目录
Btree索引和Hash索引
MySQL支持的索引类型
- mysql的索引是在存储引擎层实现的。
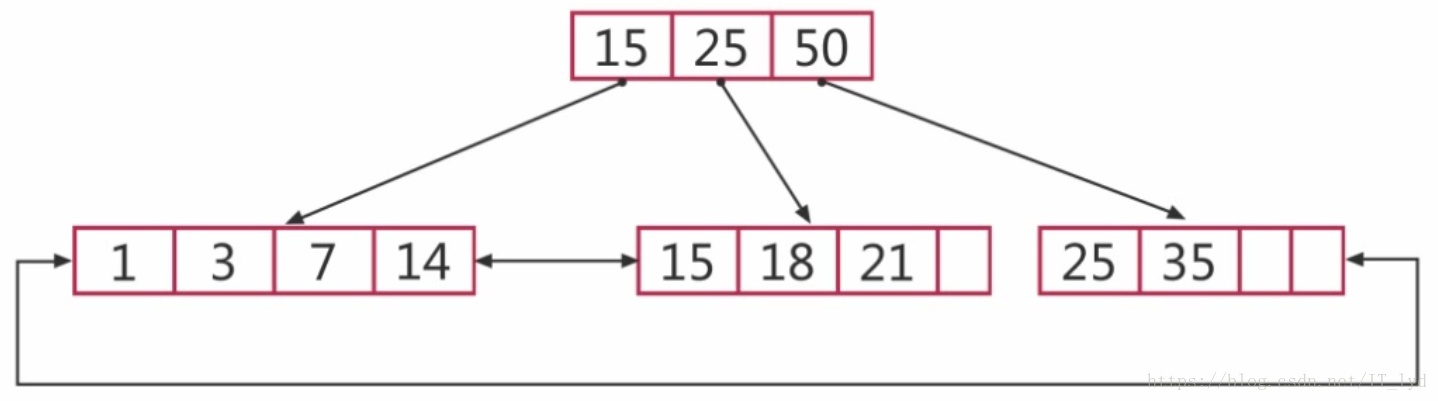
1.B-tree索引
- 特点:
- Btree索引以B+树的结构存储数据
- Btree索引能够加快数据的查询速度
- Btree索引更适合进行范围查找【顺序存储】
- Btree索引以B+树的结构存储数据
- 适用场景:
- 全值匹配的查询 order_sn=’232874837434’;
- 匹配最左前缀的查询 (在order_sn列上未建立索引,而是建立的联合索引(order_sn,order_date),如果查询order_sn的话这个联合索引是会被用到的,如果查询order_date的话,这个联合索引是无法被用到的)
- 匹配列前缀查询 如:order_sn like ‘4353%’;
- 匹配范围值的查询 order_sn>’5389384934’ order_sn<’5389384987’
- 精确匹配左前列并范围匹配另外一列 order_sn like ‘4353%’ and order_date > ‘3123’;
- 只访问索引的查询【覆盖索引】(查询只访问索引,无需访问数据行)
- 也可用于order by语句中
- 使用限制:
- 如果不是按照索引最左列开始查找,则无法使用索引(联合索引(order_sn,order_date),如果查询order_sn的话这个联合索引是会被用到的,如果查询order_date的话,这个联合索引是无法被用到的)
- 使用索引时不能跳过索引中的列(联合索引(order_date,order_name,order_tel),如果查询条件只包含了下单日期和下单人电话,就只能使用order_date这一列来进行过滤,而无法使用到下单人电话来过滤)
- Not in和<>操作无法使用索引
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引。
- 注意:
- 叶子节点比较特别,它指向的是数据,而不是其它的叶子节点。
- Innodb中叶子节点指向的是主键,Myisam中叶子节点指向数据的物理地址。
2.Hash索引
存储引擎memory默认使用hash索引,另外Innodb也支持hash索引(不是由我们建立,是存储引擎根据btree索引的使用情况自己建立的,称为自适应Hash索引)
特点:
- 速度快
- Hash索引是基于Hash表实现的,只有查询条件精确匹配Hash索引中的所有列时,才能够使用到Hash索引。【等值查询】
- 对于Hash索引中的所有列,存储引擎都会为每一行计算一个Hash码,Hash索引中存储的就是Hash码。
限制:
- 必须进行二次查找(Hash索引包括的只是键值、hash码、对应行的指针,索引中并没有保存字段的值,所以使用hash索引时必须先通过hash索引找到对应的行,再对行的记录进行读取,所以需要进行两次查找。不过基本都是缓存在内存中的,对于内存中的行,数据访问非常快。)
- Hash索引不支持部分索引查找也不支持范围查找。
- 无法用于排序(按照Hash码进行存取,不是Btree中键值那样存取的)
- hash码的计算可能存在Hash冲突,也就是不同的索引列计算出的hash码是一样的。(比如性别就容易冲突,而身份证号(唯一)不容易冲突)
为什么要使用索引
- 索引大大减少了存储引擎需要扫描的数据量(索引文件大小通常远小于数据文件的大小。Innodb发生一次IO,最小的单位是页,所以一页内如果可存取的数据越多,读取效率就越快。默认Innodb是一页16K,由于索引的大小远比一行的大小小的多,所以一页可存储更多的索引数据,因此通过索引进行查找的话,页数就会越少,这样也就减少了存储引擎所要扫描的数据的数量,加快了数据查找的速度)
- 索引可以帮助我们进行排序以避免使用临时表
- 索引可以把随机I/O变为顺序I/O
- 索引是不是越多越好?
- 索引会增加写操作的成本
- 太多的索引会增加查询优化器的选择时间
安装演示数据库
1.下载数据库
[root@lyd ~]# wget http://downloads.mysql.com/docs/sakila-db.tar.gz 2.安装数据库
[root@lyd~]# tar zxvf sakila-db.tar.gz
[root@lyd ~]# ll -h sakila-db/
total 3.4M
-rw-r--r--. 1 500 500 3.3M Jul 21 2017 sakila-data.sql --插入语句
-rw-r--r--. 1 500 500 49K Jul 21 2017 sakila.mwb --数据模型
-rw-r--r--. 1 500 500 23K Jul 21 2017 sakila-schema.sql --创建语句mysql> source ./sakila-db/sakila-schema.sql
mysql> source ./sakila-db/sakila-data.sql 3.检查安装的数据库
mysql> use sakila
Database changed
mysql> show tables;
+----------------------------+
| Tables_in_sakila |
+----------------------------+
| actor |
| actor_info |
| address |
| category |
| city |
| country |
| customer |
| customer_list |
| film |
| film_actor |
| film_category |
| film_list |
| film_text |
| inventory |
| language |
| nicer_but_slower_film_list |
| payment |
| rental |
| sales_by_film_category |
| sales_by_store |
| staff |
| staff_list |
| store |
+----------------------------+
23 rows in set (0.00 sec) 
索引优化策略
- 1.索引列上不能使用表达式或函数
- 2.前缀索引和索引列的选择性
索引键值的大小有限制,对于Innodb的键不能超过767个字节,而myisam的键不能超过1000字节。对于整型、浮点型等足够,但是对于字符串来说可能不足。所以mysql支持对字符串的前缀建立索引,这样可以大大节约索引的空间,从而提高查询效率。
索引的选择性是不重复的索引值和表的记录数的比值。选择性越高,使用索引查找的效率就越快。

CREATE INDEX index_name ON table(col_name(n))
或ALTER TABLE table_name ADD KEY(column_name(prefix_length));
——————————————————————————————————————————————
CREATE INDEX idx_cityname ON city(cityname(7));
或ALTER TABLE city ADD KEY(cityname(7));注意:这里需要制定索引列的长度,Innodb不超过767字节;如果是utf8字符集的话大概是255和字符。
- 3.联合索引
并不是每一列都建立一个索引就查询效率高,在mysql5.0之前每个where语句只能用到一列的索引;在mysql5.0之后虽然有了索引合并的概念,在一个查询中可以使用多个列上的独立索引进行合并,但是需要更多的内存和磁盘I/O。
(1)如何选择索引列的顺序?
- 经常会被使用到的列优先
- 选择性高的列优先(选择性高,意味着能过滤掉更多的数据)
- 宽度小的列优先(宽度越小,列中所能存储的索引就越多,I/O就会越少,加快查找的效率)
- 4.覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。不是所有的类型的索引都可以成为覆盖索引,覆盖索引必须要存储索引列的值,而哈希索引,空间索引和全文索引等都不存储引列的值,所以MySQL只能使用B-Tree索引做覆盖索引。
优点:
- 可以优化缓存,减少磁盘I/O操作
- 可以减少随机I/O,随机I/O操作变为顺序I/O操作(btree索引按键值存储)
- 可以避免对Innodb主键索引的二次查询
- 可以避免myisam表进行系统调用
无法使用覆盖索引的场景:
- 存储引擎不支持覆盖索引(只有在索引叶子节点中包括了键值,才可以)
- 查询中使用了太多的列
- 使用了双%号的like查询(mysql底层的存储引擎API限制的,对于这样的查询,mysql只能提取数据行的值,然后在内存中进行过滤,所以不能使用索引,更别说覆盖索引了)
使用索引来优化查询
1.使用索引扫描来优化排序
- 通过排序操作
- 按照索引顺序扫描数据
- 索引的列顺序和Order By子句的顺序完全一致。
- 索引列中所有列的方向(升序,降序)和Order By子句完全一致。
- Order By中的字段全部在关联表中的第一张表中。
- Innodb和myisam搜索引擎的比较
- 二级索引——>两者的查询规则一致。
- 主键索引——>Innodb是索引排序,myisam是文件排序。
2.使用Btree索引模拟Hash索引优化查询
数据准备
alter table film add title_md5 varchar(32);
update film set title_md5=md5(title);
create index idx_md5 on film(title_md5);
数据查询
explain select * from film where title_md5=md5('EGG IGBY') and title='EGG IGBY';(通过Hash索引将数据放入内存,再通过title列去内存中进行过滤,这样是为了避免Hash冲突)
- 局限性
- 只能处理键值的全值匹配查找。
- 所使用的Hash函数决定着索引建的大小。(使用Hash函数生成的Hash值比较大的话,索引就会大。既不能生成太大的Hash值,也要尽量避免Hash冲突的出现)
3.利用索引优化锁
- 优点:
- 索引可以减少锁定的行数。
- 索引可以加快处理速度,同时也加快了锁的释放。
- 测试
- 以actor表为例,先删掉last_name的索引
drop index idx_actor_last_name on actor; - session1:①开启事务
begin;②查询加排他锁select * from actor where last_name='WOOD' for update; - session2:①开启事务
begin;②查询加排他锁select * from actor where last_name='Willis' for update;③无结果,被session1阻塞。 - 为last_name加上索引
create index idx_lastname on actor(last_name);session2不会阻塞。
- 以actor表为例,先删掉last_name的索引
4.索引的维护和优化
Mysql允许在相同的列上建立多个索引,但是mysql需要单独的维护这些索引,并且在优化查询的时候还要对这些索引进行选择,这无疑会影响数据库的性能。
删除重复和冗余的索引
重复索引
冗余索引(有时候冗余索引也是必要的)
index(a),index(a,b)联合索引
primary key(id),index(a,id)联合索引
如何判断索引是冗余的?工具pt-duplicate-key-checker h=127.0.0.1
查找未被使用过的索引
SELECT object_schema,object_name,index_name,b.TABLE_ROWS
FROM performance_schema.aTABLES
JOIN information_schema.bOBJECT_SCHEMA
ON a.=b.TABLE_SCHEMA
AND a.=b.TABLE_NAME
WHERE index_name IS NOT NULL
AND count_star=0
ORDER BY object_schema, object_name;
更新索引统计信息及减少索引碎片
- 重新生成表的统计信息:
analyze table table_name(对于myisam而言,会将统计信息存储在磁盘中,运行此命令需要进行全索引的扫描,重新计算统计信息,此过程需要对表进行锁定;而Innodb不会在磁盘存储索引统计信息,而是通过随机的索引访问的方式来进行评估,其存储在内存中。索引Innodb会效率高,但是统计信息不是十分准确。而且在进行Btree更新操作时可能会产生大量的碎片,这样会降低查询效率,碎片化的索引可能会以很差的或者无序的方式来存储在磁盘上。表也可能产生碎片,所以要适当的维护。) - 使用语句维护碎片
optimize table table_name(使用不当会导致锁表)
- 重新生成表的统计信息:

