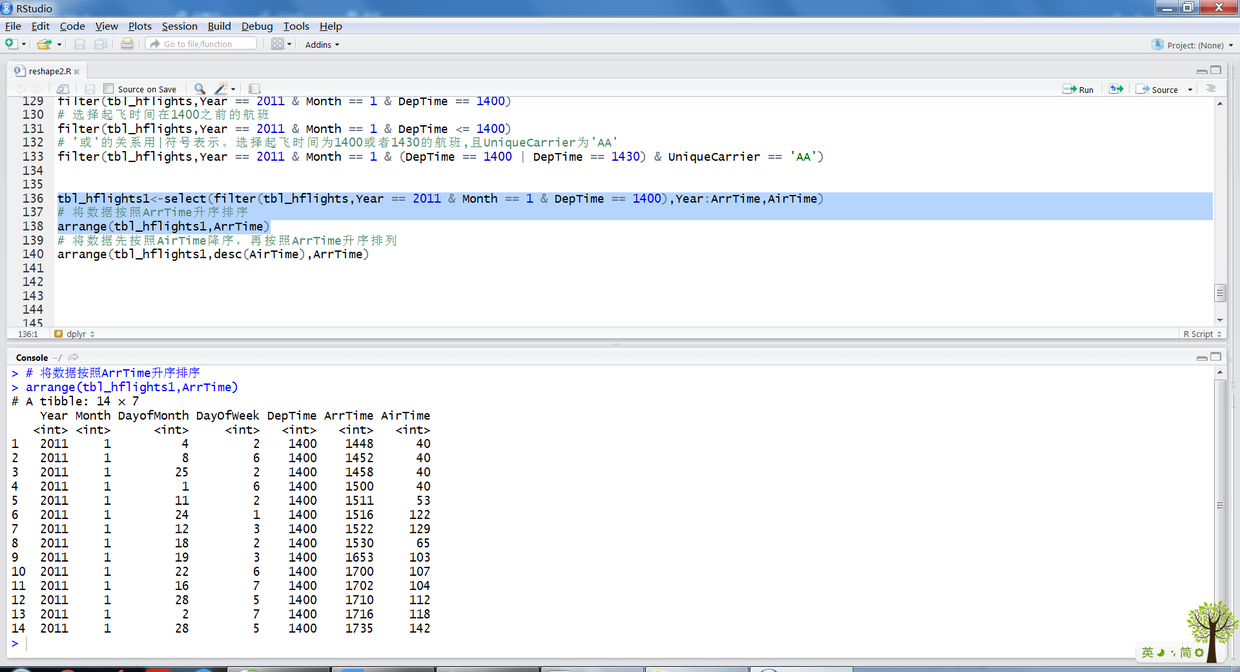
14.png

15.png
2.5 变量变换/重构mutate
mutate函数可以基于原始变量重新计算得到新的变量,在做数据分析预处理的时候经常会用到该功能。
# 由ArrTime-DepTime得到航班的飞行所用时长,并存储在DurTime变量中 # 飞行所用时长(单位:分钟)的计算方式为:小时数*60+分钟数 # 同时将飞行的分钟数,换算成秒。 # 优势在于可以在同一语句中对刚增加的列进行操作。 tbl_hflights2<-mutate(tbl_hflights1, DurTime = (as.numeric(substr(ArrTime,1,2)) - as.numeric(substr(DepTime,1,2)))*60 + as.numeric(substr(ArrTime,3,4)) , Dur_Time1 = DurTime * 60) tbl_hflights2
上述R语句输出结果如下:
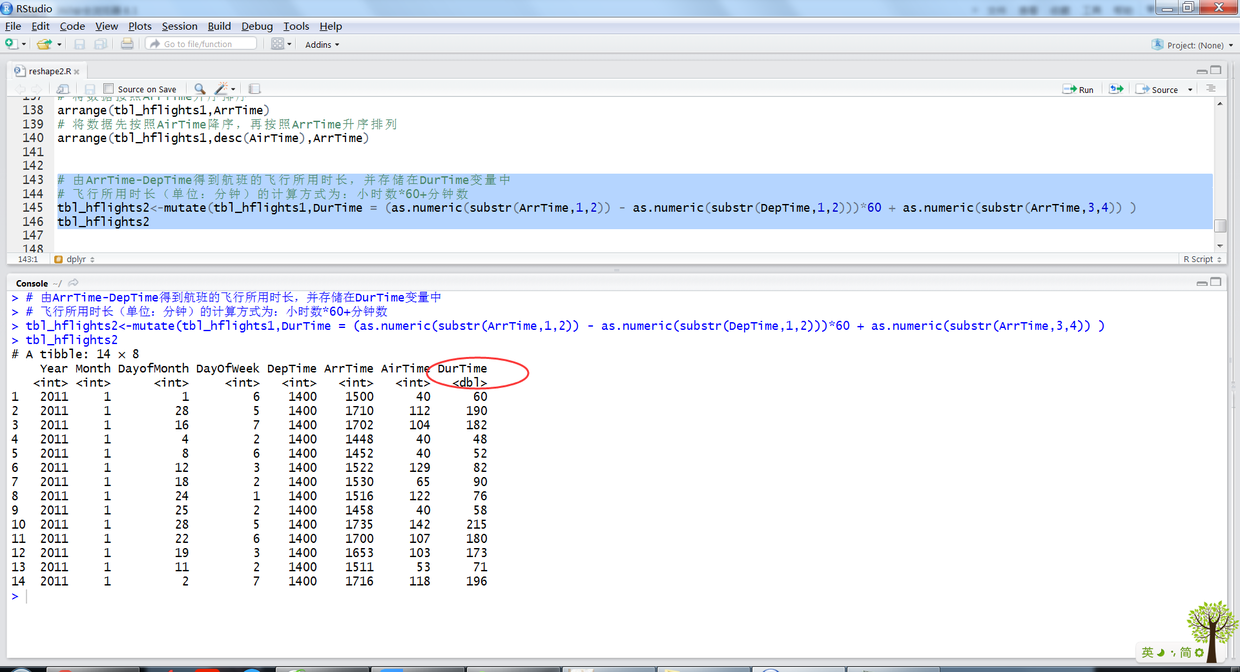
16.png
2.6 数据汇总summarize
summarize函数实现对数据的汇总,比如求和、计算平均值等。
# 计算航班平均飞行时长 summarize(tbl_hflights2,avg_dur = mean(DurTime),sum_air = sum(AirTime))
上述R语句输出结果如下:
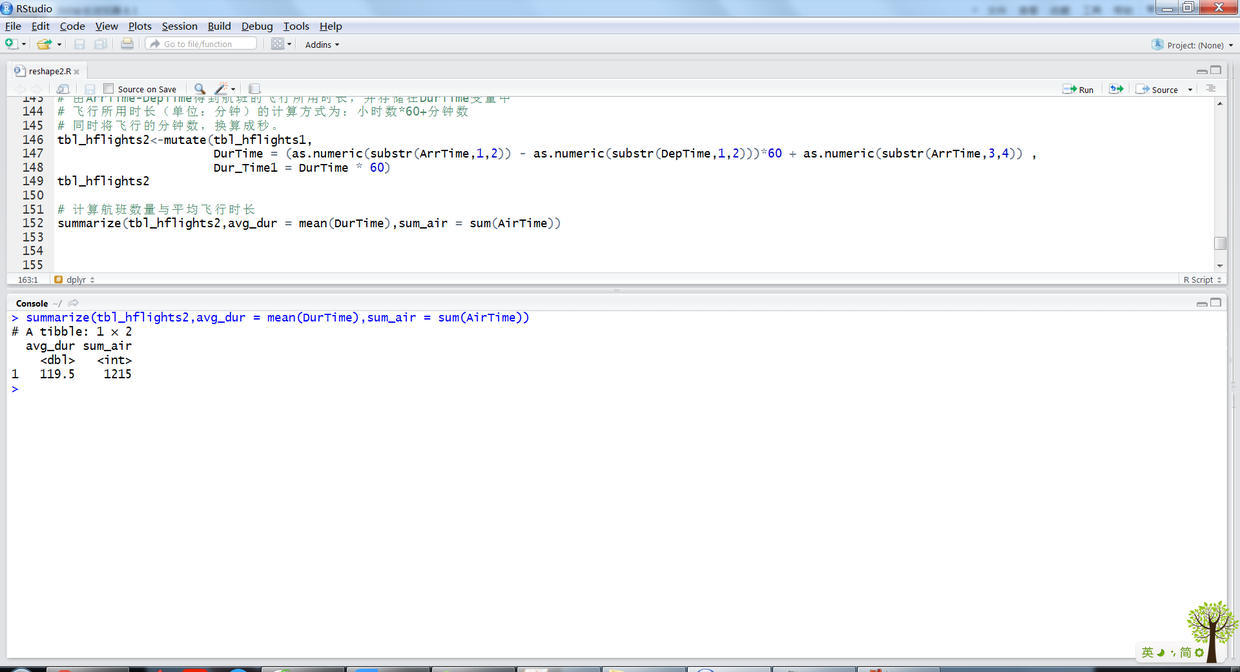
18.png
2.7 数据分组group_by
group_by函数实现对数据进行分组,结合summarize函数,可以对分组数据进行汇总统计。
# 按照航空公司分组进行汇总 summarise(group_by(tbl_hflights, UniqueCarrier), m = mean(AirTime,na.rm = TRUE), sd = sd(AirTime,na.rm = TRUE), cnt = n(), me = median(AirTime,na.rm = TRUE))
上述R语句输出结果如下:
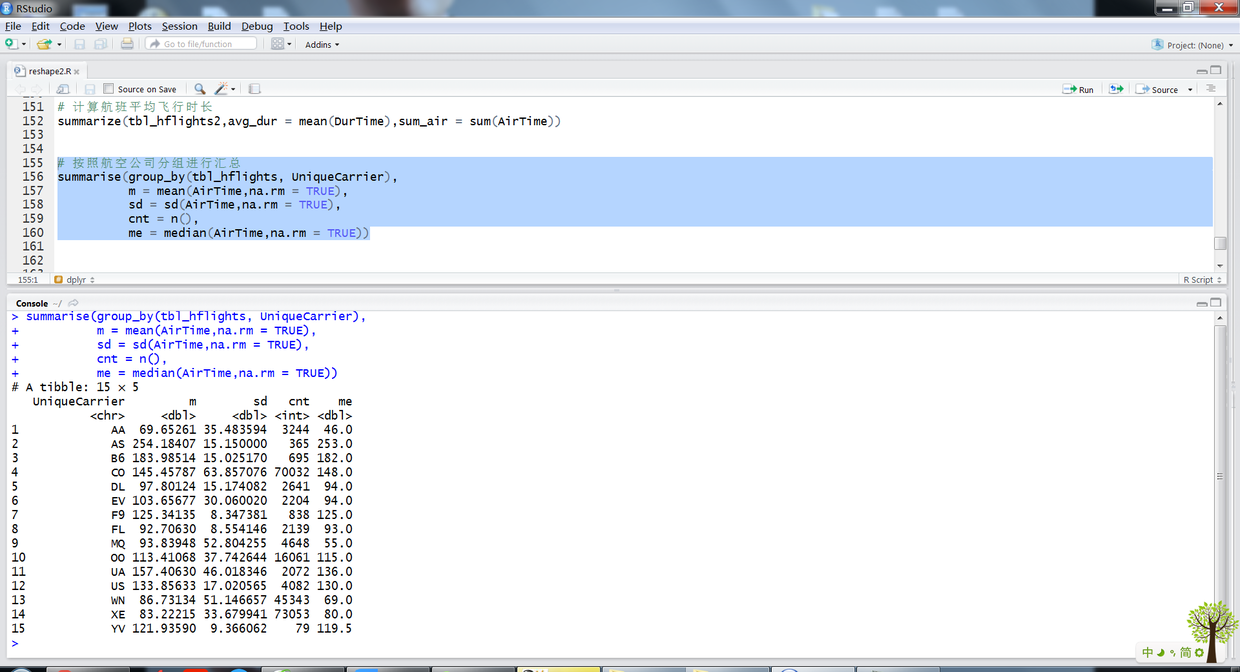
19.png
2.8 多步操作连接符%>%
dplyr包里还新引进了一个操作符,%>%, 使用时把数据集名作为开头, 然后依次对此数据进行多步操作。这种运算符的编写方式使得编程者可以按数据处理时的思路写代码, 一步一步操作不断叠加,在程序上就可以非常清晰的体现数据处理的步骤与背后的逻辑。
# 对数据进行分布处理:分组-汇总-排序-打印 tbl_hflights %>% group_by(UniqueCarrier) %>% summarize(m = mean(AirTime,na.rm = TRUE), sd = sd(AirTime,na.rm = TRUE)) %>% arrange(desc(m),sd) %>% head(10)
上述R语句输出结果如下:
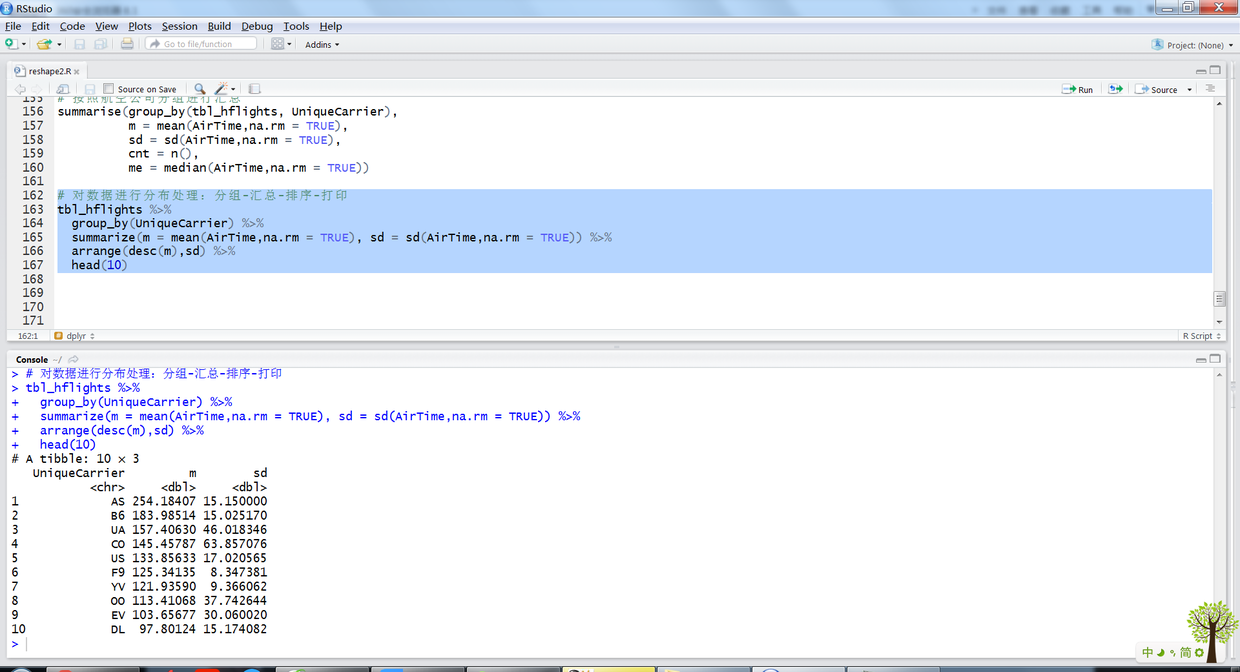
20.png
2.9 挑选随机样本sample_n, sample_frac
sample_n随机选出指定个数(样本容量)的样本数;sample_frac随机选出指定百分比(占整个数据集总体百分比)的样本数。
# 随机抽取10个样本 sample_n(tbl_hflights,10) # 随机抽取10%的样本 tbl_hflights %>% sample_frac(0.1) %>% select(Year:UniqueCarrier) %>% group_by(UniqueCarrier) %>% summarize(m = mean(ArrTime,na.rm = TRUE), cnt = n()) %>% arrange(desc(m))
上述R语句输出结果如下:

21.png
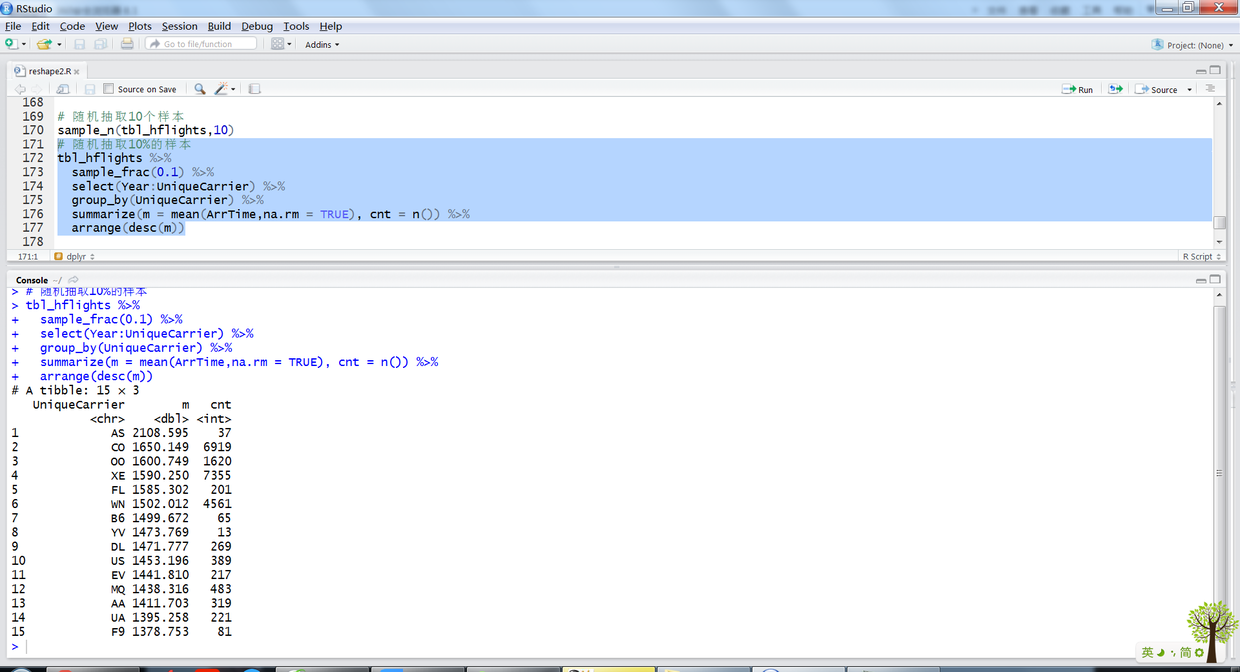
22.png
3、参考文献与其他学习资料 3.1 dplyr包中自带的参考资料查看
可以通过如下名称查看dplyr包中自带的参考资料。
# 查看自带的参考资料 vignette(package = "dplyr") vignette("introduction", package = "dplyr")
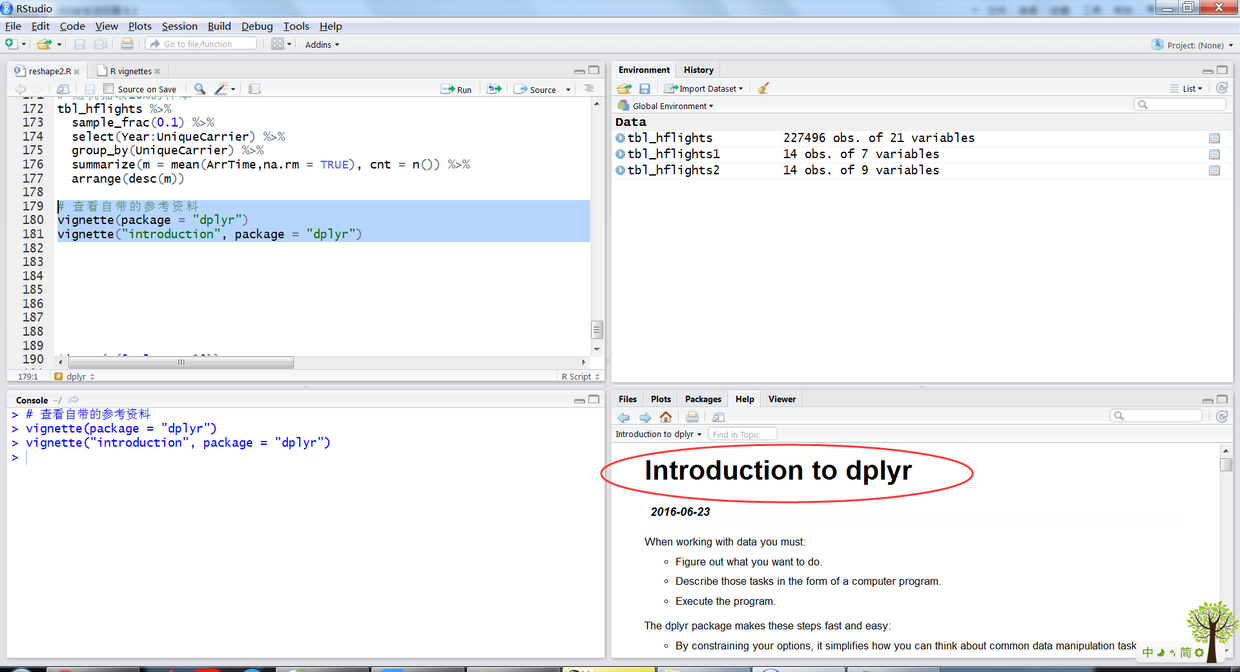
23.png
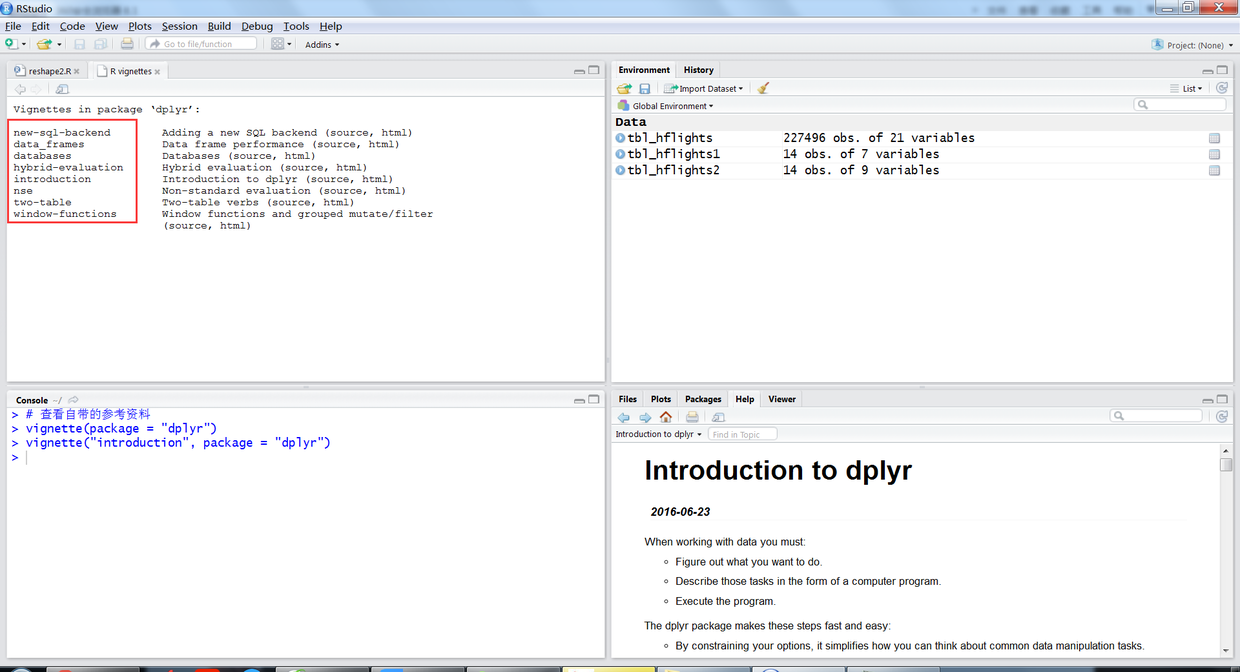
24.png
3.2 本文写作用到的参考链接
R语言扩展包dplyr笔记R语言扩展包dplyr——数据清洗和整理
3.3 RStudio官网的cheatsheet
data-wrangling-cheatsheet

26.png

关注我们
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
QQ:3025393450
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;学术研究。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询服务

分享最新的大数据资讯,每天学习一点数据分析,让我们一起做有态度的数据人
微信客服号:lico_9e
QQ交流群:186388004

欢迎关注微信公众号,了解更多数据干货资讯!
欢迎加入我们的大数据学习必备利器课程

http://study.163.com/course/courseMain.htm?courseId=1003776041&share=2&shareId=1023497288
