| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
\num |
引用分组num匹配到的字符串 |
(?P<name>) |
分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
示例1:|
需求:匹配出0-100之间的数字
#coding=utf-8
import re
ret = re.match("[1-9]?\d","8")
print(ret.group()) # 8 ret = re.match("[1-9]?\d","78") print(ret.group()) # 78 # 不正确的情况 ret = re.match("[1-9]?\d","08") print(ret.group()) # 0 # 修正之后的 ret = re.match("[1-9]?\d$","08") if ret: print(ret.group()) else: print("不在0-100之间") # 添加| ret = re.match("[1-9]?\d$|100","8") print(ret.group()) # 8 ret = re.match("[1-9]?\d$|100","78") print(ret.group()) # 78 ret = re.match("[1-9]?\d$|100","08") # print(ret.group()) # 不是0-100之间 ret = re.match("[1-9]?\d$|100","100") print(ret.group()) # 100 示例2:( )
需求:匹配出163、126、qq邮箱
#coding=utf-8
import re
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group()) # [email protected] ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]") print(ret.group()) # [email protected] ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]") print(ret.group()) # [email protected] ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]") if ret: print(ret.group()) else: print("不是163、126、qq邮箱") # 不是163、126、qq邮箱 不是以4、7结尾的手机号码(11位)
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"] for tel in tels: ret = re.match("1\d{9}[0-35-68-9]", tel) if ret: print(ret.group()) else: print("%s 不是想要的手机号" % tel) 提取区号和电话号码
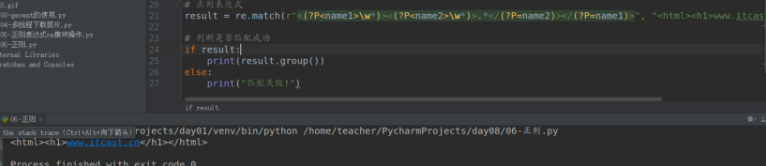
# 提取区号和电话号码
result = re.match("(\d{3,4})-(\d{7,8})", "010-12345678")
# 判断匹配结果
if result: print(result.group(1)) print(result.group(2)) else: print("匹配失败!") 示例3:\
需求:匹配出<html>hh</html>
#coding=utf-8
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</html>") print(ret.group()) # 如果遇到非正常的html格式字符串,匹配出错 ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>") print(ret.group()) # 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么 # 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式 ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>") print(ret.group()) # 因为2对<>中的数据不一致,所以没有匹配出来 test_label = "<html>hh</htmlbalabala>" ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", test_label) if ret: print(ret.group()) else: print("%s 这是一对不正确的标签" % test_label) 运行结果:
<html>hh</html>
<html>hh</htmlbalabala> <html>hh</html> <html>hh</htmlbalabala> 这是一对不正确的标签 示例4:\number
需求:匹配出<html><h1>www.itcast.cn</h1></html>
#coding=utf-8
import re
labels = ["<html><h1>www.itcast.cn</h1></html>", "<html><h1>www.itcast.cn</h2></html>"]
for label in labels: ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", label) if ret: print("%s 是符合要求的标签" % ret.group()) else: print("%s 不符合要求" % label) 运行结果:
<html><h1>www.itcast.cn</h1></html> 是符合要求的标签 <html><h1>www.itcast.cn</h2></html> 不符合要求 示例5:(?P<name>) (?P=name)
需求:匹配出<html><h1>www.itcast.cn</h1></html>
#coding=utf-8
import re
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
ret.group()
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>") ret.group() 注意:(?P<name>)和(?P=name)中的字母p大写
运行结果: