目录
查询优化,索引优化,库表结构优化需要齐头并进。
获取有性能问题的SQL
获取有性能问题SQL的三种方法:
- 通过用户反馈获取存在性能问题的SQL
- 通过慢查日志获取存在性能问题的SQL
- 实时获取存在性能问题的SQL
慢查询日志
1.慢查询日志介绍
- 慢查询日志是一种性能开销比较低的获取具有性能问题SQL的方案,其主要开销来源于磁盘IO和存储日志所需要的磁盘空间。(对于磁盘IO来说,写日志时顺序存储,可以忽略不计;存储日志需要大量的磁盘空间,所以需要控制日志)
- mysql提供了一些参数
- slow_query_log 启动/停止记录慢查日志【通过脚本来定时的开关】
- slow_query_log_file 指定慢查日志的存储路径及文件【默认情况下保存在MYSQL的数据目录中,建议进行修改,日志存储和数据存储分开存储,能存储在不同的磁盘分区上就更好了】
- long_query_time 指定记录慢查日志SQL执行时间的阈值【目前版本可以精确到微秒,但是这个参数的单位是秒。和二进制日志不同,慢查日志会记录所有符合条件的SQL,包括查询语句、数据修改语句,还包括已经回滚的SQL。如果用这个参数进行SQL审核的话一定要注意这个参数默认为10秒。这个值太大,一般修改为0.001秒也就是1毫秒可能比较合适】
- log_queries_not_using_indexs 是否记录未使用索引的SQL【就算执行的很快,只要未使用索引,也是会记录的。趁数据量小,及早发现并进行索引优化】
2.慢查询日志实践
mysql> show variables like 'slow_query_log';mysql> set global slow_query_log=on;
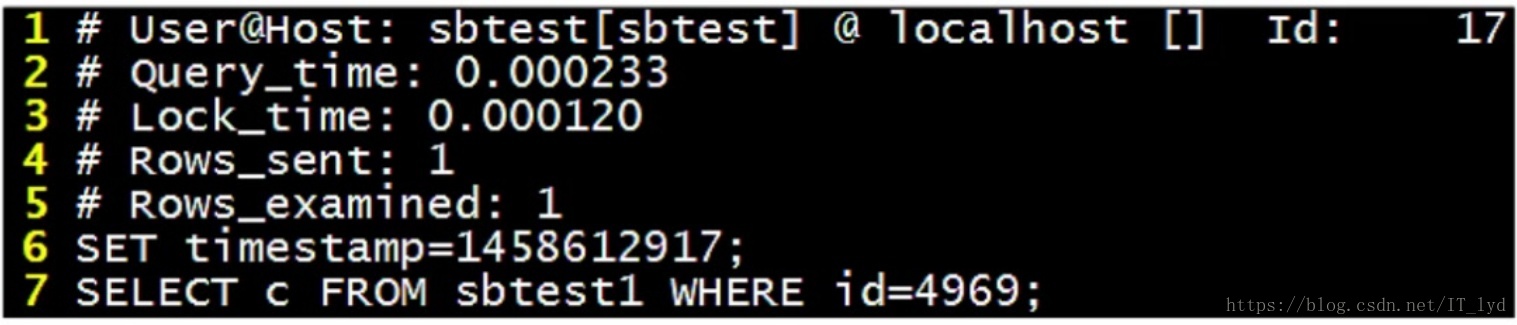
使用慢查询日志获取有性能问题的SQL
- 慢查日志中记录的内容
- 1.用户信息和线程ID号
- 2.执行查询的时间(精确到毫秒。233毫秒)
- 3.锁的时间
- 4.所返回数据的行数
- 5.所扫描数据的行数
- 6.执行sql的时间
- 7.所使用的SQL
3.常用的慢查日志分析工具
mysqldumpslow【mysql官方工具】
- 汇总除查询条件外其它完全相同的SQL,并将分析结果按照参数中所指定的顺序输出。
mysqldumpslow -s r -t 10 slow-mysql.log
-t top 指定取前几条作为结束输出
pt-query-digest【常用】
pt-query-digest --explain h=127.0.0.1,u=root,p=password show-mysql.log【explain指是否在结果中包括执行计划,h指在哪个服务器上生成执行计划,通常是在本机,主从的话在从服务器上生成。】

实时获取性能问题SQL
- information_schema数据库—–>PROCESSLIST表
- 周期性执行以下脚本可以实时监控:(60可以自定义)
SELECT id,`user`,`host`,DB,command,`time`,state,info
FROM information_schema.`PROCESSLIST`
WHERE `time`>=60;SQL的解析预处理及生成执行计划
1.MYSQL服务器处理查询请求的整个过程:
- ①客户端发送SQL请求给服务器(影响很小)
- ②服务器检查是否可以在查询缓存中命中该SQL(命中则不进行下面步骤)
- ③服务器端进行SQL解析,预处理,再由优化器生成对应的执行计划
- ④根据执行计划,调用存储引擎API来查询数据
- ⑤将结果返回给客户端
2.查询缓存对SQL性能的影响
- 优先检查整个查询是否命中查询缓存中的数据。【通过一个对大小写敏感的哈希查找实现的】
- hash查找只能进行全值匹配。(即使一个字节不同也不会匹配)
- 如果命中缓存的话,返回结果之前会检查用户权限,然后直接将结果返回客户端。
- 每次在缓存中检查SQL是否命中时,都要对缓存加锁,所以对于一个读写频繁的系统使用查询缓存很可能会降低查询处理的效率。所以建议不要使用查询缓存。
- 查询缓存对系统影响的一些参数
query_cache_type设置查询缓存是否可用【ON/OFF/DEMAND】(DEMAND表示只有在查询语句中使用SQL_CACHE和SQL_NO_CACHE来控制是否需要缓存)query_cache_size设置查询缓存的内存大小【单位字节必须是1024的整数倍】query_cache_limit设置查询缓存可用存储的最大值(如果知道某查询会超过最大值,最好在SQL加上SQL_NO_CACHE可以提高效率)query_cache_wlock_invalidate设置数据表被锁后是否返回缓存中的数据(默认关闭)query_cache_min_res_unit设置查询缓存分配的内存块最小单位
- 读写频繁的系统建议关闭查询缓存(将query_cache_type设置为OFF,将query_cache_size设置为0)
3.将一个SQL转换成一个执行计划
- MYSQL依照这个执行计划和存储引擎进行交互,这个阶段包括了多个子过程:
解析SQL,预处理,优化SQL执行计划
- 语法解析阶段是通过关键字对MYSQL语句进行解析,并生成一棵对应的“解析树”。MYSQL解析器将使用MYSQL语法规则验证和解析查询【包括语法是否使用了正确的关键字、关键字的顺序是否正确等】
- 预处理阶段是根据MYSQL规则进一步检查解析树是否合法【检查查询中所涉及的表和数据列是否存在及名字或别名是否存在歧义等等】。
- 如果语法检查全都通过了,查询优化器就可以生成查询计划了。(一条查询可以有很多种执行方式,优化器会通过统计信息找到成本最低的执行计划)
4.会造成MYSQL生成错误的执行计划的原因
- 统计信息不准确(MYSQL依赖于存储引擎锁提供的统计信息来评估成本,有的存储引擎提供的信息时准确的,有的是存在偏差的。如Innodb由于架构的原因并不能维护一个表的行数的精确统计信息,取而代之的是由抽样数据估算出来的一个值,可能对mysql的执行计划的生成造成一定的影响)
- 执行计划中的成本估算不等同与实际的执行计划的成本(执行成本估算的准确的,执行计划也可能不是最优的。比如有两种:第一种需要读取更多页面,但是是顺序读取,而且大部分页面都已经在内存中;第二种需要读取更少页面,但是是随机读取,显然使用读取页面较多的会成本更低,但是mysql服务器层并不知道哪些页面在内存中、哪些页面在磁盘上、哪些页面要顺序读取、哪些页面要随机读取)
- MYSQL优化器所认为的最优可能与你所认为的最优不一样(我们希望执行时间尽可能的短,但是MYSQL是基于其成本模型选择最优的执行计划,但有些时候不是最快的执行计划)
- MYSQL从不考虑其他并发的查询,这可能会影响当前查询的速度(并发查询可能会涉及到锁的一些因素,但是mysql优化器并不考虑这些)
- MYSQL有时候也会基于一些固定的规则来生成执行计划(mysql并不是任何时候都是基于成本来优化的。如果查询中存在全文索引搜索条件的话,查询时就会使用全文索引来进行查找,有时候即使使用别的索引和where条件的组合会比全文索引更快,但mysql还是会使用全文索引,而不会使用其它索引)
- MYSQL不会考虑不受其控制的成本(例如执行存储过程、用户自定义的函数的成本都不在mysql的查询优化器的考虑范围之内)
5.MYSQL优化器可优化的SQL类型
- 重新定义表的关联顺序
- 将外连接转化成内连接(有时候,如果where条件和库表结构等都可能会让一个外连接转化为内连接:a left join b但是在where条件又出现了关于b表的过滤条件)
- 使用等价变换规则
- (5=5 and a>5)将被改写为a>5
- 优化集合函数count()、min()、max()
- 例如btree索引是按照顺序进行存储的,所以找到一列的最小值,只需要查询对应的btree索引最左端的记录就可以了,因此mysql可以直接获取索引的第一行记录就知道这一列的最小值是什么了。优化器生成执行计划的时候可以利用这一点,如果要找最大值,就可以直接获取索引的最后一行记录。
- 提示信息:select tables optimized away表示优化器