本文来自网易云社区。
时间轮实现
时间轮是一种环形的数据结构,分成多个格。
每个格代表一段时间,时间越短,精度越高。
每个格上用一个链表保存在该格的过期任务。
指针随着时间一格一格转动,并执行相应格子中的到期任务。
名词解释:
- 时间格:环形结构中用于存放延迟任务的区块
- 指针:指向当前操作的时间格,代表当前时间
- 格数:时间轮中时间格的个数
- 间隔:每个时间格之间的间隔,代表时间轮能达到的精度
- 总间隔:当前时间轮总间隔,等于格数*间隔,代表时间轮能表达的时间范围
单表时间轮
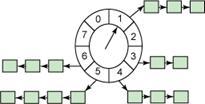
以上图为例,假设一个格子是1秒,则整个时间轮能表示的时间段为8s, 如果当前指针指向2,此时需要调度一个3s后执行的任务,需要放到第5个格子(2+3)中,指针再转3次就可以执行了。
单表时间轮存在的问题是:
格子的数量有限,所能代表的时间有限,当要存放一个10s后到期的任务怎么办?这会引起时间轮溢出。
有个办法是把轮次信息也保存到时间格链表的任务上。
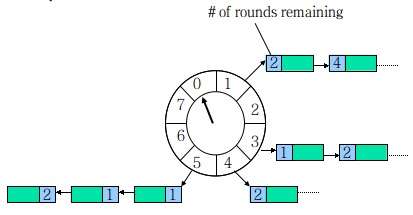
如果任务要在10s后执行,算出轮次10/8 round等1,格子10%8等于2,所以放入第二格。
检查过期任务时应当只执行round为0的任务,链表中其他任务的round减1。
带轮次单表时间轮存在的问题是:
如果任务的时间跨度很大,数量很大,单层时间轮会造成任务的round很大,单个格子的链表很长,每次检查的量很大,会做很多无效的检查。怎么办?
分层时间轮
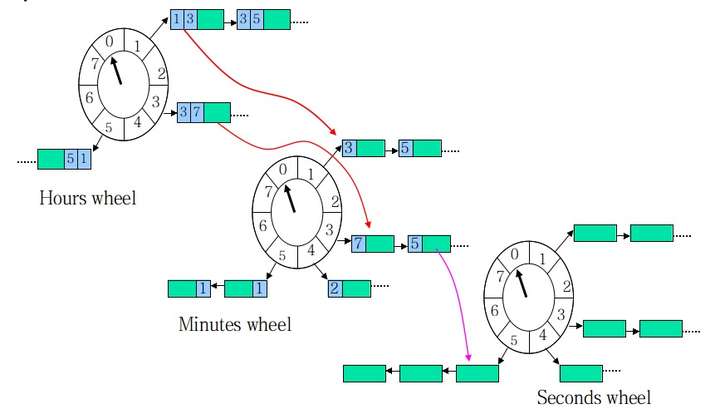
过期任务一定是在底层轮中被执行的,其他时间轮中的任务在接近过期时会不断的降级进入低一层的时间轮中。
分层时间轮中每个轮都有自己的格数和间隔设置,当最低层的时间轮转一轮时,高一层的时间轮就转一个格子。
分层时间轮大大增加了可表示的时间范围,同时减少了空间占用。
举个例子:
上图的分层时间轮可表达8 8 8=512s的时间范围,如果用单表时间轮可能需要512个格子, 而分层时间轮只要8+8+8=24个格子,如果要设计一个时间范围是1天的分层时间轮,三个轮的格子分别用24、60、60即可。
工作原理:
时间轮指针转动有两种方式:
- 根据自己的间隔转动(秒钟轮1秒转1格;分钟轮1分钟转1格;时钟轮1小时转1格)
- 通过下层时间轮推动(秒钟轮转1圈,分钟轮转1格;分钟轮转1圈,时钟轮转1格)
指针转到特定格子时有两种处理方式:
- 如果是底层轮,指针指向格子中链表上的元素均表示过期
- 如果是其他轮,将格子上的任务移动到精度细一级的时间轮上,比如时钟轮的任务移动到分钟轮上
举个例子:
- 添加1个5s后执行的任务
- 算出任务应该放在秒钟轮的第5个格子
- 在秒钟轮指针进行5次转动后任务会被执行
- 添加一个50s后执行的任务
- 算出该任务的延迟时间已经溢出秒钟轮
- 50/8=6,所以该任务会被保存在分钟轮的第6个格子
- 在秒钟轮走了6圈(6*8s=48s)之后,分钟轮的指针指向第6个格子
- 此时该格子中的任务会被降级到秒钟轮,并根据50%8=2,任务会被移动到秒钟轮的第2个格子
- 在秒钟轮指针又进行2次转动后(50s)任务会被执行
- 添加一个250s后执行的任务
- 算出该任务的延迟时间已经溢出分钟轮
- 250/8/8=3,所以该任务会被保存在时钟轮的第3个格子
- 在分钟轮走了3圈(3*64s=192s)之后,时钟轮的指针指向第3个格子
- 此时该格子中的任务会被降级到分钟轮,并根据(250-192)/8=7,任务会被移动到分钟轮的第7个格子
- 在秒钟轮走了7圈(7*8s=56s)之后,分钟轮的指针指向第7个格子
- 此时该格子中的任务会被降级到秒钟轮,并根据(250-192-56)=2,任务会被移动到秒钟轮的第2个格子
- 在秒钟轮指针又进行2次转动后任务会被执行
优点:
- 高性能(插入任务、删除任务的时间复杂度均为O(1),DelayQueue由于涉及到排序,插入和移除的复杂度是O(logn))
缺点:
- 数据是保存在内存,需要自己实现持久化
- 不具备分布式能力,需要自己实现高可用
- 延迟任务过期时间受时间轮总间隔限制
对于超出范围的任务可放在一个缓冲区中(可用队列、redis或数据库实现),等最高时间轮转到下一格子就从缓冲中取出符合范围的任务落到时间轮中。
比如:
- 添加一个600s后执行的任务A
- 算出该任务的延迟时间已经溢出时间轮
- 所以任务被保存到缓冲队列中
- 在时钟轮走了1格之后,会从缓冲队列中取满足范围的任务落到时间轮中
- 缓冲队列中的所有任务延迟时间均需减去64s,任务A减去64s后是536s,依然大于时间轮范围,所以不会被移出队列
- 在时钟轮又走了1格之后,任务A减去64s是536-64=472s,在时间轮范围内,会被落入时钟轮
之前的设计(DB/DelayQueue/ZooKeeper)
调度系统提供任务操作接口供业务系统提交任务、取消任务、反馈执行结果等。
针对dubbo调用,将任务抽象成JobCallbackService接口,由业务系统实现并注册成服务。
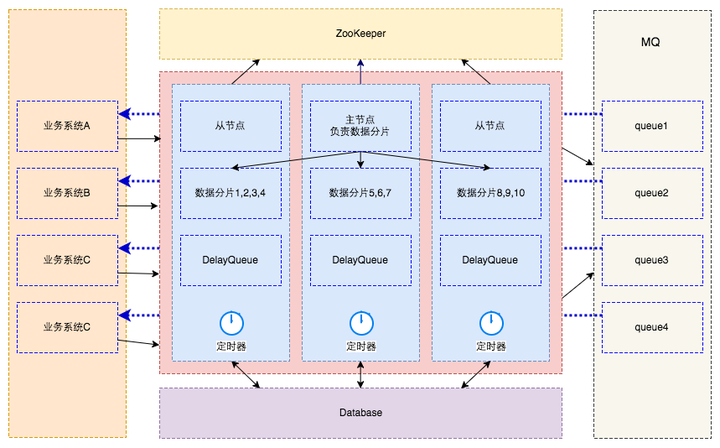
整体架构
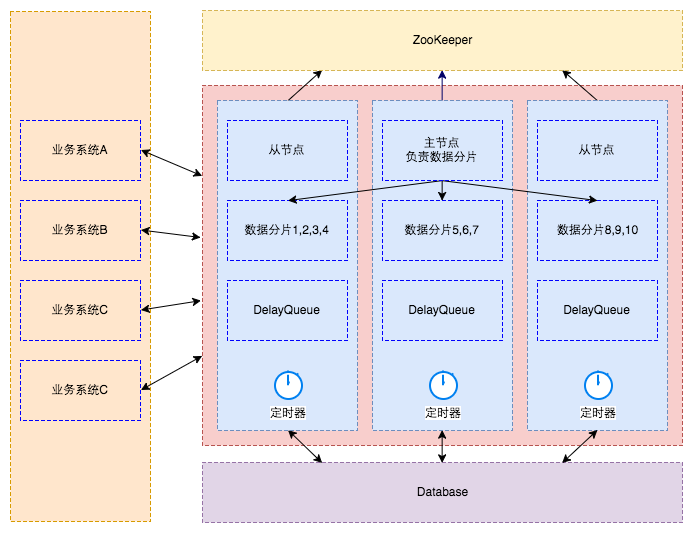
数据库:
- 负责保存所有的任务数据
内存队列:
- 实际为DelayQueue,延迟任务精确触发的机制由它保证
- 只存储未来N分钟内过期且最多1000个任务
ZooKeeper:
- 管理整个调度集群
- 存储调度节点信息
- 存储节点分片信息
主节点:
- 有新的节点上下线时对数据重新分片
调度节点:
- 提供dubbo、http接口供业务系统调用,用于提交任务、取消任务、反馈执行结果等
- 从ZK注册中心获取当前节点的分片信息,再从数据库拉取即将过期的数据放到DelayQueue
- 调用业务系统注册的回调服务接口,发起调度请求
- 接收业务系统的反馈结果,更新执行结果,移除任务或发起重试
业务系统:
- 作为被调度的服务需要实现回调接口JobCallbackService,并注册为dubbo服务提供者
- 在需要延迟任务的场景调用调度系统接口操作任务
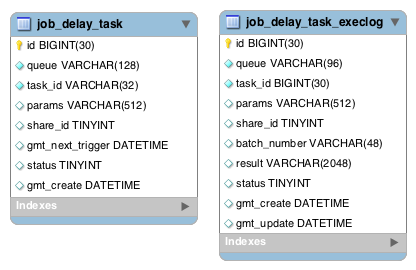
数据库设计
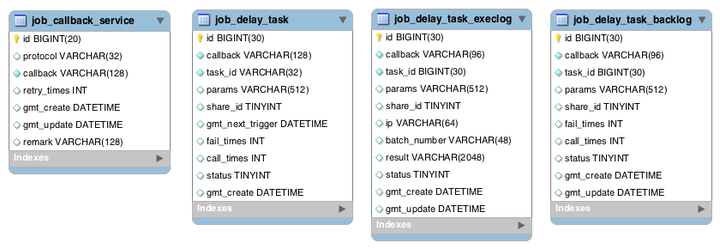
表说明
- job_callback_service:服务配置表,配置业务回调服务,包括服务协议、回调服务、重试次数
- job_delay_task:延迟任务表,用于存储延迟任务,包括任务分片号、回调服务、调用总次数、失败数、任务状态、回调参数等
- job_delay_task_execlog:延迟任务执行表,记录调度系统发起的每一次回调
- job_delay_task_backlog:延迟任务调度结果表,记录任务最终状态等信息
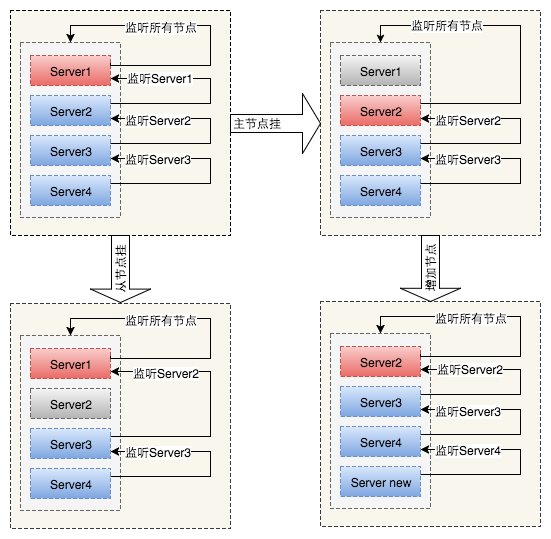
主从切换
利用ZooKeeper临时序列节点特性,序号最小的节点为主节点,其他节点为从节点。
主节点监听集群状态,集群状态发生变化时重新分片。
从节点监听序号比它小的兄弟节点,兄弟节点发生变化重新寻找和建立监听关系。
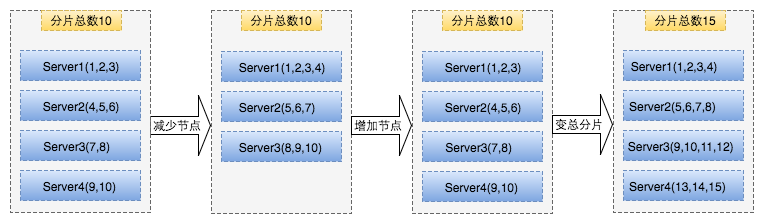
数据分片
任务状态
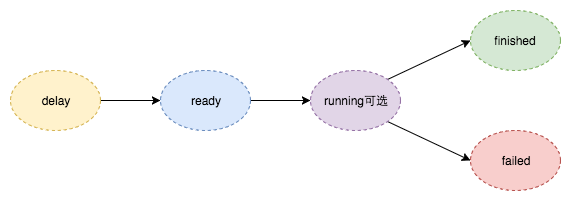
- delay:延迟任务提交后的初始状态
- ready:过期时间已到,消息推入就绪队列的状态
- running:业务订阅消息,收到消息开始处理的状态
- finished:业务处理成功
- failed:业务处理失败
主要流程
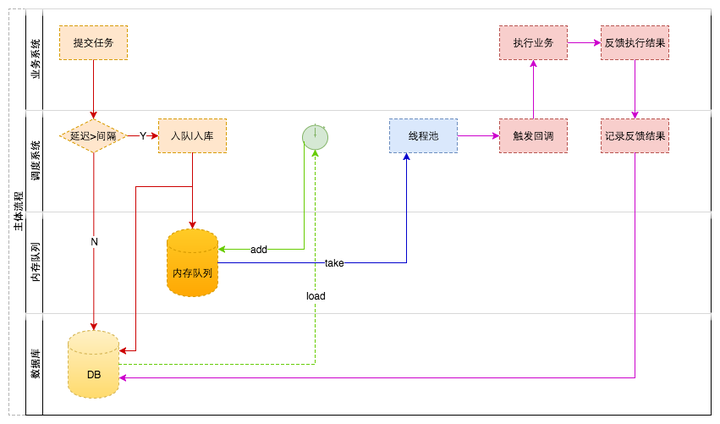
服务加载
- 从DB读取服务配置
- 根据配置动态构造Consumer对象并添加到Spring容器中
提交任务
- 业务系统通过dubbo或http接口提交任务
- 判断任务过期时间是否在一个扫描周期内
- 如果是,
- 设置分片号(从当前节点所负责的分片随机获取)
- 添加到内存队列
- 任务保存到job_delay_task表
- 如果否,
- 设置分片号(根据分片总数和随机算法算出分片号)
- 任务保存到delay_task表
定时器
- 由一个线程管理
- 根据配置的扫描间隔设置定时器的执行周期
- 根据当前时间和扫描间隔算出该时段的过期时间X-Delay
- 从DB获取过期时间在X-Delay之前的所有任务,并放到DelayQueue
调度任务
- 由一个线程池管理
- 所有线程都阻塞在DelayQueue的方法take
- take到任务,从DB中获取任务,判断是否存在
- 如果不在,什么也不做(任务已执行成功或已被删除)
- 如果存在,判断调用次数是否超过设置
- 如果不超
- 调用业务回调服务
- 从任务中取出调用的服务配置
- 从容器中获取对应的Consumer对象
- 异步调用业务回调服务
- 设置下次重试时间,记录调用日志job_delay_task_execlog
- 如果超过,将任务转移到job_delay_task_backlog
任务反馈
- 更新任务调用结果
优点
- 功能全面,高可用、易伸缩、可重试
缺点
- 略微复杂
- 需要将服务配置动态生成为Consumer对象
- 增加新的服务需要通知所有调度节点刷新
- 存在一定的耦合性(直接调用业务服务,协议耦合),如果接入系统是thrift协议呢?
- 需要处理任务的重试
- 调度系统直接回调业务服务,如果业务服务不可用可能会造成盲目重试,不能很好的控制流量(调度系统不知道业务服务的处理能力)
如果引入MQ,使用MQ来解耦服务调用的协议,保证任务的重试,并由消费方根据自己的处理能力控制流量会不会更好呢?
另一种方案(DB/DelayQueue/ZooKeeper/MQ)
整体架构
数据库设计
主要流程
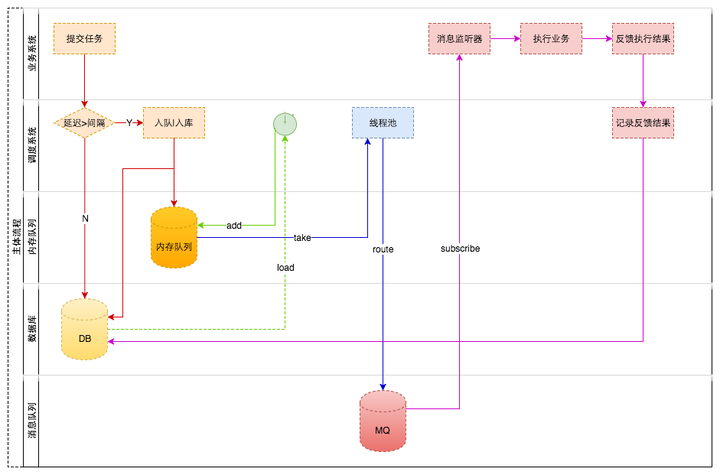
调度任务
- 由一个线程池管理
- 所有线程都阻塞在DelayQueue的take方法
- take到任务,从DB中获取任务,判断是否存在
- 如果不在,什么也不做(任务已执行成功或已被删除)
- 如果存在,将任务转移到job_delay_task_execlog;往消息队列投递消息
缺点
需要业务系统依赖于MQ
本文来自网易云社区,经作者陈志良授权发布。