8.1. 认识 EXT2 文件系统
8.1.1. 硬盘组成与分割的复习
整颗磁盘的组成主要有:
- 圆形的磁盘;
- 机械手臂;
- 主轴马达;
数据储存与读取的重点在于磁盘,而磁盘上的物理组成则为:
- 扇区(Sector)为最小的物理储存单位,每个扇区为 512 bytes;
- 将扇区组成一个圆,那就是磁柱(Cylinder),磁柱是分割槽(partition)的最小单位;
- 第一个扇区最重要,里面有:主要开机区(Master boot record, MBR)占有 446 bytes;分割表(partition table)占有 64 bytes。
各种接口的磁盘在Linux中的文件名分别为:
- /dev/sd[a-p][1-15]:为SCSI, SATA, USB, Flash随身碟等接口的磁盘文件名;
- /dev/hd[a-d][1-63]:为 IDE 接口的磁盘文件名;
磁盘分区意即指定分割槽的启始与结束磁柱就是了。
那么指定分割槽的磁柱范围是记录在第一个扇区的分割表中!但是因为分割表仅有64bytes而已, 因此最多只能记录四笔分割槽的记录,这四笔记录我们称为主要 (primary) 或延伸 (extended) 分割槽,其中延伸分割槽还可以再分割出逻辑分割槽 (logical) , 而能被格式化的则仅有主要分割与逻辑分割而已。 分割的定义拿出来说明一下:
- 主要分割与延伸分割最多可以有四笔(硬盘的限制)
- 延伸分割最多只能有一个(操作系统的限制)
- 逻辑分割是由延伸分割持续切割出来的分割槽;
- 能够被格式化后,作为数据存取的分割槽为主要分割与逻辑分割。延伸分割无法格式化;
- 逻辑分割的数量依操作系统而不同,在Linux系统中,IDE硬盘最多有59个逻辑分割(5号到63号), SATA硬盘则有11个逻辑分割(5号到15号)。
8.1.2. 文件系统特性: 索引式文件系统
磁盘分区完毕后还需要进行格式化(format),之后操作系统才能够使用这个分割槽。『格式化』的原因是因为每种操作系统所设定的文件属性/权限并不相同, 为了存放这些档案所需的数据,因此就需要将分割槽进行格式化,以成为操作系统能够利用的『文件系统格式(filesystem)』。
每种操作系统能够使用的文件系统并不相同。 举例来说,windows 98 以前的微软操作系统主要利用的文件系统是 FAT (或 FAT16),windows 2000 以后的版本有所谓的 NTFS 文件系统,至于 Linux 的正统文件系统则为 Ext2 (Linux second extended file system, ext2fs)这一个。此外,在默认的情况下,windows 操作系统是不会认识 Linux 的 Ext2 的。
传统的磁盘与文件系统的应用中,一个分割槽就是只能够被格式化成为一个文件系统,所以我们可以说一个 filesystem 就是一个 partition。但是由于新技术的利用,例如我们常听到的LVM与软件磁盘阵列(software raid), 这些技术可以将一个分割槽格式化为多个文件系统(例如LVM),也能够将多个分割槽合成一个文件系统(LVM, RAID) ! 所以说,目前我们在格式化时已经不再说成针对 partition 来格式化了, 通常我们可以称呼一个可被挂载的数据为一个文件系统而不是一个分割槽!
文件系统的运作与操作系统的档案数据有关。较新的操作系统的档案数据除了档案实际内容外, 通常含有非常多的属性,例如 Linux 操作系统的档案权限(rwx)与文件属性(拥有者、群组、时间参数等)。 文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到 inode 中,至于实际数据则放置到 data block 区块中。 另外,还有一个超级区块 (superblock) 会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
每个 inode 与 block 都有编号,至于这三个数据的意义可以简略说明如下:
- superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
- inode:记录档案的属性,一个档案占用一个inode,同时记录此档案的数据所在的 block 号码;
- block:实际记录档案的内容,若档案太大时,会占用多个 block 。
由于每个 inode 与 block 都有编号,而每个档案都会占用一个 inode ,inode 内则有档案数据放置的 block 号码。 因此,如果能够找到档案的 inode 的话,那么自然就会知道这个档案所放置数据的 block 号码, 当然也就能够读出该档案的实际数据了。这是个比较有效率的作法。
我们将 inode 与 block 区块用图解来说明一下,如下图所示,文件系统先格式化出 inode 与 block 的区块,假设某一个档案的属性与权限数据是放置到 inode 4 号(下图较小方格内),而这个 inode 记录了档案数据的实际放置点为 2, 7, 13, 15 这四个 block 号码,此时我们的操作系统就能够据此来排列磁盘的阅读顺序,可以一口气将四个 block 内容读出来! 那么数据的读取就如同下图中的箭头所指定的模样了。
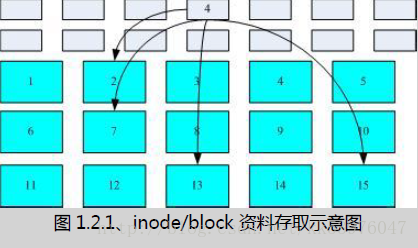
这种数据存取的方法我们称为索引式文件系统(indexed allocation)。那有没有其他的惯用文件系统可以比较一下啊? 有的,那就是我们惯用的随身碟(闪存),随身碟使用的文件系统一般为 FAT 格式。FAT 这种格式的文件系统并没有 inode 存在,所以 FAT 没有办法将这个档案的所有 block 在一开始就读取出来。每个 block 号码都记录在前一个 block 当中, 他的读取方式有点像底下这样:
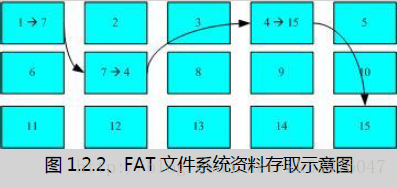
上图中我们假设档案的数据依序写入1->7->4->15号这四个 block 号码中, 但这个文件系统没有办法一口气就知道四个 block 的号码,他得要一个一个的将 block 读出后,才会知道下一个 block 在何处。 如果同一个档案数据写入的 block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的数据, 因此磁盘就会多转好几圈才能完整的读取到这个档案的内容!
需要碎片整理的原因就是档案写入的 block 太过于离散了,此时档案读取的效能将会变的很差。 这个时候可以透过碎片整理将同一个档案所属的 blocks 汇整在一起,这样数据的读取会比较容易! FAT 的文件系统需要三不五时的碎片整理一下,那么 Ext2 是否需要磁盘重整呢?
由于 Ext2 是索引式文件系统,基本上不太需要常常进行碎片整理的。但是如果文件系统使用太久, 常常删除/编辑/新增档案时,那么还是可能会造成档案数据太过于离散的问题,此时或许会需要进行重整一下的。 不过,老实说,似乎不太需要啦!
8.1.3. Linux 的 EXT2 文件系统(inode): data block, inode table, superblock, dumpe2fs
Linux 的档案除了原有的数据内容外,还含有非常多的权限与属性,这些权限与属性是为了保护每个用户所拥有数据的隐密性。 而前一小节我们知道 filesystem 里面可能含有的 inode/block/superblock 等。标准的 Linux 文件系统 Ext2 就是使用这种 inode 为基础的文件系统!
inode 的内容在记录档案的权限与相关属性,至于 block 区块则是在记录档案的实际内容。 而且文件系统一开始就将 inode 与 block 规划好了,除非重新格式化(或者利用 resize2fs 等指令变更文件系统大小),否则 inode 与 block 固定后就不再变动。如果我的文件系统高达数百GB时, 那么将所有的 inode 与 block 通通放置在一起将是很不智的决定,因为 inode 与 block 的数量太庞大,不容易管理。
因此 Ext2 文件系统在格式化的时候基本上是区分为多个区块群组 (block group) 的,每个区块群组都有独立的 inode/block/superblock 系统。整个来说,Ext2 格式化后有点像底下这样:
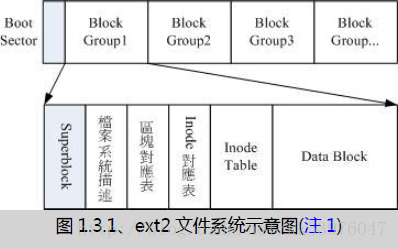
在整体的规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装开机管理程序, 这是个非常重要的设计,因为如此一来我们就能够将不同的开机管理程序安装到个别的文件系统最前端,而不用覆盖整颗硬盘唯一的 MBR, 这样也才能够制作出多重引导的环境!至于每一个区块群组(block group)的六个主要内容说明如后:
1.data block (资料区块) :
data block 是用来放置档案内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种而已。在格式化时 block 的大小就固定了,且每个 block 都有编号,以方便 inode 的记录。 不过要注意的是,由于 block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一档案容量并不相同。 因为 block 大小而产生的 Ext2 文件系统限制如下:
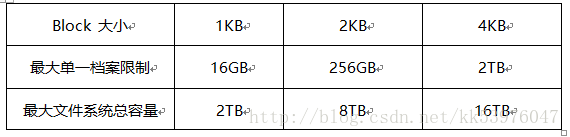
你需要注意的是,虽然 Ext2 已经能够支持大于 2GB 以上的单一档案容量,不过某些应用程序依然使用旧的限制, 也就是说,某些程序只能够捉到小于 2GB 以下的档案而已,这就跟文件系统无关了!
除此之外 Ext2 文件系统的 block 还有的限制如下:
- 原则上,block 的大小与数量在格式化完就不能够再变了(除非重新格式化);
- 每个 block 内最多只能够放置一个档案的数据;
- 承上,如果档案大于 block 的大小,则一个档案会占用多个 block 数量;
- 承上,若档案小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
如上第四点所说,由于每个 block 仅能容纳一个档案的数据,因此如果你的档案都非常小,但是你的 block 在格式化时却选用最大的 4K 时,可能会产生一些容量的浪费:

什么情况会产生上述状况呢?例如 BBS 网站的数据!如果 BBS 上面的数据使用的是纯文本档案来记载每篇留言, 而留言内容如果都写上『如题』时,想一想,是否就会产生很多小档案了呢?
既然大的 block 可能会产生较严重的磁盘容量浪费,那么我们是否就将 block 大小订为 1K 即可? 这也不妥,因为如果 block 较小的话,那么大型档案将会占用数量更多的 block ,而 inode 也要记录更多的 block 号码,此时将可能导致文件系统不良的读写效能。
所以我们可以说,在您进行文件系统的格式化之前,请先想好该文件系统预计使用的情况。
2.inode table (inode 表格):
如前所述 inode 的内容在记录档案的属性以及该档案实际数据是放置在哪几号 block 内! 基本上,inode 记录的档案数据至少有底下这些:
- 该档案的存取模式(read/write/excute);
- 该档案的拥有者与群组(owner/group);
- 该档案的容量;
- 该档案建立或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义档案特性的旗标(flag),如 SetUID…;
- 该档案真正内容的指向 (pointer);
inode 的数量与大小也是在格式化时就已经固定了,除此之外 inode 还有些什么特色呢?
- 每个 inode 大小均固定为 128 bytes;
- 每个档案都仅会占用一个 inode 而已;
- 承上,因此文件系统能够建立的档案数量与 inode 的数量有关;
- 系统读取档案时需要先找到 inode,并分析 inode 所记录的权限与用户是否符合,若符合才能够开始实际读取 block 的内容。
inode 要记录的数据非常多,但偏偏又只有 128bytes 而已, 而 inode 记录一个 block 号码要花掉 4byte ,假设我一个档案有 400MB 且每个 block 为 4K 时, 那么至少也要十万笔 block 号码的记录呢!inode 哪有这么多可记录的信息?为此我们的系统很聪明的将 inode 记录 block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。这是啥?我们将 inode 的结构画一下好了。
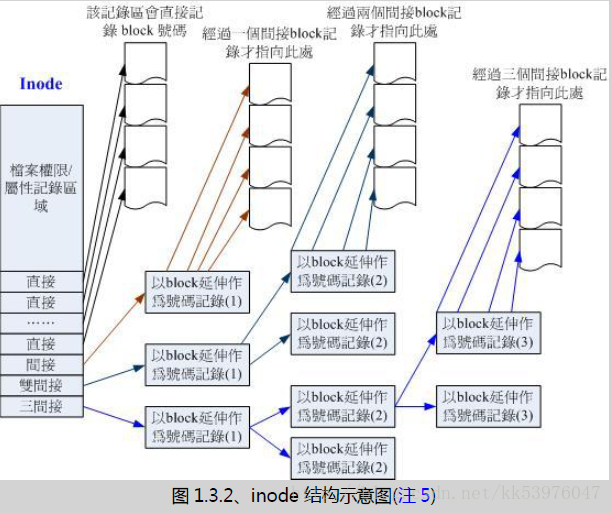
上图最左边为 inode 本身 (128 bytes),里面有 12 个直接指向 block 号码的对照,这 12 笔记录就能够直接取得 block 号码! 至于所谓的间接就是再拿一个 block 来当作记录 block 号码的记录区,如果档案太大时, 就会使用间接的 block 来记录编号。如上图 1.3.2 当中间接只是拿一个 block 来记录额外的号码而已。 同理,如果档案持续长大,那么就会利用所谓的双间接,第一个 block 仅再指出下一个记录编号的 block 在哪里, 实际记录的在第二个 block 当中。依此类推,三间接就是利用第三层 block 来记录编号! 这样子 inode 能够指定多少个 block 呢?我们以较小的 1K block 来说明好了,可以指定的情况如下:
- 12 个直接指向: 12*1K=12K
由于是直接指向,所以总共可记录 12 笔记录,因此总额大小为如上所示;
- 间接: 256*1K=256K
每笔 block 号码的记录会花去 4bytes,因此 1K 的大小能够记录 256 笔记录,因此一个间接可以记录的档案大小如上;
- 双间接: 256*256*1K=65536K
第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个号码,因此总额大小如上;
- 三间接: 256*256*256*1K=16777216K
第一层 block 会指定 256 个第二层,每个第二层可以指定 256 个第三层,每个第三层可以指定 256 个号码,因此总额大小如上;
- 总额:将直接、间接、双间接、三间接加总,得到 12 + 256 + 256*256 + 256*256*256 (K) = 16GB
此时我们知道当文件系统将 block 格式化为 1K 大小时,能够容纳的最大档案为 16GB,比较一下文件系统限制表的结果可发现是一致的!但这个方法不能用在 2K 及 4K block 大小的计算中, 因为大于 2K 的 block 将会受到 Ext2 文件系统本身的限制,所以计算的结果会不太符合之故。
3.Superblock (超级区块) :
Superblock 是记录整个 filesystem 相关信息的地方, 没有 Superblock ,就没有这个 filesystem 了。他记录的信息主要有:
- block 与 inode 的总量;
- 未使用与已使用的 inode / block 数量;
- block 与 inode 的大小 (block 为 1, 2, 4K,inode 为 128 bytes);
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1 。
Superblock 是非常重要的,因为我们这个文件系统的基本信息都写在这里,因此,如果 superblock 死掉了, 你的文件系统可能就需要花费很多时间去挽救!一般来说, superblock 的大小为 1024bytes。相关的 superblock 讯息我们等一下会以 dumpe2fs 指令来呼叫出来观察!
此外,每个 block group 都可能含有 superblock !但是我们也说一个文件系统应该仅有一个 superblock 而已,那是怎么回事啊? 事实上除了第一个 block group 内会含有 superblock 之外,后续的 block group 不一定含有 superblock , 而若含有 superblock 则该 superblock 主要是做为第一个 block group 内 superblock 的备份,这样可以进行 superblock 的救援!
4.Filesystem Description (文件系统描述说明) :
这个区段可以描述每个 block group 的开始与结束的 block 号码,以及说明每个区段 (superblock, bitmap, inodemap, data block) 分别介于哪一个 block 号码之间。这部份也能够用 dumpe2fs 来观察的。
5.block bitmap (区块对照表) :
想要新增档案时总会用到 block ,那你要使用那个 block 来记录。当然是选择『空的block 』来记录新档案的数据。 从 block bitmap 当中可以知道哪些 block 是空的,因此我们的系统就能够很快速的找到可使用的空间来处置档案。 同样的,如果你删除某些档案时,那么那些档案原本占用的 block 号码就得要释放出来, 此时在 block bitmpap 当中相对应到该 block 号码的标志就得要修改成为『未使用中』!这就是 bitmap 的功能。
6.inode bitmap (inode 对照表) :
这个其实与 block bitmap 是类似的功能,只是 block bitmap 记录的是使用与未使用的 block 号码, 至于 inode bitmap 则是记录使用与未使用的 inode 号码! 刚刚谈到的各部分数据都与 block 号码有关! 每个区段与 superblock 的信息都可以使用 dumpe2fs 这个指令来查询的!查询的方法与实际的观察如下:
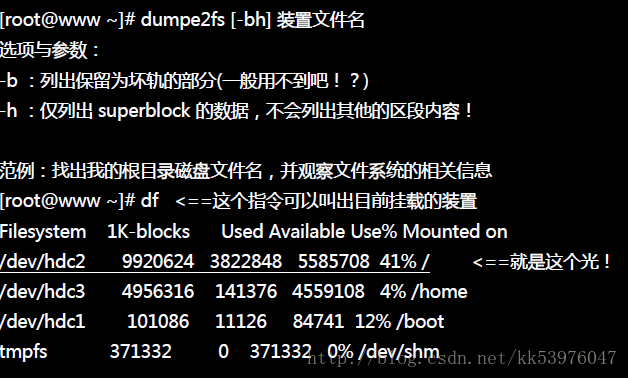
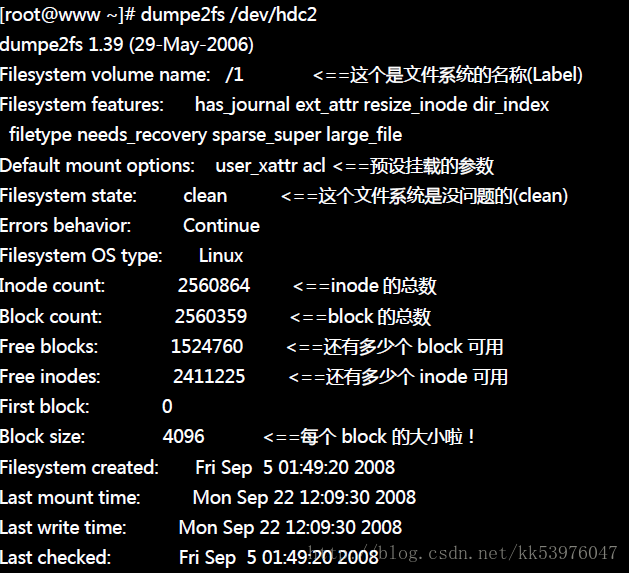


如上所示,利用 dumpe2fs 可以查询到非常多的信息,不过依内容主要可以区分为上半部是 superblock 内容, 下半部则是每个 block group 的信息了。从上面的表格中我们可以观察到这个 /dev/hdc2 规划的 block 为 4K, 第一个 block 号码为 0 号,且 block group 内的所有信息都以 block 的号码来表示的。 然后在 superblock 中还有谈到目前这个文件系统的可用 block 与 inode 数量!
至于 block group 的内容我们单纯看 Group0 信息好了。从上表中我们可以发现:
- Group0 所占用的 block 号码由 0 到 32767 号,superblock 则在第 0 号的 block 区块内!
- 文件系统描述说明在第 1 号 block 中;
- block bitmap 与 inode bitmap 则在 627 及 628 的 block 号码上。
- 至于 inode table 分布于 629-1641 的 block 号码中!
- 由于 (1)一个 inode 占用 128 bytes ,(2)总共有 1641 - 629 + 1(629本身) = 1013 个 block 花在 inode table 上, (3)每个 block 的大小为 4096 bytes(4K)。由这些数据可以算出 inode 的数量共有 1013 * 4096 / 128 = 32416 个 inode 啦!
- 这个 Group0 目前没有可用的 block 了,但是有剩余 32405 个 inode 未被使用;
- 剩余的 inode 号码为 12 号到 32416 号。
8.1.4. 与目录树的关系
由前一小节的介绍我们知道在 Linux 系统下,每个档案(不管是一般档案还是目录档案)都会占用一个 inode , 且可依据档案内容的大小来分配多个 block 给该档案使用。而由第六章的权限说明中我们知道目录的内容在记录文件名, 一般档案才是实际记录数据内容的地方。那么目录与档案在 Ext2 文件系统当中是如何记录数据的呢? 基本上可以这样说:
一、目录
当我们在 Linux 下的 ext2 文件系统建立一个目录时, ext2 会分配一个 inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码; 而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。也就是说目录所占用的 block 内容在记录如下的信息:

如果想要实际观察 root 家目录内的档案所占用的 inode 号码时,可以使用 ls -i 这个选项来处理:
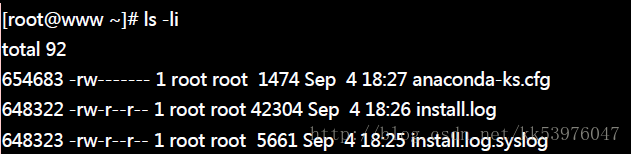
由于每个人所使用的计算机并不相同,系统安装时选择的项目与 partition 都不一样,因此你的环境不可能与我的 inode 号码一模一样!上表的右边所列出的 inode 仅是我的系统所显示的结果而已!而由这个目录的 block 结果我们现在就能够知道, 当你使用『 ll / 』时,出现的目录几乎都是 1024 的倍数,为什么呢?因为每个 block 的数量都是 1K, 2K, 4K !
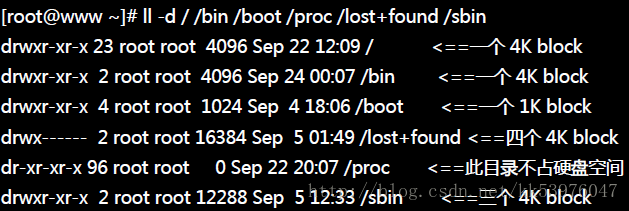
由于根目录 /dev/hdc2 使用的 block 大小为 4K ,因此每个目录几乎都是 4K 的倍数。 其中由于 /sbin 的内容比较复杂因此占用了 3 个 block ,此外 /boot 为独立的 partition , 该 partition 的 block 为 1K 而已,因此该目录就仅占用 1024 bytes 的大小!至于奇怪的 /proc 我们在第六章就讲过该目录不占硬盘容量!
由上面的结果我们知道目录并不只会占用一个 block 而已;
二、档案
当我们在 Linux 下的 ext2 建立一个一般档案时, ext2 会分配一个 inode 与相对于该档案大小的 block 数量给该档案。例如:假设我的一个 block 为 4 Kbytes ,而我要建立一个 100 KBytes 的档案,那么 linux 将分配一个 inode 与 25 个 block 来储存该档案! 但同时请注意,由于 inode 仅有 12 个直接指向,因此还要多一个 block 来作为区块号码的记录!
三、目录树读取
经过上面的说明你也应该要很清楚的知道 inode 本身并不记录文件名,文件名的记录是在目录的 block 当中。 因此在第六章档案与目录的权限说明中, 我们才会提到『新增/删除/更名文件名与目录的 w 权限有关』的特色!那么因为文件名是记录在目录的 block 当中, 因此当我们要读取某个档案时,就务必会经过目录的 inode 与 block ,然后才能够找到那个待读取档案的 inode 号码, 最终才会读到正确的档案的 block 内的数据。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode 号码(通常一个 filesystem 的最顶层 inode 号码会由 2 号开始!),此时就能够得到根目录的 inode 内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层的往下读到正确的档名。
如果我想要读取 /etc/passwd 这个档案时,系统是如何读取的呢?

在系统上面与 /etc/passwd 有关的目录与档案数据如上表所示,该档案的读取流程为(假设读取者身份为 vbird 这个一般身份使用者):
1. / 的 inode:
透过挂载点的信息找到 /dev/hdc2 的 inode 号码为 2 的根目录 inode,且 inode 规范的权限让我们可以读取该 block 的内容(有 r 与 x) ;
2. / 的 block:
经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码 (1912545);
3. etc/ 的 inode: 读取 1912545 号 inode 得知 vbird 具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容;
4. etc/ 的 block:
经过上个步骤取得 block 号码,并找到该内容有 passwd 档案的 inode 号码 (1914888);
5. passwd 的 inode:
读取 1914888 号 inode 得知 vbird 具有 r 的权限,因此可以读取 passwd 的 block 内容;
6. passwd 的 block:
最后将该 block 内容的数据读出来。
四、filesystem 大小与磁盘读取效能
另外,关于文件系统的使用效率上,当你的一个文件系统规划的很大时,例如 100GB 这么大时, 由于硬盘上面的数据总是来来去去的,所以,整个文件系统上面的档案通常无法连续写在一起(block 号码不会连续的意思), 而是填入式的将数据填入没有被使用的 block 当中。如果档案写入的 block 真的分的很散, 此时就会有所谓的档案数据离散的问题发生了。 果真如此,那么可以将整个 filesystme 内的数据全部复制出来,将该 filesystem 重新格式化, 再将数据给他复制回去即可解决这个问题。
此外,如果 filesystem 真的太大了,那么当一个档案分别记录在这个文件系统的最前面与最后面的 block 号码中, 此时会造成硬盘的机械手臂移动幅度过大,也会造成数据读取效能的低落。而且读取头再搜寻整个 filesystem 时, 也会花费比较多的时间去搜寻!因此, partition 的规划并不是越大越好, 而是真的要针对您的主机用途来进行规划才行!
8.1.5. EXT2/EXT3 档案的存取与日志式文件系统的功能
如果是新建一个档案或目录时,我们的 Ext2 是如何处理的呢? 这个时候就得要 block bitmap 及 inode bitmap 的帮忙了!假设我们想要新增一个档案,此时文件系统的行为是:
1. 先确定用户对于欲新增档案的目录是否具有 w 与 x 的权限,若有的话才能新增;
2. 根据 inode bitmap 找到没有使用的 inode 号码,并将新档案的权限/属性写入;
3. 根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,且更新 inode 的 block 指向数据;
4. 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
一般来说,我们将 inode table 与 data block 称为数据存放区域,至于其他例如 superblock、 block bitmap 与 inode bitmap 等区段就被称为 metadata (中介资料) ,因为 superblock, inode bitmap 及 block bitmap 的数据是经常发动的,每次新增、移除、编辑时都可能会影响到这三个部分的数据,因此才被称为中介数据。
一、数据的不一致 (Inconsistent) 状态
在一般正常的情况下,上述的新增动作当然可以顺利的完成。但是如果有个万一怎么办? 例如你的档案在写入文件系统时,因为不知名原因导致系统中断,使写入的数据仅有 inode table 及 data block 而已, 最后一个同步更新中介数据的步骤并没有做完,此时就会发生 metadata 的内容与实际数据存放区产生不一致 (Inconsistent) 的情况了。
在早期的 Ext2 文件系统中,如果发生这个问题, 那么系统在重新启动的时候,就会藉由 Superblock 当中记录的 valid bit (是否有挂载) 与 filesystem state (clean 与否) 等状态来判断是否强制进行数据一致性的检查!若有需要检查时则以 e2fsck 这支程序来进行的。
不过,这样的检查真的是很费时~因为要针对 metadata 区域与实际数据存放区来进行比对, 得要搜寻整个 filesystem ,如果你的文件系统有 100GB 以上,而且里面的档案数量又多时,而且在对 Internet 提供服务的服务器主机上面, 这样的检查真的会造成主机复原时间的拉长,这也就造成后来所谓日志式文件系统的兴起了。
二、日志式文件系统 (Journaling filesystem)
为了避免上述提到的文件系统不一致的情况发生,因此我们的前辈们想到一个方式, 如果在我们的 filesystem 当中规划出一个区块,该区块专门在记录写入或修订档案时的步骤, 那不就可以简化一致性检查的步骤了?也就是说:
1. 预备:当系统要写入一个档案时,会先在日志记录区块中纪录某个档案准备要写入的信息;
2. 实际写入:开始写入档案的权限与数据;开始更新 metadata 的数据;
3. 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该档案的纪录。
在这样的程序当中,万一数据的纪录过程当中发生了问题,那么我们的系统只要去检查日志记录区块, 就可以知道那个档案发生了问题,针对该问题来做一致性的检查即可,而不必针对整块 filesystem 去检查, 这样就可以达到快速修复 filesystem 的能力了!这就是日志式档案最基础的功能 。
那么我们的 ext2 可达到这样的功能吗?当然可以! 就透过 ext3 即可! ext3 是 ext2 的升级版本,并且可向下兼容 ext2 版本! 所以目前我们才建议大家,可以直接使用 ext3 这个 filesystem ! 如果你还记得 dumpe2fs 输出的讯息,可以发现 superblock 里面含有底下这样的信息:

8.1.6. Linux 文件系统的运作
由第零章的内容我们也知道, 所有的数据都得要加载到内存后 CPU 才能够对该数据进行处理。想一想,如果你常常编辑一个好大的档案, 在编辑的过程中又频繁的要系统来写入到磁盘中,由于磁盘写入的速度要比内存慢很多, 因此你会常常耗在等待硬盘的写入/读取上。真没效率! 为了解决这个效率的问题,因此我们的 Linux 使用的方式是透过一个称为异步处理 (asynchronously) 的方式。所谓的异步处理是这样的:
当系统加载一个档案到内存后,如果该档案没有被更动过,则在内存区段的档案数据会被设定为干净(clean)的。 但如果内存中的档案数据被更改过了(例如你用 nano 去编辑过这个档案),此时该内存中的数据会被设定为脏的 (Dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中 ! 系统会不定时的将内存中设定为『Dirty』的数据写回磁盘,以保持磁盘与内存数据的一致性。 你也可以利用第五章谈到的 sync指令来手动强迫写入磁盘。
我们知道内存的速度要比硬盘快的多,因此如果能够将常用的档案放置到内存当中,这不就会增加系统性能吗? 因此我们 Linux 系统上面文件系统与内存有非常大的关系:
- 系统会将常用的档案数据放置到主存储器的缓冲区,以加速文件系统的读/写;
- 承上,因此 Linux 的物理内存最后都会被用光!这是正常的情况!可加速系统效能;
- 你可以手动使用 sync 来强迫内存中设定为 Dirty 的档案回写到磁盘中;
- 若正常关机时,关机指令会主动呼叫 sync 来将内存的数据回写入磁盘内;
- 但若不正常关机(如跳电、当机或其他不明原因),由于数据尚未回写到磁盘内, 因此重新启动后可能会花很多时间在进行磁盘检验,甚至可能导致文件系统的损毁(非磁盘损毁)。
8.1.7. 挂载点的意义 (mount point)
每个 filesystem 都有独立的 inode / block / superblock 等信息,这个文件系统要能够链接到目录树才能被我们使用。 将文件系统与目录树结合的动作我们称为『挂载』。 关于挂载的一些特性我们在第三章稍微提过, 重点是:挂载点一定是目录,该目录为进入该文件系统的入口。 因此并不是你有任何文件系统都能使用,必须要『挂载』到目录树的某个目录后,才能够使用该文件系统的。
举例来说,如果你是依据鸟哥的方法安装你的 CentOS 5.x 的话, 那么应该会有三个挂载点才是,分别是 /, /boot, /home 三个 (鸟哥的系统上对应的装置文件名为 /dev/hdc2, /dev/hdc1, /dev/hdc3)。 那如果观察这三个目录的 inode 号码时,我们可以发现如下的情况:

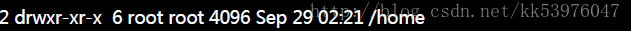
由于 filesystem 最顶层的目录之 inode 一般为 2 号,因此可以发现 /, /boot, /home 为三个不同的 filesystem ! (因为每一行的文件属性并不相同,且三个目录的挂载点也均不相同之故。) 我们在第七章一开始的路径中曾经提到根目录下的 . 与 .. 是相同的东西, 因为权限是一模一样的!如果使用文件系统的观点来看,同一个 filesystem 的某个 inode 只会对应到一个档案内容而已(因为一个档案占用一个 inode 之故), 因此我们可以透过判断 inode 号码来确认不同文件名是否为相同的档案!所以可以这样看:

上面的信息中由于挂载点均为 / ,因此三个档案 (/, /., /..) 均在同一个 filesystem 内,而这三个档案的 inode 号码均为 2 号,因此这三个档名都指向同一个 inode 号码,当然这三个档案的内容也就完全一模一样了! 也就是说,根目录的上层 (/..) 就是他自己!
8.1.8. 其他 Linux 支持的文件系统与 VFS
虽然 Linux 标准文件系统是 ext2 ,且还有增加了日志功能的 ext3 ,事实上,Linux 还有支持很多文件系统格式的, 尤其是最近这几年推出了好几种速度很快的日志式文件系统,包括 SGI 的 XFS 文件系统, 可以适用更小型档案的 Reiserfs 文件系统,以及 Windows 的 FAT 文件系统等等, 都能够被 Linux 所支持!常见支持文件系统有:
- 传统文件系统:ext2 / minix / MS-DOS / FAT (用 vfat 模块) / iso9660 (光盘)等等;
- 日志式文件系统: ext3 / ReiserFS / Windows’ NTFS / IBM’s JFS / SGI’s XFS
- 网络文件系统: NFS / SMBFS
想要知道你的 Linux 支持的文件系统有哪些,可以察看底下这个目录:

系统目前已加载到内存中支持的文件系统则有:

Linux VFS (Virtual Filesystem Switch)
那么 Linux 的核心又是如何管理这些认识的文件系统呢? 其实,整个 Linux 的系统都是透过一个名为 Virtual Filesystem Switch 的核心功能去读取 filesystem 的。 也就是说,整个 Linux 认识的 filesystem 其实都是 VFS 在进行管理,我们使用者并不需要知道每个 partition 上头的 filesystem 是什么, VFS 会主动的帮我们做好读取的动作。
假设你的 / 使用的是 /dev/hda1 ,用 ext3 ,而 /home 使用 /dev/hda2 ,用 reiserfs , 那么你取用 /home/dmtsai/.bashrc 时,有特别指定要用的什么文件系统的模块来读取吗? 应该是没有吧!这个就是 VFS 的功能啦!透过这个 VFS 的功能来管理所有的 filesystem, 省去我们需要自行设定读取文件系统的定义!整个 VFS 可以约略用下图来说明:
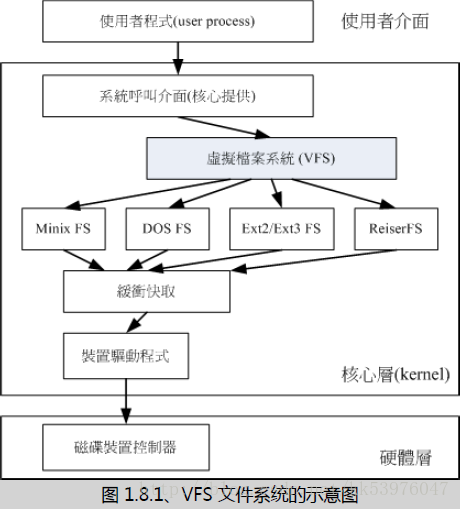
老实说,文件系统真的不好懂! 如果你想要对文件系统有更深入的了解,文末的相关连结(注7)务必要参考参考才好! 鸟哥有找了一些数据放置于这里:
Ext2/Ext3 文件系统:http://linux.vbird.org/linux_basic/1010appendix_B.php
8.2. 文件系统的简单操作
我们得要知道如何查询整体文件系统的总容量与每个目录所占用的容量! 此外,介绍连结档 (Link file) 。
8.2.1. 磁盘与目录的容量: df, du
现在我们知道磁盘的整体数据是在 superblock 区块中,但是每个各别档案的容量则在 inode 当中记载的。 那在文字接口底下该如何叫出这几个数据呢?底下就让我们来谈一谈这两个指令:
一、df:列出文件系统的整体磁盘使用量;

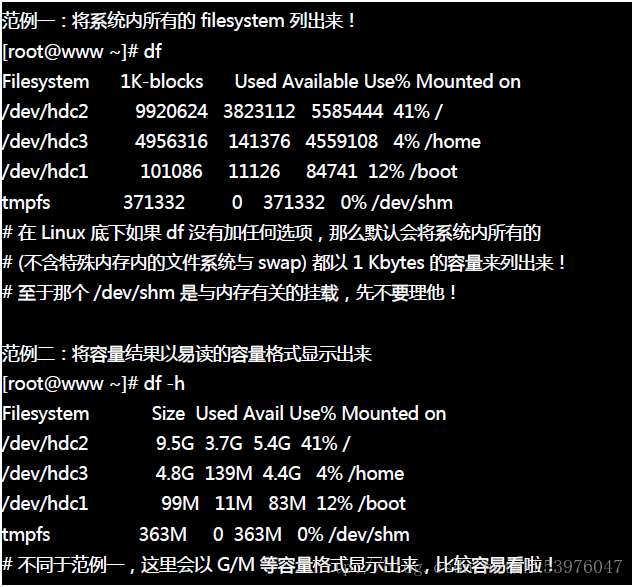
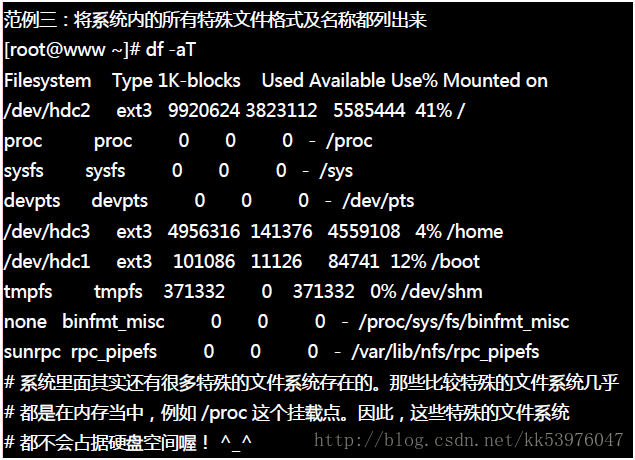


先来说明一下范例一所输出的结果讯息为:
- Filesystem:代表该文件系统是在哪个 partition ,所以列出装置名称;
- 1k-blocks:说明底下的数字单位是 1KB !可利用 -h 或 -m 来改变容量;
- Used:使用掉的硬盘空间!
- Available:剩下的磁盘空间大小;
- Use%:就是磁盘的使用率!如果使用率高达 90% 以上时, 最好需要注意一下了,免得容量不足造成系统问题!(例如最容易被灌爆的 /var/spool/mail 这个放置邮件的磁盘)
- Mounted on:就是磁盘挂载的目录所在!(挂载点!)
由于 df 主要读取的数据几乎都是针对一整个文件系统,因此读取的范围主要是在 Superblock 内的信息, 所以这个指令显示结果的速度非常的快速!在显示的结果中你需要特别留意的是那个根目录的剩余容量! 因为我们所有的数据都是由根目录衍生出来的,因此当根目录的剩余容量剩下 0 时,那你的 Linux 可能就问题很大了。
另外需要注意的是,如果使用 -a 这个参数时,系统会出现 /proc 这个挂载点,但是里面的东西都是 0 ,不要紧张! /proc 的东西都是 Linux 系统所需要加载的系统数据,而且是挂载在『内存当中』的, 所以当然没有占任何的硬盘空间!
至于那个 /dev/shm/ 目录,其实是利用内存虚拟出来的磁盘空间! 由于是透过内存仿真出来的磁盘,因此你在这个目录底下建立任何数据文件时,访问速度是非常的快速的!(在内存内工作) 不过,也由于他是内存仿真出来的,因此这个文件系统的大小在每部主机上都不一样,而且建立的东西在下次开机时就消失了!
二、du:评估文件系统的磁盘使用量(常用在推估目录所占容量)

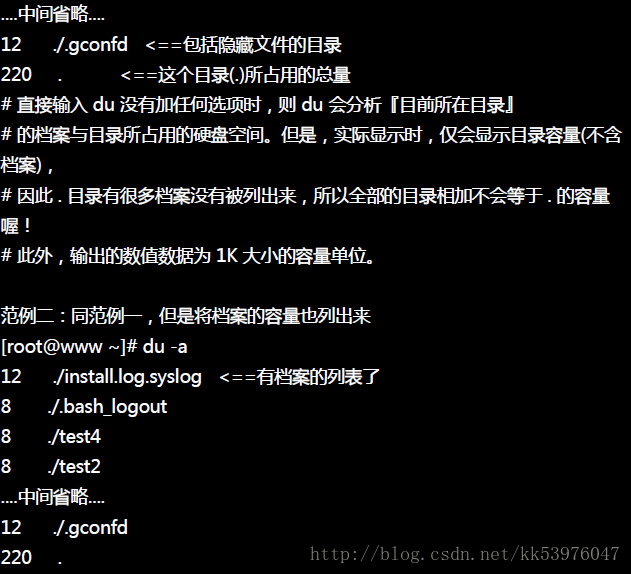

与 df 不一样的是,du 这个指令其实会直接到文件系统内去搜寻所有的档案数据, 所以上述第三个范例指令的运作会执行一小段时间!此外,在默认的情况下,容量的输出是以 KB 来设计的, 如果你想要知道目录占了多少 MB ,那么就使用 -m 这个参数即可!如果你只想要知道该目录占了多少容量的话,使用 -s 就可以!
至于 -S 这个选项部分,由于 du 默认会将所有档案的大小均列出,因此假设你在 /etc 底下使用 du 时, 所有的档案大小,包括 /etc 底下的次目录容量也会被计算一次。然后最终的容量 (/etc) 也会加总一次, 因此很多朋友都会误会 du 分析的结果不太对劲。所以如果想要列出某目录下的全部数据, 或许也可以加上 -S 的选项,减少次目录的加总!
8.2.2. 实体链接与符号链接: ln
在 Linux 底下的连结档有两种,一种是类似 Windows 的快捷方式功能的档案,可以让你快速的链接到目标档案(或目录); 另一种则是透过文件系统的 inode 连结来产生新档名,而不是产生新档案!这种称为实体链接 (hard link)。
一、Hard Link (实体链接, 硬式连结或实际连结)
在前一小节当中,我们知道几件重要的信息,包括:
- 每个档案都会占用一个 inode ,档案内容由 inode 的记录来指向;
- 想要读取该档案,必须要经过目录记录的文件名来指向到正确的 inode 号码才能读取。
也就是说,其实文件名只与目录有关,但是档案内容则与 inode 有关。 有没有可能有多个档名对应到同一个 inode 号码呢?有的!那就是 hard link 的由来。 所以简单的说:hard link 只是在某个目录下新增一笔档名链接到某 inode 号码的关连记录而已。
举个例子来说,假设我系统有个 /root/crontab 他是 /etc/crontab 的实体链接,也就是说这两个档名连结到同一个 inode , 自然这两个文件名的所有相关信息都会一模一样(除了文件名之外)。实际的情况可以如下所示:

你可以发现两个档名都连结到 1912701 这个 inode 号码,是否档案的权限/属性完全一样呢? 因为这两个『档名』其实是一模一样的『档案』!而且你也会发现第二个字段由原本的 1 变成 2 了! 那个字段称为『连结』,这个字段的意义为:『有多少个档名链接到这个 inode 号码』的意思。 如果将读取到正确数据的方式画成示意图,就类似如下画面:
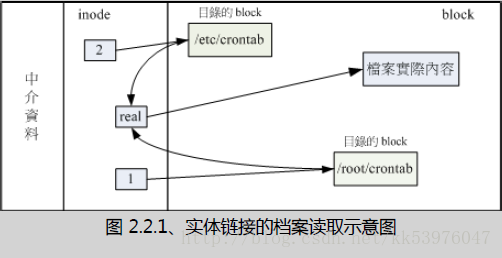
上图的意思是,你可以透过 1 或 2 的目录之 inode 指定的 block 找到两个不同的档名,而不管使用哪个档名均可以指到 real 那个 inode 去读取到最终数据!那这样有什么好处呢?最大的好处就是『安全』!如同上图中, 如果你将任何一个『档名』删除,其实 inode 与 block 都还是存在的! 此时你可以透过另一个『档名』来读取到正确的档案数据!此外,不论你使用哪个『档名』来编辑, 最终的结果都会写入到相同的 inode 与 block 中,因此均能进行数据的修改!
一般来说,使用 hard link 设定链接文件时,磁盘的空间与 inode 的数目都不会改变! 我们还是由图 2.2.1 来看,由图中可以知道, hard link 只是在某个目录下的 block 多写入一个关连数据而已,既不会增加 inode 也不会耗用 block 数量!
hard link 的制作中,其实还是可能会改变系统的 block 的,那就是当你新增这笔数据却刚好将目录的 block 填满时,就可能会新加一个 block 来记录文件名关连性,而导致磁盘空间的变化!不过,一般 hard link 所用掉的关连数据量很小,所以通常不会改变 inode 与磁盘空间的大小!
由图 2.2.1 其实我们也能够知道,事实上 hard link 应该仅能在单一文件系统中进行的,应该是不能够跨文件系统才对! 因为图 2.2.1 就是在同一个 filesystem 上嘛!所以 hard link 是有限制的:
- 不能跨 Filesystem;
- 不能 link 目录。
不能跨 Filesystem 还好理解,那不能 hard link 到目录又是怎么回事呢?这是因为如果使用 hard link 链接到目录时, 链接的数据需要连同被链接目录底下的所有数据都建立链接,举例来说,如果你要将 /etc 使用实体链接建立一个 /etc_hd 的目录时,那么在 /etc_hd 底下的所有档名同时都与 /etc 底下的档名要建立 hard link 的,而不是仅连结到 /etc_hd 与 /etc 而已。 并且,未来如果需要在 /etc_hd 底下建立新档案时,连带的, /etc 底下的数据又得要建立一次 hard link ,因此造成环境相当大的复杂度。 所以,目前 hard link 对于目录暂时还是不支持的!
二、Symbolic Link (符号链接,亦即是快捷方式)
相对于 hard link , Symbolic link 可就好理解多了,基本上, Symbolic link 就是在建立一个独立的档案,而这个档案会让数据的读取指向他 link 的那个档案的档名 !由于只是利用档案来做为指向的动作, 所以,当来源档被删除之后,symbolic link 的档案会『开不了』, 会一直说『无法开启某档案!』。实际上就是找不到原始『档名』而已啦!
举例来说,我们先建立一个符号链接文件链接到 /etc/crontab 去看看:
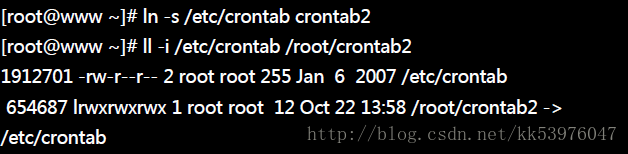
由上表的结果我们可以知道两个档案指向不同的 inode 号码,当然就是两个独立的档案存在! 而且连结档的重要内容就是他会写上目标档案的『文件名』, 你可以发现为什么上表中连结档的大小为 12 bytes 呢? 因为箭头(–>)右边的档名『/etc/crontab』总共有 12 个英文,每个英文占用 1 个 byes ,所以档案大小就是 12bytes了!
关于上述的说明,我们以如下图示来解释:
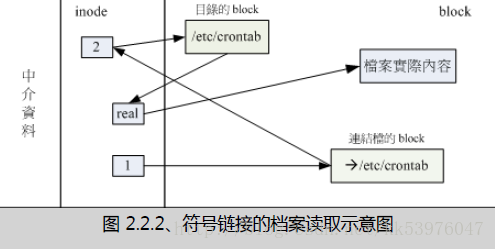
由 1 号 inode 读取到连结档的内容仅有档名,根据档名链接到正确的目录去取得目标档案的 inode , 最终就能够读取到正确的数据了。你可以发现的是,如果目标档案(/etc/crontab)被删除了,那么整个环节就会无法继续进行下去, 所以就会发生无法透过连结档读取的问题了!
这里还是得特别留意,这个 Symbolic Link 与 Windows 的快捷方式可以给他划上等号,由 Symbolic link 所建立的档案为一个独立的新的档案,所以会占用掉 inode 与 block !
由上面的说明来看,似乎 hard link 比较安全,因为即使某一个目录下的关连数据被杀掉了, 也没有关系,只要有任何一个目录下存在着关连数据,那么该档案就不会不见!举上面的例子来说,我的 /etc/crontab 与 /root/crontab 指向同一个档案,如果我删除了 /etc/crontab 这个档案,该删除的动作其实只是将 /etc 目录下关于 crontab 的关连数据拿掉而已, crontab 所在的 inode 与 block 其实都没有被变动!
不过由于 Hard Link 的限制太多了,包括无法做『目录』的 link , 所以在用途上面是比较受限的!反而是 Symbolic Link 的使用方面较广!要制作连结档就必须要使用 ln 这个指令!
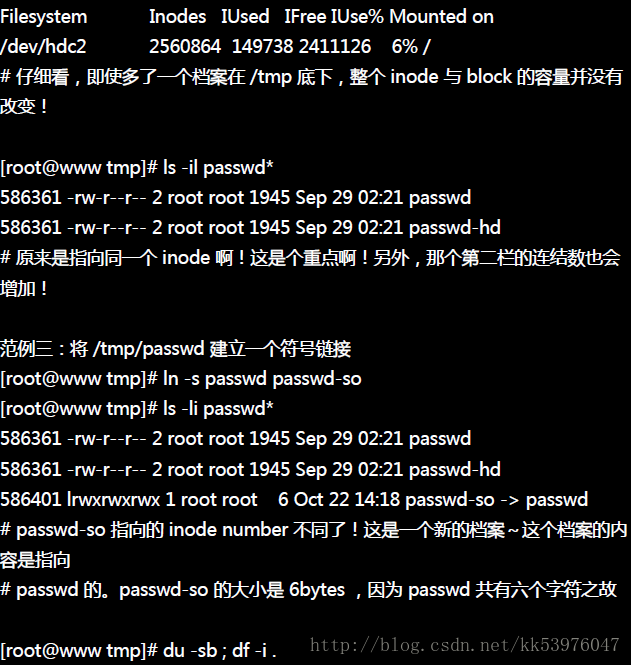

使用 ln 如果不加任何参数的话,那么就是 Hard Link !如同范例二的情况,增加了 hard link 之后,可以发现使用 ls -l 时,显示的 link 那一栏属性增加了!而如果这个时候砍掉 passwd 会发生什么事情呢?passwd-hd 的内容还是会跟原来 passwd 相同,但是 passwd-so 就会找不到该档案!
而如果 ln 使用 -s 的参数时,就做成差不多是 Windows 底下的『快捷方式』的意思。当你修改 Linux 下的 symbolic link 档案时,则更动的其实是『原始档』, 所以不论你的这个原始档被连结到哪里去,只要你修改了连结档,原始档就跟着变! 以上面为例,由于你使用 -s 的参数建立一个名为 passwd-so 的档案,则你修改 passwd-so 时,其内容与 passwd 完全相同,并且,当你按下储存之后,被改变的将是 passwd 这个档案!
此外,如果你做了底下这样的连结: ln -s /bin /root/bin
那么如果你进入 /root/bin 这个目录下,『请注意!该目录其实是 /bin 这个目录,因为你做了连结档了 !』所以,如果你进入 /root/bin 这个刚刚建立的链接目录, 并且将其中的数据杀掉时, /bin 里面的数据就通通不见了!这点请千万注意!所以赶紧利用『rm /root/bin 』 将这个连结档删除!
基本上, Symbolic link 的用途比较广,所以您要特别留意 symbolic link 的用法!未来一定还会常常用到的!
三、关于目录的 link 数量:
当我们以 hard link 进行『档案的连结』时,可以发现,在 ls -l 所显示的第二字段会增加一才对,那么请教,如果建立目录时,他默认的 link 数量会是多少? 让我们来想一想,一个『空目录』里面至少会存在些什么?呵呵!就是存在 . 与 .. 这两个目录啊! 那么,当我们建立一个新目录名称为 /tmp/testing 时,基本上会有三个东西,那就是:
- /tmp/testing
- /tmp/testing/.
- /tmp/testing/..
而其中 /tmp/testing 与 /tmp/testing/. 其实是一样的!都代表该目录。而 /tmp/testing/.. 则代表 /tmp 这个目录,所以说,当我们建立一个新的目录时, 『新的目录的 link 数为 2 ,而上层目录的 link 数则会增加 1 』 不信的话,我们来作个测试看看:
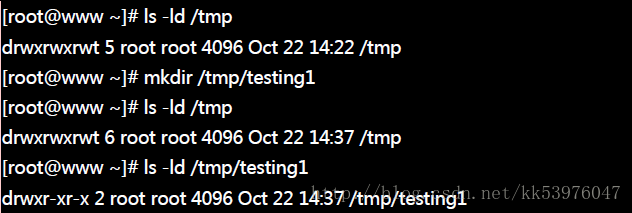
原本的所谓上层目录 /tmp 的 link 数量由 5 增加为 6 ,至于新目录 /tmp/testing 则为 2 ,这样可以理解目录的 link 数量的意义了吗?
8.3. 磁盘的分割、格式化、检验与挂载
如果我们想要在系统里面新增一颗硬盘时,应该有哪些动作需要做的呢:
1. 对磁盘进行分割,以建立可用的 partition ;
2. 对该 partition 进行格式化( format ),以建立系统可用的 filesystem;
3. 若想要仔细一点,则可对刚刚建立好的 filesystem 进行检验;
4. 在 Linux 系统上,需要建立挂载点 ( 亦即是目录 ),并将他挂载上来;
在上述的过程当中,还有很多需要考虑的,例如磁盘分区槽 (partition) 需要定多大? 是否需要加入 journal 的功能?inode 与 block 的数量应该如何规划等等的问题。但是这些问题的决定, 都需要与你的主机用途来加以考虑的~所以,在这个小节里面,仅会介绍几个动作而已, 更详细的设定值,则需要以你未来的经验来参考!
8.3.1. 磁盘分区: fdisk, partprobe


由于每个人的环境都不一样,因此每部主机的磁盘数量也不相同。所以你可以先使用 df 这个指令找出可用磁盘文件名, 然后再用 fdisk 来查阅。在你进入 fdisk 这支程序的工作画面后,如果您的硬盘太大的话(通常指磁柱数量多于 1024 以上),就会出现如上讯息。这个讯息仅是在告知你,因为某些旧版的软件与操作系统并无法支持大于 1024 磁柱 (cylinter) 后的扇区使用,不过我们新版的 Linux 是没问题!底下继续来看看 fdisk 内如何操作相关动作!

使用 fdisk 这支程序是完全不需要背指令的!如同上面的表格中,你只要按下 m 就能够看到所有的动作! 不管你进行了什么动作,只要离开 fdisk 时按下『q』,那么所有的动作『都不会生效!』相反的, 按下『w』就是动作生效的意思。
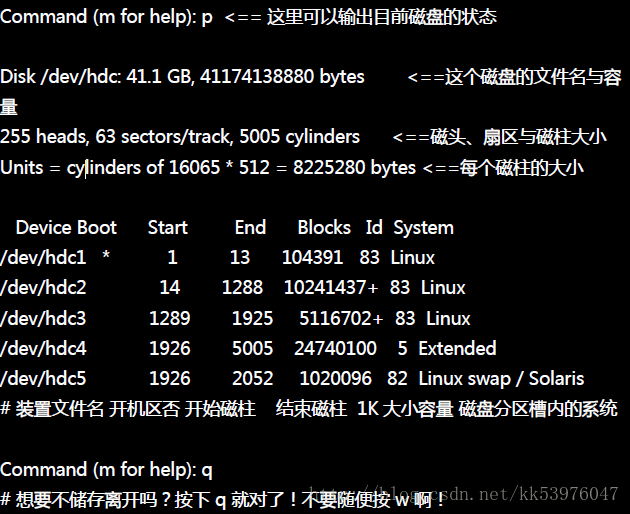
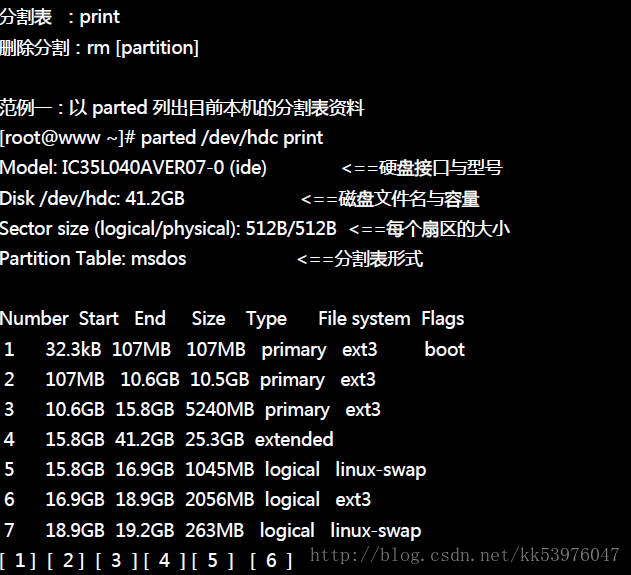
使用『 p 』可以列出目前这颗磁盘的分割表信息,这个信息的上半部在显示整体磁盘的状态。这个磁盘共有 41.1GB 左右的容量,共有 5005 个磁柱,每个磁柱透过 255 个磁头在管理读写, 每个磁头管理 63 个扇区,而每个扇区的大小均为 512bytes ,因此每个磁柱为『 255*63*512 = 16065*512 = 8225280bytes 』。 下半部的分割表信息主要在列出每个分割槽的个别信息项目。每个项目的意义为:
- Device:装置文件名,依据不同的磁盘接口/分割槽位置而变。
- Boot:是否为开机引导块块?通常 Windows 系统的 C 需要这块!
- Start, End:这个分割槽在哪个磁柱号码之间,可以决定此分割槽的大小;
- Blocks:就是以 1K 为单位的容量。如上所示,/dev/hdc1 大小为104391K = 102MB ;
- ID, System:代表这个分割槽内的文件系统应该是啥!不过这个项目只是一个提示而已, 不见得真的代表此分割槽内的文件系统!
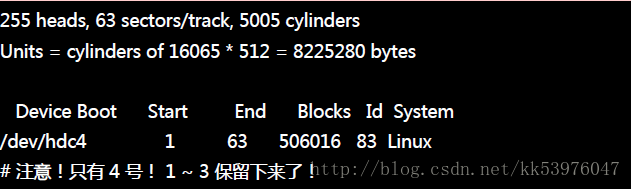
从上表我们可以发现几件事情:
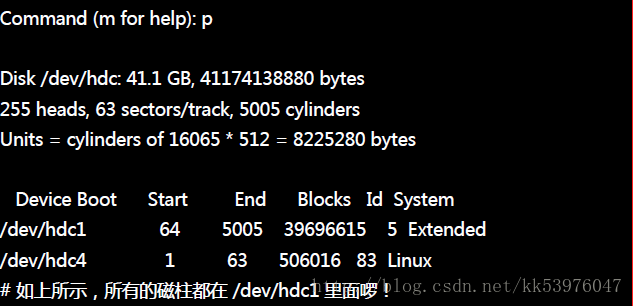
- 整部磁盘还可以进行额外的分割,因为最大磁柱为 5005 ,但只使用到 2052 号而已;
- /dev/hdc5 是由 /dev/hdc4 分割出来的,因为 /dev/hdc4 为 Extended,且 /dev/hdc5 磁柱号码在 /dev/hdc4 之内;
fdisk 还可以直接秀出系统内的所有 partition !举例来说,刚刚插入一个 USB 磁盘到这部 Linux 系统中, 那该如何观察 (1)这个磁盘的代号与 (2)这个磁盘的分割槽呢?
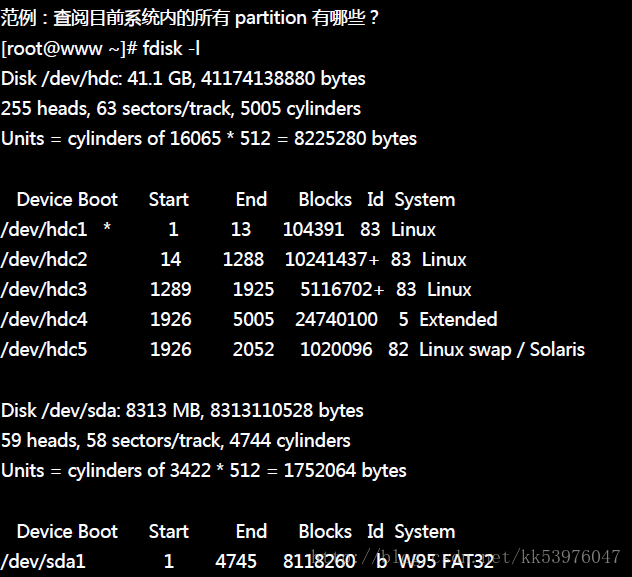
由上表的信息我们可以看到我有两颗磁盘,磁盘文件名为『/dev/hdc 与 /dev/sda』,/dev/hdc 已经在上面谈过了, 至于 /dev/sda 则有 8GB 左右的容量,且全部的磁柱都已经分割给 /dev/sda1 ,该文件系统应该为 Windows 的 FAT 文件系统。这样很容易查阅到分割方面的信息!
这个 fdisk 只有 root 才能执行,此外, 使用的『装置文件名』请不要加上数字,因为 partition 是针对『整个硬盘装置』而不是某个 partition !所以执行『 fdisk /dev/hdc1 』 就会发生错误!要使用 fdisk /dev/hdc 才对!那么我们知道可以利用 fdisk 来查阅硬盘的 partition 信息外,底下再来说一说进入 fdisk 之后的几个常做的工作!
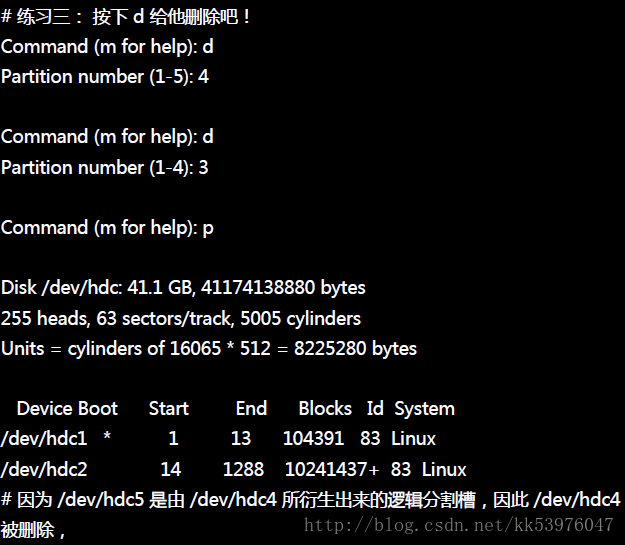
一、删除磁盘分区槽
如果你是按照鸟哥建议的方式去安装你的 CentOS ,那么你的磁盘应该会预留一块容量来做练习的。 实际练习新增硬盘之前,我们先来玩一玩恐怖的删除好了~如果想要测试一下如何将你的 /dev/hdc 全部的分割槽删除,应该怎么做?
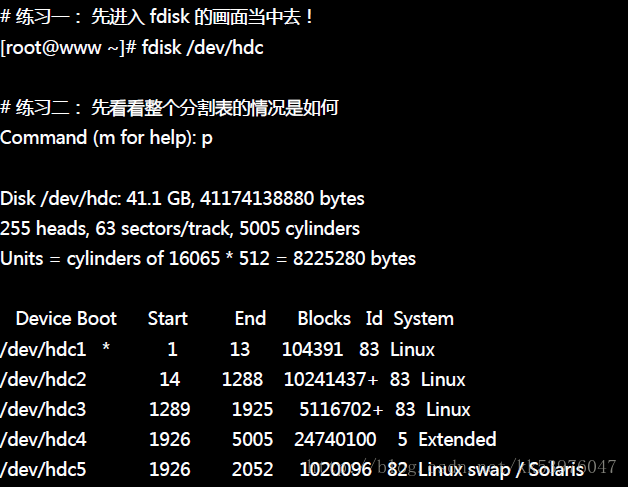
1. fdisk /dev/hdc :先进入 fdisk 画面;
2. p :先看一下分割槽的信息,假设要杀掉 /dev/hdc1;
3. d :这个时候会要你选择一个 partition ,就选 1 !
4. w (or) q :按 w 可储存到磁盘数据表中,并离开 fdisk ;当然, 如果你反悔了,直接按下 q 就可以取消刚刚的删除动作了!

二、练习新增磁盘分区槽
新增磁盘分区槽有好多种情况,因为新增 Primary / Extended / Logical 的显示结果都不太相同。 底下我们先将 /dev/hdc 全部删除成为干净未分割的磁盘,然后依序新增给大家!
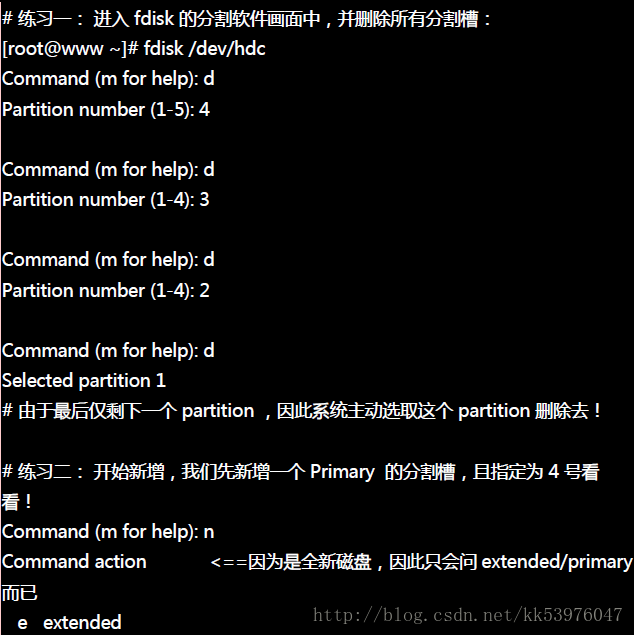
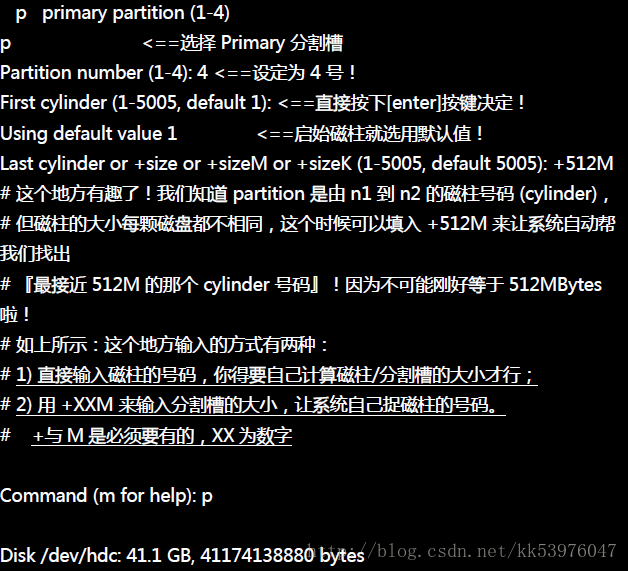
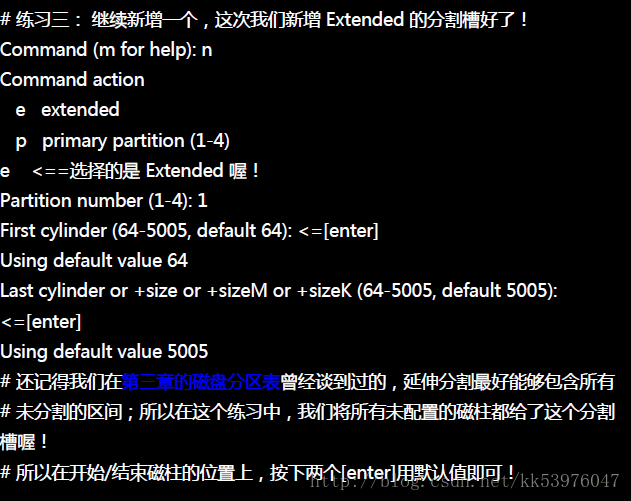

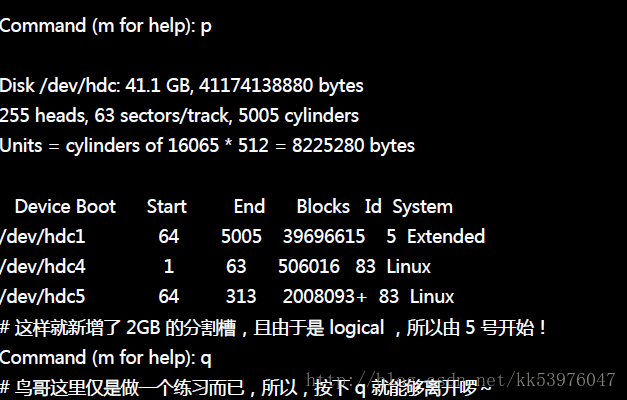
最重要的地方其实就在于建立分割槽的形式( primary/extended/logical )以及分割槽的大小了!一般来说建立分割槽的形式会有底下的数种状况:
- 1-4 号尚有剩余,且系统未有 extended: 此时会出现让你挑选 Primary / Extended 的项目,且你可以指定 1~4 号间的号码;
- 1-4 号尚有剩余,且系统有 extended: 此时会出现让你挑选 Primary / Logical 的项目;若选择 p 则你还需要指定 1~4 号间的号码; 若选择 l(L的小写) 则不需要设定号码,因为系统会自动指定逻辑分割槽的文件名号码;
- 1-4 没有剩余,且系统有 extended: 此时不会让你挑选分割槽类型,直接会进入 logical 的分割槽形式。
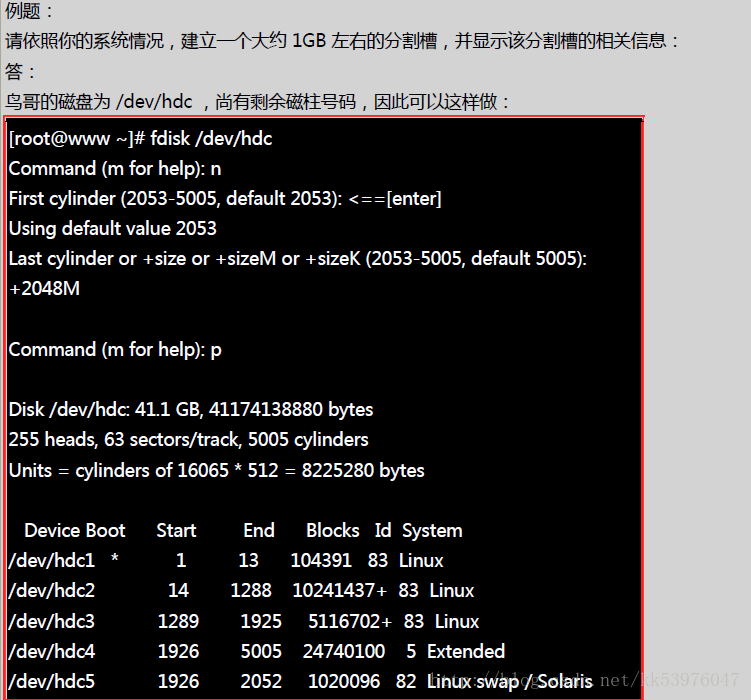
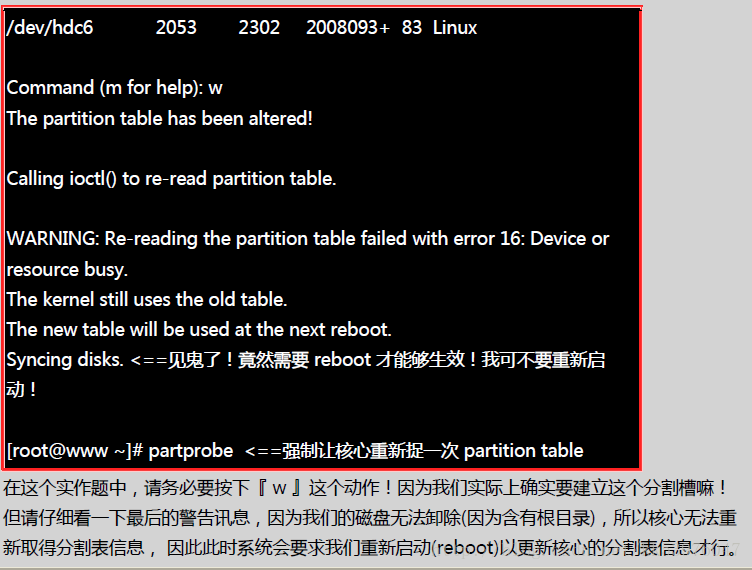
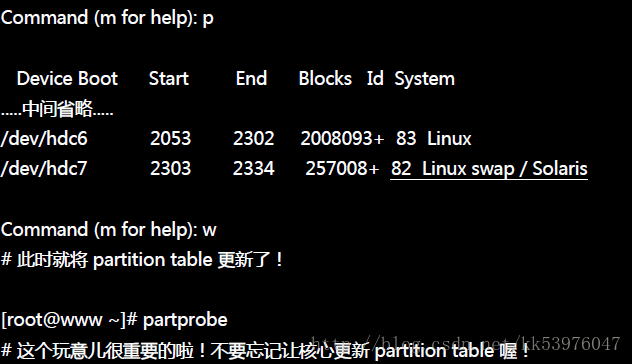
如上的练习中,最终写入分割表后竟然会让核心无法捉到分割表信息!此时你可以直接使用 reboot 来处理, 也可以使用 GNU 推出的工具程序来处置,那就是 partprobe 这个指令。这个指令的执行很简单, 他仅是告知核心必须要读取新的分割表而已,因此并不会在屏幕上出现任何信息才是! 这样一来,我们就不需要 reboot 啰!
三、操作环境的说明
以 root 的身份进行硬盘的 partition 时,最好是在单人维护模式底下比较安全一些, 此外,在进行 fdisk 的时候,如果该硬盘某个 partition 还在使用当中, 那么很有可能系统核心会无法重载硬盘的 partition table ,解决的方法就是将该使用中的 partition 给他卸除,然后再重新进入 fdisk 一遍,重新写入 partition table ,那么就可以成功!
四、注意事顷
另外在实作过程中请特别注意,因为 SATA 硬盘最多能够支持到 15 号的分割槽, IDE 则可以支持到 63 号。 但目前大家常见的系统都是 SATA 磁盘,因此在练习的时候千万不要让你的分割槽越过 15 号! 否则即使你还有剩余的磁柱容量,但还是会无法继续进行分割的!
另外需要特别留意的是,fdisk 没有办法处理大于 2TB 以上的磁盘分区槽 ! 这个问题比较严重!因为虽然 Ext3 文件系统已经支持达到 16TB 以上的磁盘,但是分割指令却无法支持。 时至今日(2009)所有的硬件价格大跌,硬盘也已经出到单颗 1TB 之谱,若加上磁盘阵列 (RAID) , 高于 2TB 的磁盘系统应该会很常见!此时你就得使用 parted 这个指令了!我们会在本章最后谈一谈这个指令的用法。
8.3.2. 磁盘格式化: mkfs, mke2fs
格式化就是『make filesystem, mkfs』!这个指令其实是个综合的指令,他会去呼叫正确的文件系统格式化工具软件!
一、mkfs


mkfs 其实是个综合指令而已,事实上如同上表所示,当我们使用『 mkfs -t ext3 …』时, 系统会去呼叫 mkfs.ext3 这个指令来进行格式化的动作!若如同上表所展现的结果, 那么这个系统支持的文件系统格式化工具有『cramfs, ext2, ext3, msdoc, vfat』等, 而最常用的应该是 ext3, vfat 两种! vfat 可以用在 Windows/Linux 共享的 USB 随身碟。

在格式化为 Ext3 的范例中,我们可以发现结果里面含有非常多的信息,由于我们没有详细指定文件系统的细部项目, 因此系统会使用默认值来进行格式化。其中比较重要的部分为:文件系统的标头(Label)、Block的大小以及 inode 的数量。 如果你要指定这些东西,就得要了解一下 Ext2/Ext3 的公用程序,亦即 mke2fs 这指令!
二、mke2fs

mke2fs 是一个很详细但是很麻烦的指令!因为里面的细部设定太多了!现在我们进行如下的假设:
- 这个文件系统的标头设定为:vbird_logical;
- 我的 block 指定为 2048 大小;
- 每 8192 bytes 分配一个 inode ;
- 建置为 journal 的 Ext3 文件系统。
开始格式化 /dev/hdc6 结果会变成如下所示:
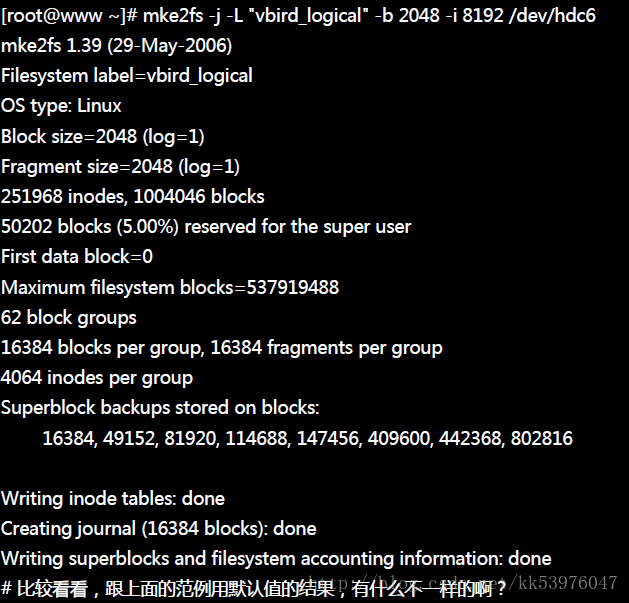
其实 mke2fs 所使用的各项选项/参数也可以用在『 mkfs -t ext3 … 』后面,因为最终使用的公用程序是相同的啦! 特别要注意的是 -b, -i 及 -j 这几个选项,尤其是 -j 这个选项,当没有指定 -j 的时候, mke2fs 使用 ext2 为格式化文件格式,若加入 -j 时,则格式化为 ext3 这个 Journaling 的 filesystem ! 如果没有特殊需求的话,使用『 mkfs -t ext3….』不但容易记忆,而且就非常好用!
8.3.3. 磁盘检验: fsck, badblocks
由于『当机』可能是难免的情况(不管是硬件还是软件)。 现在我们知道文件系统运作时会有硬盘与内存数据异步的状况发生,因此莫名其妙的当机非常可能导致文件系统的错乱。 此时就得拿 filesystem check, fsck 挽救啰。
一、 fsck

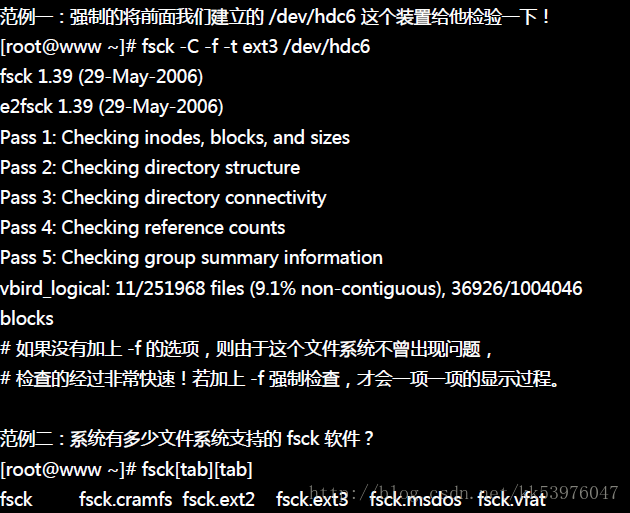
这是用来检查与修正文件系统错误的指令。注意:通常只有身为 root 且你的文件系统有问题的时候才使用这个指令,否则在正常状况下使用此一指令, 可能会造成对系统的危害 !通常使用这个指令的场合都是在系统出现极大的问题,导致你在 Linux 开机的时候得进入单人单机模式下进行维护的行为时,才必须使用此一指令!
另外,如果你怀疑刚刚格式化成功的硬盘有问题的时后,也可以使用 fsck 来检查一硬盘!其实就有点像是 Windows 的 scandisk !此外,由于 fsck 在扫瞄硬盘的时候,可能会造成部分 filesystem 的损坏,所以『执行 fsck 时, 被检查的partition 务必不可挂载到系统上!亦即是需要在卸除的状态!』
第六章的目录配置中提过, ext2/ext3 文件系统的最顶层(就是挂载点那个目录底下)会存在一个『lost+found』的目录! 该目录就是在当使用 fsck 检查文件系统后,若出现问题时,有问题的数据会被放置到这个目录中! 所以理论上这个目录不应该会有任何数据,若系统自动产生数据在里面,那就得特别注意你的文件系统了!
另外,系统实际执行的 fsck 指令,其实是呼叫 e2fsck 这个软件!可以 man e2fsck 找到更多的选项辅助!
二、 Badblocks

fsck 是用来检验文件系统是否出错,至于 badblocks 则是用来检查硬盘或软盘扇区有没有坏轨的指令! 由于这个指令其实可以透过『 mke2fs -c 装置文件名 』在进行格式化的时候处理磁盘表面的读取测试, 因此目前大多不使用这个指令!
8.3.4. 磁盘挂载与卸除: mount, umount
我们在本章一开始时的挂载点的意义当中提过挂载点是目录, 而这个目录是进入磁盘分区槽(其实是文件系统!)的入口就是了。不过要进行挂载前,最好先确定几件事:
- 单一文件系统不应该被重复挂载在不同的挂载点(目录)中;
- 单一目录不应该重复挂载多个文件系统;
- 要作为挂载点的目录,理论上应该都是空目录才是。
尤其是上述的后两点!如果你要用来挂载的目录里面并不是空的,那么挂载了文件系统之后,原目录下的东西就会暂时的消失。 举个例子来说,假设你的 /home 原本与根目录 (/) 在同一个文件系统中,底下原本就有 /home/test 与 /home/vbird 两个目录。然后你想要加入新的硬盘,并且直接挂载 /home 底下,那么当你挂载上新的分割槽时,则 /home 目录显示的是新分割槽内的资料,至于原先的 test 与 vbird 这两个目录就会暂时的被隐藏掉了!注意!并不是被覆盖掉, 而是暂时的隐藏了起来,等到新分割槽被卸除之后,则 /home 原本的内容就会再次的跑出来! 而要将文件系统挂载到我们的 Linux 系统上,就要使用 mount 这个指令! 不过,这个指令真的是博大精深!我们学简单一点。



事实上 mount 是个很万用的指令,他可以挂载 ext3/vfat/nfs 等文件系统,由于每种文件系统的数据并不相同, 详细的参数与选项自然也就不相同!不过实际应用时却很简单!
一、挂载Ext2/Ext3文件系统
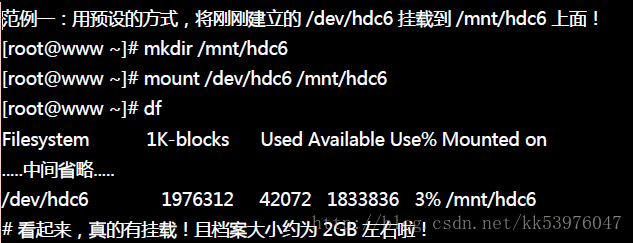
利用『mount 装置文件名 挂载点』就能够顺利的挂载了!由于文件系统几乎都有 superblock , 我们的 Linux 可以透过分析 superblock 搭配 Linux 自己的驱动程序去测试挂载, 如果成功的套和了,就立刻自动的使用该类型的文件系统挂载起来! 那么系统有没有指定哪些类型的 filesystem 才需要进行上述的挂载测试呢? 主要是参考底下这两个档案:
- /etc/filesystems:系统指定的测试挂载文件系统类型;
- /proc/filesystems:Linux系统已经加载的文件系统类型。
那我怎么知道我的 Linux 有没有相关文件系统类型的驱动程序呢?我们 Linux 支持的文件系统之驱动程序都写在如下的目录中: /lib/modules/$(uname -r)/kernel/fs/
例如 vfat 的驱动程序就写在『/lib/modules/$(uname -r)/kernel/fs/vfat/』这个目录下! 简单的测试挂载后,接下来让我们检查看看目前已挂载的文件系统状况!

这个指令输出的结果可以让我们看到非常多信息,以 /dev/hdc2 这个装置来说好了(上面表格的第一行), 他的意义是:『/dev/hdc2 是挂载到 / 目录,文件系统类型为 ext3 ,且挂载为可擦写 (rw) ,另外,这个 filesystem 有标头,名字(label)为 /1 』 。 接下来请拿出你的 CentOS DVD 放入光驱中,并拿 FAT 格式的 USB 随身碟(不要用 NTFS 的)插入 USB 插槽中,我们来测试挂载一下!
二、挂载 CD 或 DVD 光盘
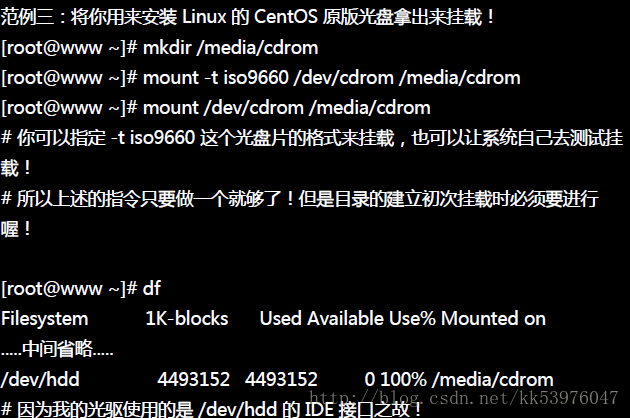
光驱一挂载之后就无法退出光盘片了!除非你将他卸除才能够退出! 从上面的数据你也可以发现,因为是光盘所以磁盘使用率达到 100% ,因为你无法直接写入任何数据到光盘当中ㄇㄟ! 另外,其实 /dev/cdrom 是个链接文件,正确的磁盘文件名得要看你的光驱是什么连接接口的环境。 以鸟哥为例,我的光驱接在 /dev/hdd,所以正确的挂载应该是『mount /dev/hdd /media/cdrom』比较正确!
三、格式化与挂载软盘
软盘的格式化可以直接使用 mkfs 即可。但是软盘也是可以格式化成为 ext3 或vfat 格式的。 挂载的时候我们同样的使用系统自动测试挂载即可!请先放置到软盘驱动器当中!底下来测试看看(软盘片请勿放置任何数据,且将写保护打开!)。
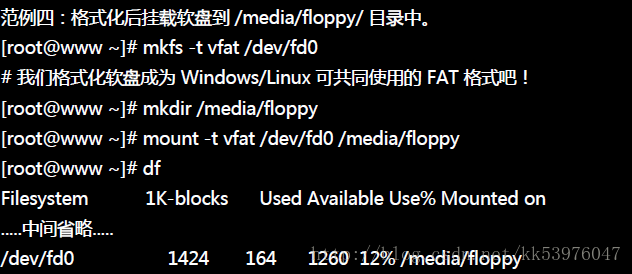
与光驱不同的是,你挂载了软盘后竟然还是可以退出软盘!整个 Linux 最重要的就是文件系统,而文件系统是直接挂载到目录树上头, 几乎任何指令都会或多或少使用到目录树的数据,因此你当然不可以随意的将光盘/软盘拿出来! 所以,软盘也请卸除之后再退出!很重要的一点!
四、挂载随身碟
请拿出你的随身碟(不能够是 NTFS 的文件系统)并插入 Linux 主机的 USB 槽中!
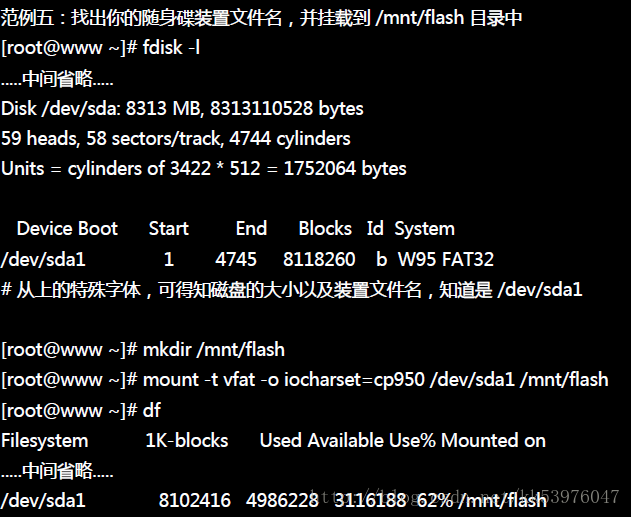
如果带有中文文件名的数据,那么可以在挂载时指定一下挂载文件系统所使用的语系数据。 在 man mount 找到 vfat 文件格式当中可以使用 iocharset 来指定语系,而中文语系是 cp950 , 所以也就有了上述的挂载指令项目。
万一你使用的是随身硬盘,也就是利用笔记本电脑所做出来的USB磁盘时,通常这样的硬盘都使用 NTFS 格式的,可以参考底下这个网站:(注8)
- NTFS 文件系统官网:Linux-NTFS Project: http://www.linux-ntfs.org/
- CentOS 5.x 版的相关驱动程序下载页面:http://www.linux-ntfs.org/doku.php?id=redhat:rhel5
将她们提供的驱动程序捉下来并且安装之后,就能够使用 NTFS 的文件系统了! 只是由于文件系统与 Linux 核心有很大的关系,因此以后如果你的 Linux 系统有升级 (update) 时, 你就得要重新下载一次相对应的驱动程序版本!
五、重新挂载根目录与挂载不特定目录
整个目录树最重要的地方就是根目录了,所以根目录根本就不能够被卸除的!如果你的挂载参数要改变, 或者是根目录出现『只读』状态时,如何重新挂载呢?最可能的处理方式就是重新启动 (reboot) ! 不过你也可以这样做:

重点是那个『 -o remount,xx 』的选项与参数!请注意,要重新挂载 (remount) 时, 这是个非常重要的机制!尤其是当你进入单人维护模式时,你的根目录常会被系统挂载为只读,这个时候这个指令就太重要了!
另外,我们也可以利用 mount 来将某个目录挂载到另外一个目录去!这并不是挂载文件系统,而是额外挂载某个目录的方法! 虽然底下的方法也可以使用 symbolic link 来连结,不过在某些不支持符号链接的程序运作中,还是得要透过这样的方法才行。

看起来,其实两者连结到同一个 inode !透过这个 mount –bind 的功能, 您可以将某个目录挂载到其他目录去!而并不是整块 filesystem 的!所以从此进入 /mnt/home 就是进入 /home 的意思!
六、umount (将装置档案卸除)

就是直接将已挂载的文件系统给他卸除即是!卸除之后,可以使用 df 或 mount -l 看看是否还存在目录树中? 卸除的方式,可以下达装置文件名或挂载点,均可接受!
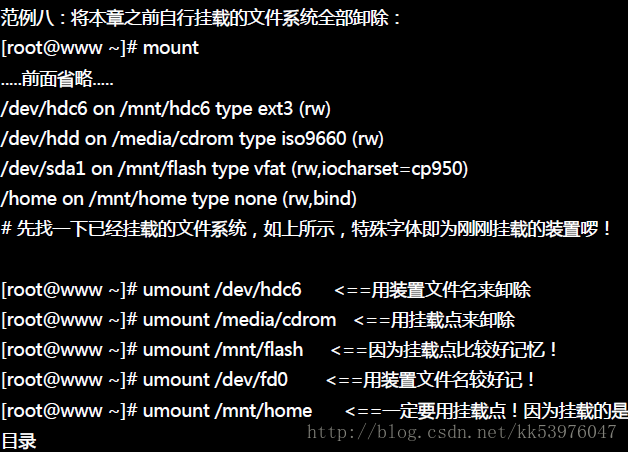
由于通通卸除了,此时你才可以退出光盘片、软盘片、USB随身碟等设备!如果你遇到这样的情况:

由于你目前正在 /media/cdrom/ 的目录内,也就是说其实『你正在使用该文件系统』的意思! 所以自然无法卸除这个装置!就『离开该文件系统的挂载点』即可。以上述的案例来说, 你可以使用『 cd / 』回到根目录,就能够卸除 /media/cdrom !
七、使用 Label name 进行挂载的方法
除了磁盘的装置文件名之外,其实我们可以使用文件系统的标头(label)名称来挂载! 举例来说,我们刚刚卸除的 /dev/hdc6 标头名称是『vbird_logical』,你也可以使用 dumpe2fs 这个指令来查询一下!然后就这样做即可:

这种挂载的方法有一个很大的好处:『系统不必知道该文件系统所在的接口与磁盘文件名!』 更详细的说明我们会在下一小节当中的 e2label 介绍的!
8.3.5. 磁盘参数修订: mknod, e2label, tune2fs, hdparm
某些时刻,你可能会希望修改一下目前文件系统的一些相关信息,举例来说,你可能要修改 Label name , 或者是 journal 的参数,或者是其他硬盘运作时的相关参数 (例如 DMA 启动与否~)。 这个时候,就得需要底下这些相关的指令功能。
一、mknod
还记得我们说过,在 Linux 底下所有的装置都以档案来代表吧!但是那个档案如何代表该装置呢?就是透过档案的 major 与 minor 数值来替代的~所以,那个 major 与 minor 数值是有特殊意义的!举例来说,在这个测试机当中, 那个用到的磁盘 /dev/hdc 的相关装置代码如下:
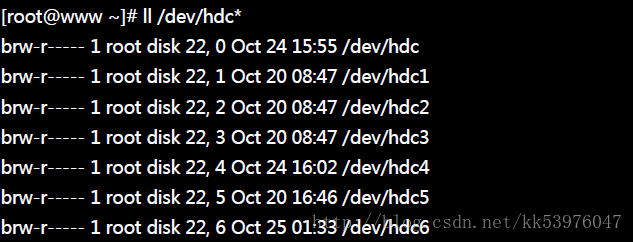
上表当中 22 为主要装置代码 (Major) 而 0~6 则为次要装置代码 (Minor)。 我们的 Linux 核心认识的装置数据就是透过这两个数值来决定的!举例来说,常见的硬盘文件名 /dev/hda 与 /dev/sda 装置代码如下所示:
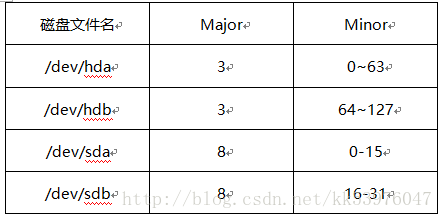
如果你想要知道更多核心支持的硬件装置代码 (major, minor) 请参考官网的连结(注9):
http://www.kernel.org/pub/linux/docs/device-list/devices.txt
基本上,Linux 核心 2.6 版以后,硬件文件名已经都可以被系统自动的实时产生了,我们根本不需要启动建立装置档案。 不过某些情况底下我们可能还是得要启动处理装置档案的,例如在某些服务被关到特定目录下时(chroot), 就需要这样做了。此时这个 mknod 就得要知道如何操作才行!
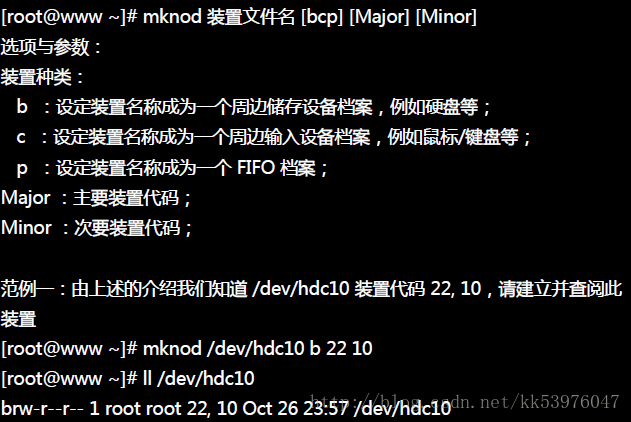

二、e2label
我们在 mkfs 指令介绍时有谈到设定文件系统标头 (Label) 的方法。 修改标头就用这个 e2label 了。那什么是 Label 呢? 我们拿你曾用过的 Windows 系统来说明。当你打开『档案总管』时,C/D等槽不是都会有个名称吗? 那就是 label (如果没有设定名称,就会显示『本机磁盘驱动器』的字样) 这个东西除了有趣且可以让你知道磁盘的内容是啥玩意儿之外,也会被使用到一些配置文件案当中! 举例来说,刚刚我们聊到的磁盘的挂载时,不就有用到 Label name 来进行挂载吗? 目前 CentOS 的配置文件,也就是那个 /etc/fstab 档案的设定都预设使用 Label name ! 那这样做有什么好处与缺点呢?
- 优点:不论磁盘文件名怎么变,不论你将硬盘插在那个 IDE / SATA 接口,由于系统是透过 Label ,所以,磁盘插在哪个接口将不会有影响;
- 缺点:如果插了两颗硬盘,刚好两颗硬盘的 Label 有重复的,那就惨了~ 因为系统可能会无法判断哪个磁盘分区槽才是正确的!
鸟哥一直是个比较『硬派』作风,所以我还是比较喜欢直接利用磁盘文件名来挂载! 不过,如果没有特殊需求的话,那么利用 Label 来挂载也成! 但是你就不可以随意修改 Label 的名称了 !

三、tune2fs


这个指令的功能其实很广泛,上面仅列出很简单的一些参数而已, 更多的用法请自行参考 man tune2fs 。比较有趣的是,如果你的某个 partition 原本是 ext2 的文件系统,如果想要将他更新成为 ext3 文件系统的话,利用 tune2fs 就可以很简单的转换过来。
四、hdparm
如果你的硬盘是 IDE 接口的,那么这个指令可以帮助你设定一些进阶参数!如果你是使用 SATA 接口的, 那么这个指令就没有多大用途了!另外,目前的 Linux 系统都已经稍微优化过,所以这个指令最多是用来测试效能! 而且建议你不要随便调整硬盘参数,文件系统容易出问题!除非你真的知道你调整的数据是啥!

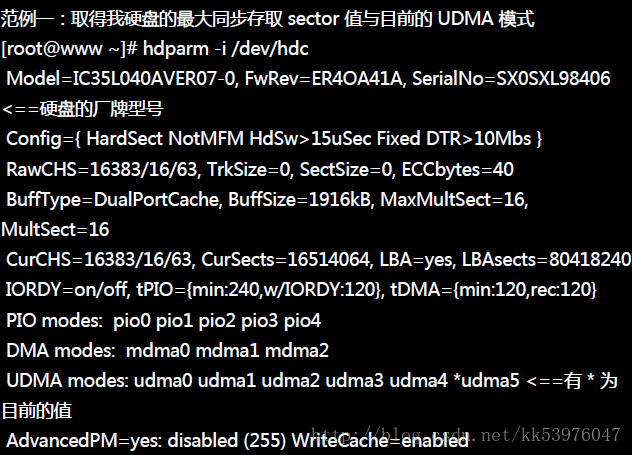
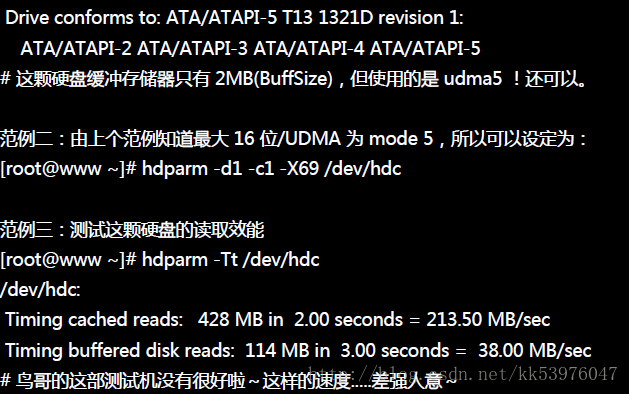
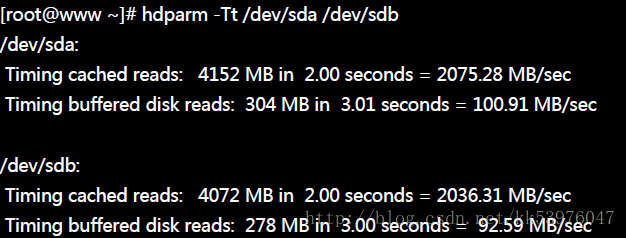
如果你是使用 SATA 硬盘的话,这个指令唯一可以做的,就是最后面那个测试的功能而已! 虽然这样的测试不是很准确,至少是一个可以比较的基准。鸟哥在我的cluster 机器上面测试的 SATA (/dev/sda) 与 RAID (/dev/sdb) 结果如下,可以提供给你参考看看。
8.4. 设定开机挂载:
手动处理 mount 不是很人性化,我们总是需要让系统『自动』在开机时进行挂载的!本小节就是在谈这玩意儿! 另外,从 FTP 服务器捉下来的映像档能否不用刻录就可以读取内容?我们也需要谈谈先!
8.4.1. 开机挂载 /etc/fstab 及 /etc/mtab
要想在开机的时候直接挂载那就直接到 /etc/fstab 里面去修修就行!不过,在开始说明前,这里要先跟大家说一说系统挂载的一些限制:
- 根目录 / 是必须挂载的﹐而且一定要先于其它 mount point 被挂载进来。
- 其它 mount point 必须为已建立的目录﹐可任意指定﹐但一定要遵守必须的系统目录架构原则 ;
- 所有 mount point 在同一时间之内﹐只能挂载一次。
- 所有 partition 在同一时间之内﹐只能挂载一次。
- 如若进行卸除﹐您必须先将工作目录移到 mount point(及其子目录) 之外。
让我们直接查阅一下 /etc/fstab 这个档案的内容吧!
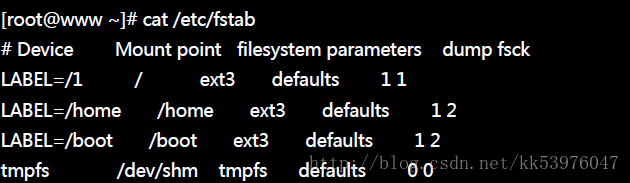
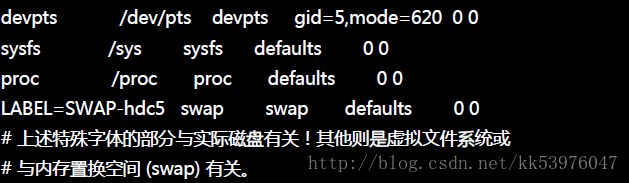
其实 /etc/fstab (filesystem table) 就是将我们利用 mount 指令进行挂载时, 将所有的选项与参数写入到这个档案中就是了。除此之外, /etc/fstab 还加入了 dump 这个备份用指令的支持! 与开机时是否进行文件系统检验 fsck 等指令有关。 这个档案的内容共有六个字段,这六个字段非常的重要!你『一定要背起来』才好! 各个字段的详细数据如下:
第一栏:磁盘装置文件名或该装置的 Label:
这个字段请填入文件系统的装置文件名。但是由上面表格的默认值我们知道系统默认使用的是 Label 名称! 在鸟哥的这个测试系统中 /dev/hdc2 标头名称为 /1,所以上述表格中的『LABEL=/1』也可以被取代成为『/dev/hdc2』的意思。 至于Label可以使用 dumpe2fs 指令来查阅的。
第二栏:挂载点 (mount point)::
就是挂载点?一定是目录!
第三栏:磁盘分区槽的文件系统:
在启动挂载时可以让系统自动测试挂载,但在这个档案当中我们必须要启动写入文件系统才行! 包括 ext3, reiserfs, nfs, vfat 等等。
第四栏:文件系统参数:
记不记得我们在 mount 这个指令中谈到很多特殊的文件系统参数? 还有我们使用过的『-o iocharset=cp950』?这些特殊的参数就是写入在这个字段! 虽然之前在 mount 已经提过一次,这里我们利用表格的方式再汇整一下:

第五栏:能否被 dump 备份指令作用:
dump 是一个用来做为备份的指令(我们会在第二十五章备份策略中谈到这个指令), 我们可以透过 fstab 指定哪个文件系统必须要进行 dump 备份! 0 代表不要做 dump 备份, 1 代表要每天进行 dump 的动作。 2 也代表其他不定日期的 dump 备份动作, 通常这个数值不是 0 就是 1 啦!
第六栏:是否以 fsck 检验扇区:
开机的过程中,系统默认会以 fsck 检验我们的 filesystem 是否完整 (clean)。 不过,某些 filesystem 是不需要检验的,例如内存置换空间 (swap) ,或者是特殊文件系统例如 /proc 与 /sys 等等。所以,在这个字段中,我们可以设定是否要以 fsck 检验该 filesystem 。 0 是不要检验, 1 表示最早检验(一般只有根目录会设定为 1), 2 也是要检验,不过 1 会比较早被检验! 一般来说,根目录设定为 1 ,其他的要检验的 filesystem 都设定为 2 就好了。
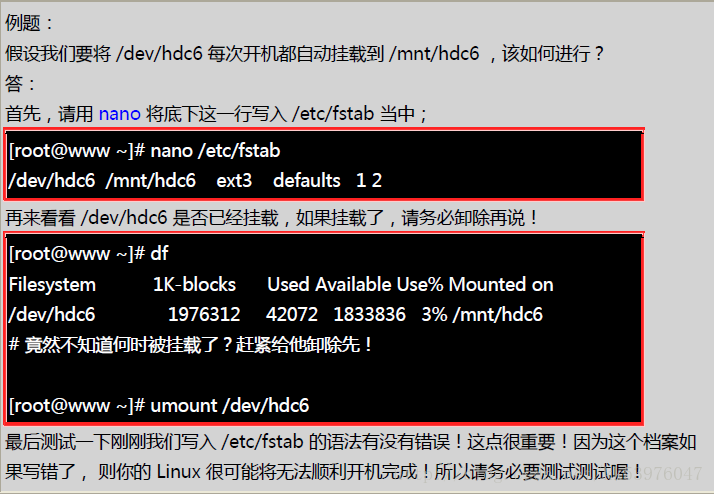
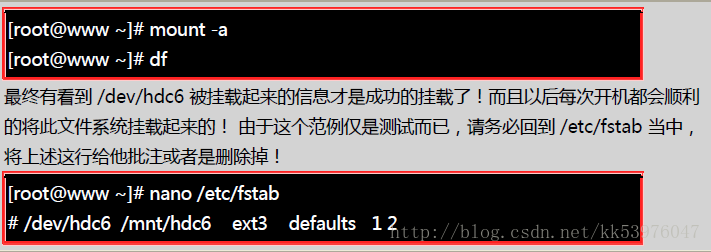
/etc/fstab 是开机时的配置文件,不过,实际 filesystem 的挂载是记录到 /etc/mtab 与 /proc/mounts 这两个档案当中的。每次我们在更动 filesystem 的挂载时,也会同时更动这两个档案!但是,万一发生您在 /etc/fstab 输入的数据错误,导致无法顺利开机成功,而进入单人维护模式当中,那时候的 / 可是 read only 的状态,当然您就无法修改 /etc/fstab ,也无法更新 /etc/mtab ,那怎么办? 可以利用底下这一招:

8.4.2. 特殊装置 loop 挂载(映象档不刻录就挂载使用)
一、挂载光盘/DVD映象文件
想象一下如果今天我们从国家高速网络中心(http://ftp.twaren.net)或者是义守大学(http://ftp.isu.edu.tw)下载了 Linux 或者是其他所需光盘/DVD的映像文件后, 难道一定需要刻录成为光盘才能够使用该档案里面的数据吗?当然不是!我们可以透过 loop 装置来挂载的! 那要如何挂载呢?鸟哥将整个 CentOS 5.2 的 DVD 映像档捉到测试机上面,然后利用这个档案来挂载给大家参考看看!
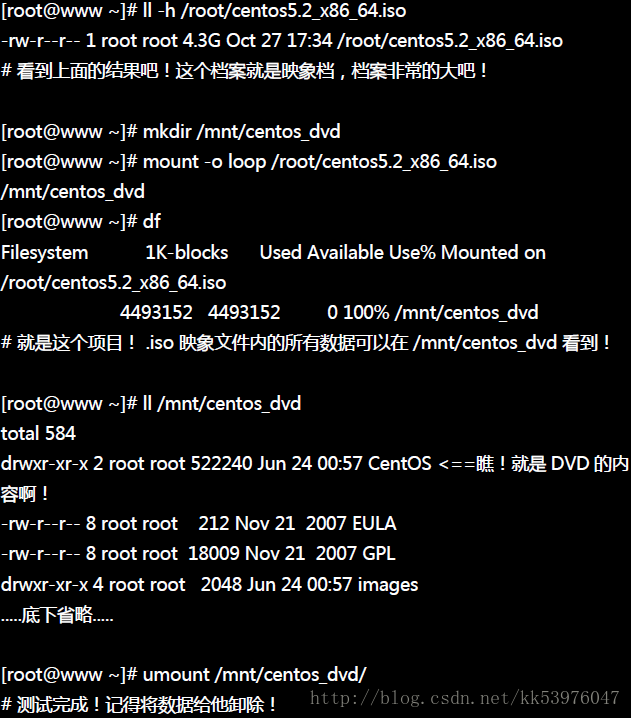
你也可以在这个档案内『动手脚』去修改档案的!这也是为什么很多映像档提供后,还得要提供验证码 (MD5) 给使用者确认该映像档没有问题!
二、 建立大档案以制作 loop 装置档案
那么我能不能制作出一个大档案,然后将这个文件格式化后挂载呢? 好问题!举例来说,如果当初在分割时, 你只有分割出一个根目录,假设你已经没有多余的容量可以进行额外的分割的!偏偏根目录的容量还很大! 此时你就能够制作出一个大档案,然后将这个档案挂载!如此一来感觉上你就多了一个分割槽! 用途非常的广泛!
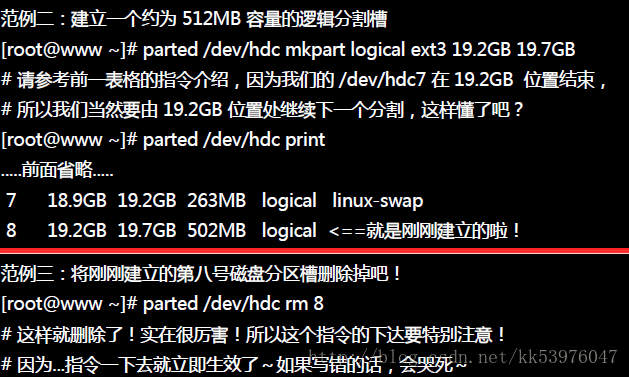
底下我们在 /home 下建立一个 512MB 左右的大档案,然后将这个大文件格式化并且实际挂载来玩一玩!
1.建立大型档案
怎么建立这个大档案呢?在 Linux 底下我们有一支很好用的程序 dd !他可以用来建立空的档案!详细的说明请先翻到下一章 压缩指令的运用来查阅,这里仅作一个简单的范例而已。 假设我要建立一个空的档案在 /home/loopdev ,那可以这样做:
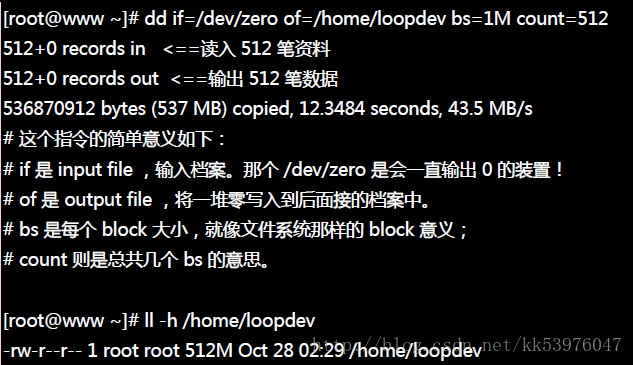
dd 就好像在迭砖块一样,将 512 块,每块 1MB 的砖块堆栈成为一个大档案 (/home/loopdev) ! 最终就会出现一个 512MB 的档案!
2.格式化
很简单就建立起一个 512MB 的档案了!接下来当然是格式化!


3.挂载
利用 mount 的特殊参数,那个 -o loop 的参数来处理!

透过这个简单的方法,感觉上你就可以在原本的分割槽在不更动原有的环境下制作出你想要的分割槽就是了! 这东西很好用的!尤其是想要玩 Linux 上面的『虚拟机』的话, 也就是以一部 Linux 主机再切割成为数个独立的主机系统时,类似 VMware 这类的软件, 在 Linux 上使用 xen 这个软件,他就可以配合这种 loop device 的文件类型来进行根目录的挂载!
8.5. 内存置换空间(swap)之建置
安装时一定需要的两个 partition ! 一个是根目录,另外一个就是 swap(内存置换空间)。关于内存置换空间的解释在第四章安装 Linux 内的磁盘分区时有约略提过, swap 的功能就是在应付物理内存不足的情况下所造成的内存延伸记录的功能。
一般来说,如果硬件的配备足够的话,那么 swap 应该不会被我们的系统所使用到, swap 会被利用到的时刻通常就是物理内存不足的情况了。从第零章的计算器概论当中,我们知道 CPU 所读取的数据都来自于内存, 那当内存不足的时候,为了让后续的程序可以顺利的运作,因此在内存中暂不使用的程序与数据就会被挪到 swap 中了。 此时内存就会空出来给需要执行的程序加载。由于 swap 是用硬盘来暂时放置内存中的信息, 所以用到 swap 时,你的主机硬盘灯就会开始闪个不停!
虽然目前(2009)主机的内存都很大,至少都有 1GB 以上!因此在个人使用上你不要设定 swap 应该也没有什么太大的问题。 不过服务器可就不这么想。由于你不会知道何时会有大量来自网络的要求,因此你最好能够预留一些 swap 来缓冲一下系统的内存用量! 至少达到『备而不用』的地步! 现在想象一个情况,你已经将系统建立起来了,此时却才发现你没有建置 swap , 透过本章上面谈到的方法,你可以使用如下的方式来建立你的 swap !
- 设定一个 swap partition
- 建立一个虚拟内存的档案
8.5.1. 使用实体分割槽建置swap
建立 swap 分割槽的方式透过底下几个步骤就搞定:
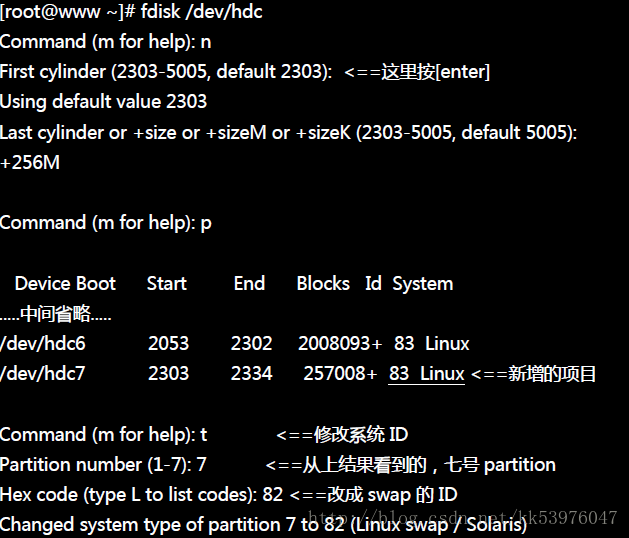
1. 分割:先使用 fdisk 在你的磁盘中分割中一个分割槽给系统作为 swap 。由于Linux 的 fdisk 预设会将分割槽的 ID 设定为 Linux 的文件系统,所以你可能还得要设定一下 system ID 就是了。
2. 格式化:利用建立 swap 格式的『mkswap 装置文件名』就能够格式化该分割槽成为 swap 格式;
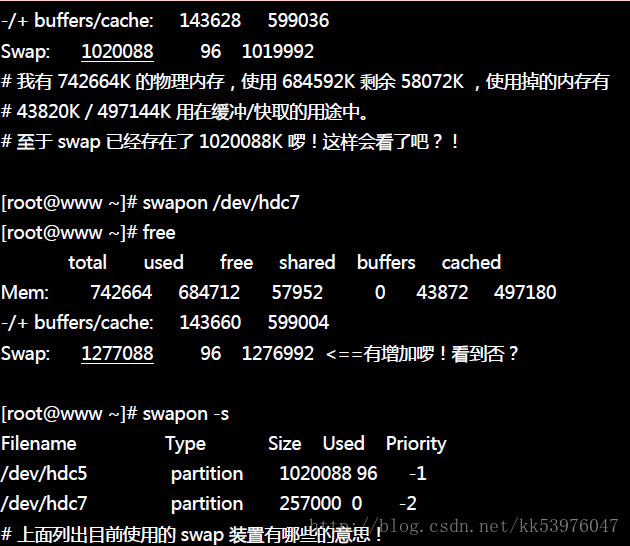
3. 使用:最后将该 swap 装置启动,方法为:『swapon 装置文件名』。
4. 观察:最终透过 free 这个指令来观察一下内存的用量!
既然我们还有多余的磁盘容量可以分割,那么让我们继续分割出 256MB 的磁盘分区槽! 然后将这个磁盘分区槽做成 swap !
先进行分割的行为!
开始建置 swap 格式
开始观察与加载看看!


8.5.2. 使用档案建置swap
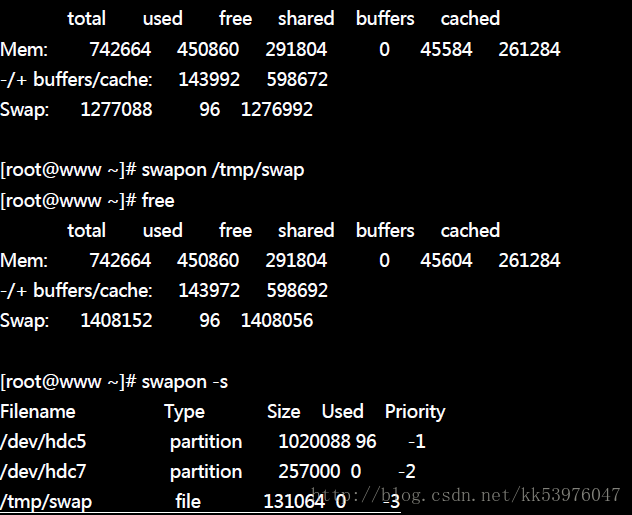
如果是在实体分割槽无法支持的环境下,此时前一小节提到的 loop 装置建置方法就派的上用场! 与实体分割槽不一样的只是利用 dd 去建置一个大档案而已。透过档案建置的方法建立一个 128 MB 的内存置换空间!
1.使用 dd 这个指令来新增一个 128MB 的档案在 /tmp 底下:

这样一个 128MB 的档案就建置妥当。
2.使用 mkswap 将 /tmp/swap 这个文件格式化为 swap 的文件格式:

3.使用 swapon 来将 /tmp/swap 启动!

4.使用 swapoff 关掉 swap file
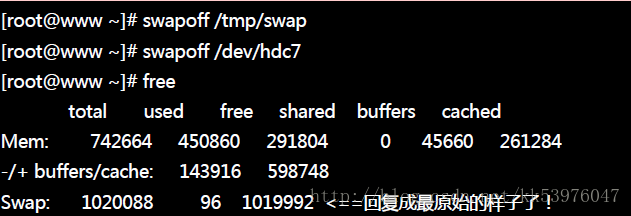
8.5.3. swap使用上的限制
因为目前的 x86 主机所含的内存实在都太大了 (一般入门级至少也都有 512MB 了),所以,我们的 Linux 系统大概都用不到 swap 这个玩意儿的。不过, 如果是针对服务器者或是工作站这些常年上线的系统来说的话,那么swap 还是需要建立的。
因为 swap 主要的功能是当物理内存不够时,则某些在内存当中所占的程序会暂时被移动到 swap 当中,让物理内存可以被需要的程序来使用。另外,如果你的主机支持电源管理模式, 也就是说,你的 Linux 主机系统可以进入『休眠』模式的话,那么, 运作当中的程序状态则会被纪录到 swap 去,以作为『唤醒』主机的状态依据! 另外,有某些程序在运作时,本来就会利用 swap 的特性来存放一些数据段, 所以, swap 来是需要建立的!只是不需要太大!
不过, swap 在被建立时,是有限制的!
- 在核心 2.4.10 版本以后,单一 swap 量已经没有 2GB 的限制了,
- 但是,最多还是仅能建立到 32 个 swap 的数量!
- 而且,由于目前 x86_64 (64位) 最大内存寻址到 64GB, 因此, swap 总量最大也是仅能达 64GB 就是了!
8.6. 文件系统的特殊观察与操作
文件系统实在是非常有趣的东西,鸟哥学了好几年还是很多东西不很懂! 在学习的过程中很多朋友在讨论区都有提供一些想法!这些想法将他归纳起来有底下几点可以参考的数据!
8.6.1. boot sector 与 superblock 的关系
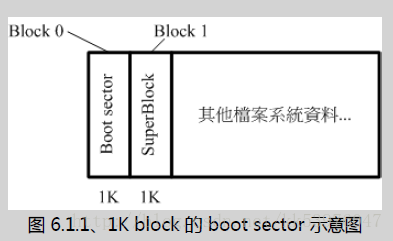
在过去非常多的文章都写到开机管理程序是安装到 superblock 内的,但是我们由官方的 How to 文件知道,图解(图 1.3.1)的结果是将可安装开机信息的 boot sector (启动扇区) 独立出来,并非放置到 superblock 当中的 ! 那么也就是说过去的文章写错了?这其实还是可以讨论讨论的!
经过一些搜寻,鸟哥找到几篇文章(非官方文件)的说明,大多是网友分析的结果!如下所示:(注10)
- The Second Extended File System:http://www.nongnu.org/ext2-doc/ext2.html
- Rob’s ext2 documentation: http://www.landley.net/code/toybox/ext2.html
- Life is different blog: ext2文件系统分析: http://www.qdhedu.com/blog/post/7.html
这几篇文章有几个重点,归纳一下如下:
- superblock 的大小为 1024 bytes;
- superblock 前面需要保留 1024 bytes 下来,以让开机管理程序可以安装。
分析上述两点我们知道 boot sector 应该会占有 1024 bytes 的大小吧!但是整个文件系统主要是依据 block 大小来决定的啊! 因此要讨论 boot sector 与 superblock 的关系时,不得不将 block 的大小拿出来讨论讨论!
一、block 为 1024 bytes (1K) 时:
如果 block 大小刚好是 1024 的话,那么 boot sector 与 superblock 各会占用掉一个 block , 所以整个文件系统图示就会如同图 1.3.1 所显示的那样,boot sector 是独立于 superblock 外面的! 由于鸟哥在基础篇安装的环境中有个 /boot 的独立文件系统在 /dev/hdc1 中,使用 dumpe2fs 观察的结果有点像底下这样(如果你是按照鸟哥的教学安装你的 CentOS 时,可以发现相同的情况!):
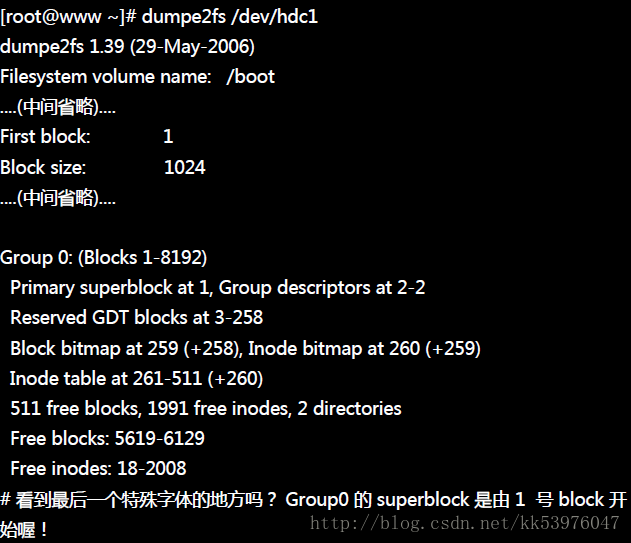
由上表我们可以确实的发现 0 号 block 是保留下来的,那就是留给 boot sector 用的! 所以整个分割槽的文件系统分区有点像底下这样的图示:
二、block 大于 1024 bytes (2K, 4K) 时:
如果 block 大于 1024 的话,那么 superblock 将会在 0 号!我们撷取本章一开始介绍 dumpe2fs 时的内容来说明一下好了!
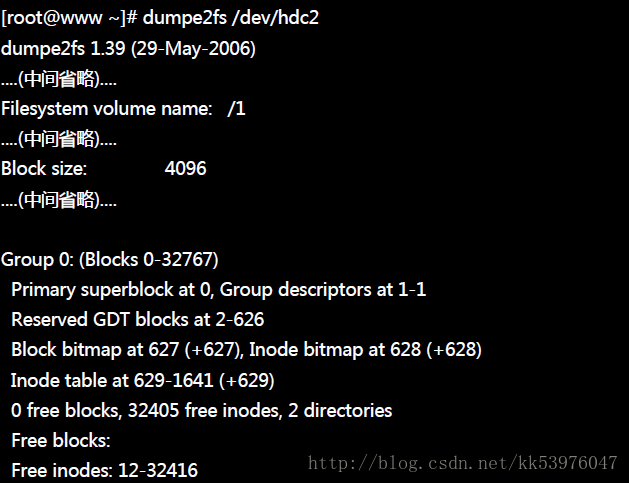
我们可以发现 superblock 就在第一个 block (第 0 号) 上头!但是 superblock 其实就只有 1024bytes 嘛! 为了怕浪费更多空间,因此第一个 block 内就含有 boot sector 与 superblock 两者 !举上头的表格来说,因为每个 block 占有 4K ,因此在第一个 block 内 superblock 仅占有 1024-2047 ( 由 0 号起算的话)之间的咚咚,至于 2048bytes 以后的空间就真的是保留!而 0-1023 就保留给 boot sector 来使用。
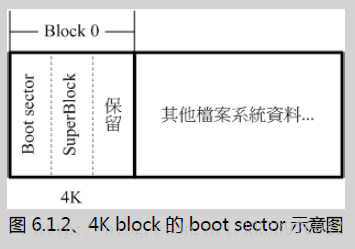
因为上述的情况,如果在比较大的 block 尺寸(size)中,我们可能可以说你能够将开机管理程序安装到 superblock 所在的 block 号码中!就是上表的 0 号!但事实上还是安装到 boot sector 的保留区域中!所以说, 以前的文章说开机管理程序可以安装到 superblock 内也不能算全错。但比较正确的说法,应该是安装到该 filesystem 最前面的 1024 bytes 内的区域,就是 boot sector 这样比较好!
8.6.2. 磁盘空间之浪费问题
我们在前面的 block 介绍中谈到了一个 block 只能放置一个档案, 因此太多小档案将会浪费非常多的磁盘容量。但你有没有注意到,整个文件系统中包括 superblock, inode table 与其他中介数据等其实都会浪费磁盘容量!所以当我们在 /dev/hdc6 建立起 ext3 文件系统时, 一挂载就立刻有很多容量被用掉了!
另外,不知道你有没有发现到,当你使用 ls -l 去查询某个目录下的数据时,第一行都会出现一个『total』的字样!其实那就是该目录下的所有数据所耗用的实际 block 数量 * block 大小的值。 我们可以透过 ll -s 来观察看看上述的意义:
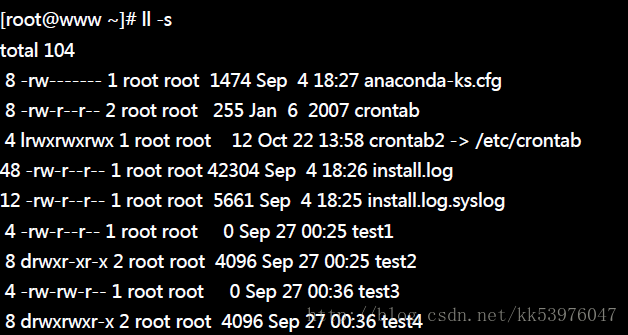
从上面的特殊字体部分,那就是每个档案所使用掉 block 的容量!举例来说,那个 crontab 虽然仅有 255bytes , 不过他却占用了两个 block (每个 block 为 4K),将所有的 block 加总就得到 104Kbytes 那个数值了。 如果计算每个档案实际容量的加总结果,其实只有 56.5K 而已,这样就耗费掉好多容量了!
如果想要查询某个目录所耗用的所有容量时,那就使用 du !不过 du 如果加上 -s 这个选项时, 还可以依据不同的规范去找出文件系统所消耗的容量!举例来说,我们就来看看 /etc/ 这个目录的容量状态!
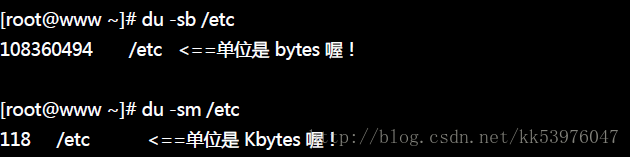
使用 bytes 去分析时,发现到实际的数据占用约 103.3Mbytes,但是使用 block 去测试,就发现其实耗用了 118Mbytes, 此时文件系统就耗费了约 15Mbytes !
8.6.3. 利用 GNU 的 parted 进行分割行为
虽然你可以使用 fdisk 很看快速的将你的分割槽切割妥当,不过 fdisk 却无法支持到高于 2TB 以上的分割槽! 此时就得需要 parted 来处理了。不要觉得 2TB 你用不着! 2009 年已经有单颗硬盘高达 2TB 与容量了! 如果再搭配主机系统有内建磁盘阵列装置,要使用数个 TB 的单一磁盘装置也不是不可能的! 所以,还是得要学一下这个重要的工具! parted !
parted 可以直接在一行指令列就完成分割!他的语法有点像这样:

上面是最简单的 parted 指令功能简介,你可以使用『 man parted 』,或者是『 parted /dev/hdc help mkpart 』去查询更详细的数据。比较有趣的地方在于分割表的输出。我们将上述的分割表示意拆成六部分来说明:
1. Number:这个就是分割槽的号码啦!举例来说,1号代表的是 /dev/hdc1 的意思;
2. Start:起始的磁柱位置在这颗磁盘的多少 MB 处。他以容量作为单位!
3. End:结束的磁柱位置在这颗磁盘的多少 MB 处;
4. Size:由上述两者的分析,得到这个分割槽有多少容量;
5. Type:就是分割槽的类型,有primary, extended, logical等类型;
6. File system:就如同 fdisk 的 System ID 之意。
接下来我们尝试来建立一个全新的分割槽!因为我们仅剩下逻辑分割槽可用,所以等一下底下我们选择的会是 logical 的分割类型!