小米函数计算是事件驱动的服务器全托管的计算服务。在使用小米函数计算时,用户无需管理服务器等基础设施,只需编写并上传代码。小米函数计算将会为用户准备好计算资源,弹性可靠地运行任务,并提供日志查询、性能监控等功能。
在很多场景下,比如HTTP直接调用,或者从小爱技能服务访问函数计算,通常用户对函数的响应时间要求很高,用户希望能够在1秒之内甚至是几百毫秒之内返回结果,这就对函数计算的性能提出了很高的要求。
本文将为你揭秘小米函数计算背后所做的一些性能优化。
1、函数执行过程
下图是小米函数计算的架构示意图,以便展示完整的函数执行过程。
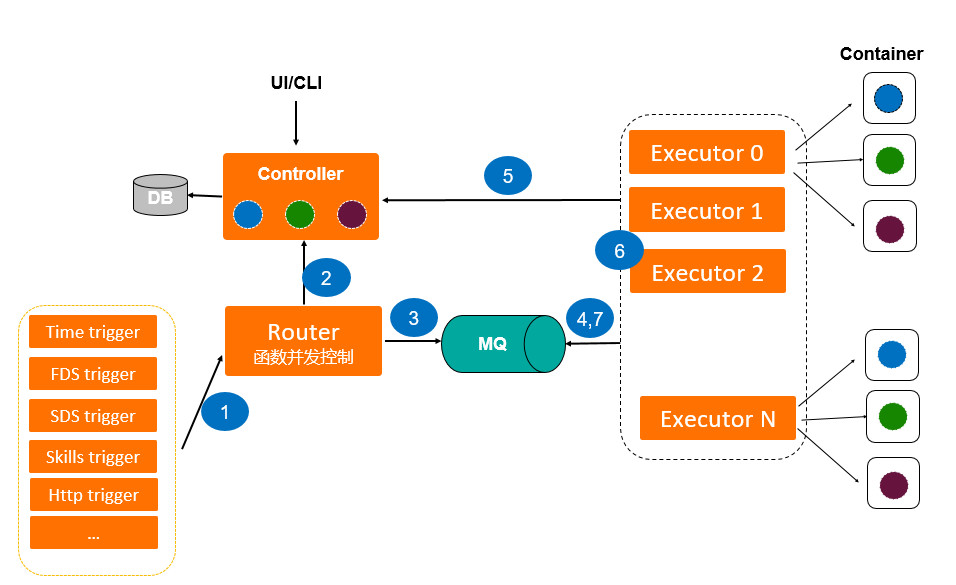
函数的执行是从各种各样的触发器(trigger)调用Router模块开始的。具体调用路径如下:
1.Router模块接收到用户调用函数的请求
2.Router模块访问Controller获取到函数的uid
3.Router把此次请求的参数以及函数的uid放入消息队列
4.Executor从消息队列中获取到用户请求参数和函数的uid
5.Executor从文件存储中拉取函数的代码,准备函数的docker运行环境
6.Executor调用运行成功的docker容器来加载并运行用户代码,得到执行结果
7.Executor将结果通过消息队列返回给Router
通过分析发现,前四步每次的执行时间没有太大的差距,很难在上面做很大的时间优化。相反,其他三步的执行时间存在着不确定性,有很大的优化空间。
所以重点就到了如何优化Executor进行函数调用上。
2、Executor的执行过程
Executor模块是小米函数计算的关键模块,它负责将用户的函数在docker容器中运行起来,同时它也是函数调用执行过程中延迟开销最大的一个模块,是性能优化的关键所在。
Executor执行的过程如下所示:
1.用docker create和 docker start来启动一个docker容器,用docker inspect 获取容器的ip地址,大约需要300~500毫秒
2.从文件存储中拉取用户的代码
3.访问容器里运行的HTTP服务,加载用户函数并执行得到函数执行结果
如上Executor的一个完整的执行过程,在小米函数计算上,被称之为函数调用执行的冷启动,函数的冷启动是比较耗时的函数调用方式,尤其是用户函数代码的拉取和多个docker命令的串行调用。
通过多次的测试对比,调研分析,在小米函数计算上做了下面三方面的优化来缩短函数运行环境的准备时间。
3、通用容器池
冷启动使得第一次函数调用的延迟比较长。 为了解决这个问题,函数计算预先创建了一定数量的docker容器,称之为通用容器池,这样在请求来到的时候就可以直接使用预先创建的容器,而无需调用docker命令来创建容器,去除了容器创建所需要的时间,在通用容器池中容器数量充足的情况下,冷启动就不会被触发,从而用户函数响应速度就会更快。
4、代码缓存
用户函数代码的拉取是一个耗时不稳定的操作,主要取决于网络情况和用户代码包的大小,经过测试即使是一个简单的python文件都需要大约80毫秒,而在小米函数计算上现在允许的用户代码包最大为50MB,即使是100M的宽带也需要大约5秒才能下载下来。通过在磁盘上缓存代码,每个用户只有在第一次分配到当前Executor的时候才会去访问文件存储服务,拉取用户函数代码,之后只需要把本地文件复制一份到容器的挂载目录即可,去除了用户函数每次拉取所需要的时间。
5、容器重用
如果用户两次触发相同的函数,并且第一个请求已经完成,小米函数计算可以重用第一个容器。 通过重用容器,避免了启动容器和拉取代码等操作,可以很大地降低延迟和提高吞吐量,用户在一段时间内对函数的调用次数越多,容器的重用率就越高,从而提高了函数的响应速度。
总结
通过通用容器池、代码缓存和容器重用,大大地提高了小米函数计算的响应速度,经过测试,P99延时从数秒缩减到了200毫秒。
除此之外,小米函数计算还在其他方面做了很多优化,来提升服务速度。这部分内容我们会在后面的文章中继续更新。
文章已获得原公众号:小米生态云作者授权,如需转载请联系原作者。