近日工作需要处理大量感知结果数据,并以特定结构类型储存在txt文件中。需用MatLab对感知数据结果绘图并与Ground Truth对比分析
转自http://www.ilovematlab.cn/article-63-1.html?s_tid=AdInThread
Matlab文本文件的读写函数可以分为两类,一类是高级函数(high-level),一类是底层函数(low-level)。通常认为高级函数运用起来简单,但是定制性差。底层函数用法复杂,但是灵活性高。由于 MATLAB 提供了许多可以读取文本文件的函数,例如 load、importdata、textread、dlmread、csvread,要把这些函数各自的适用范围弄清楚也不是一件容易的事,我的建议是掌握两个底层函数 fscanf 和 textscan 的用法,这样就能够轻松应对一般文本文件的读取了。下面简单介绍几个高级函数的用法,着重介绍两个底层函数 fscanf 和 textscan 的用法。
1. load/importdata/csvread
对于简单文本文件的读取(文件内容只包括数值,并且以逗号或空格为分隔符),这三个函数的常见用法基本一致。
load、importdata、csvread 常见用法:
M = csvread(filename)
M = load(filename)
M = importdata(filename)filename 即你需要读取的文件。
例如,创建一个文件,test.txt,包含以下数据:
16,2,3,13
5,11,10,8
9,7,6,12
4,14,15,1
读取整个文件:
filename = test.txt;
M = csvread(filename)
% M = load(filename)
% M = importadata(filename)
M =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 12. dlmread
dlmread 的用法比 csvread 稍微复杂一点,它能够指定分隔符(csvread 只能读取逗号分隔符和空格分隔符)。
dlmread 常见用法:
M = dlmread(filename)
M = dlmread(filename, delimiter)其中 filename 为所读取的文件,delimiter 为分隔符。
例:对于包含以下内容的文本文件:
16。2。3。13
5。11。10。8
9。7。6。12
4。14。15。1
就可以指定 ’。’ 为分隔符进行读取:
filename = 'csvlist.dat';
M = dlmread(filename,’。’)
M =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1如果行列数不一致的数据, dlmread 会自动在空白数据处补0。
例:对于包含以下内容的文本文件:
40 5 30 1.6 0.2 1.2
15 25 35 0.6 1 1.4
20 45 10 0.8 1.8 0.4

2.6667 0.33333 2
1 1.6667 2.3333
1.3333 3 0.66667
filename = 'csvlist.dat';
M = dlmread(filename)
M =
40.0000 5.0000 30.0000 1.6000 0.2000 1.2000
15.0000 25.0000 35.0000 0.6000 1.0000 1.4000
20.0000 45.0000 10.0000 0.8000 1.8000 0.4000
2.6667 0.3333 2.0000 0 0 0
1.0000 1.6667 2.3333 0 0 0
1.3333 3.0000 0.6667 0 0 0
3. fscanf
按指定格式从文本文件中读取数据。用法:
A = fscanf(fileID,formatSpec);
%通过指定读取格式formatSpec,从文本文件中读取数据至列向量A。fscanf会重复应用格式字符串formatSpec,直到文件指针到达文件末尾,如果读取到不能匹配formatSpec的数据则读取自动结束。
A = fscanf(fileID,formatSpec,sizeA);
%sizeA能够指定读取数据的大小,当读取到sizeA大小的数据时,文件指针会停止,读取结束。注意fscanf读取的是列主序,通常读取完还需要进行转置操作。所要读取的文本文件被文件标识符 fileID 标识,通过 fopen 函数可以获取文件的 fileID。当结束读取时,一定要记得使用 fclose 函数关闭文件。
光看函数的用法介绍可能会比较难懂,通过下面的例子会比较容易理解。 例:文本文件 test.txt 包含以下数据:
16。2。3。13
5。11。10。8
9。7。6。12
4。14。15。1
fid = fopen('test.txt'); %通过fopen获取文件标识
formatSpec = '%d。%d。%d。%d'; %指定读取格式
A = fscanf(fid,formatSpec ,[4,4]); %读取文件数据并存为4*4矩阵
fclose(fid); %调用fclose关闭文件
A = A.’ %由于fscanf是列主序,因此读取完还需要进行转置
A =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1下面详细解释一下 fscanf 的读取原理:
当用 fopen 打开文件时,会有一个文件指针在文件开头。fscanf 通过你设定的格式字符串 formatSpec 来读取数据(formatSpec 由字符串和转义说明符组成,其中转义说明符由 % 开头,以转换字母结尾。上面的例子中 %d 就是一个转义说明符,代表一个整数,常用的还有%f、%s,分别代表浮点数和字符串)。formatSpec 第一个字符块为转义说明符 %d,那么 fscanf 会先将第一个整数16读入进 A,之后文件指针跳至16右边,formatSpec 第2个字符块是字符串’。’,由于它不是转义说明符,文件指针会跳过’。’到达’。’右边。之后再是转义说明符 %d,则将2读入进 A,以此类推。
用下面图片进行说明:
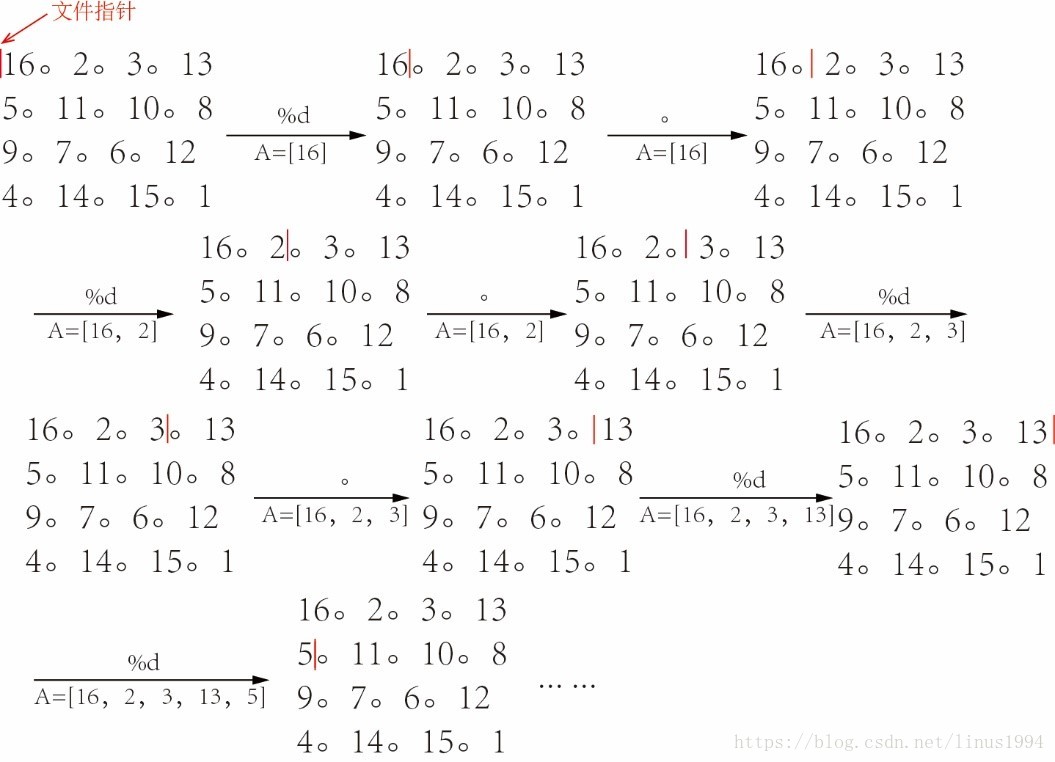
如果将这个例子的读取代码写成:
fid = fopen('test.txt');
A = fscanf(fid,'%d。',[4,4])
fclose(fid);
A = A.'将会得到:
A =
16 2 3 13原因就是当文件指针读取完13时,formatSpec 需要匹配的字符串是’。’,但是13的下一个字符串是5,匹配失败,fscanf 停止读取。
再以一个比较复杂的文本文件为例:
例:文本文件test.txt包含以下数据:
lambda: 7.580000e-05
lambdaB: 8.000000e-05
initial pulse width: 7.853636e-13
output pulse width: 6.253030e-13
dispersion length: 6.307732e-02
nonlinear length: 9.572495e-01
lambda: 7.590000e-05
lambdaB: 8.000000e-05
initial pulse width: 7.848788e-13
output pulse width: 5.778485e-13
dispersion length: 5.852858e-02
nonlinear length: 9.195277e-01
…
现在想要把所有的数字信息提取出来:
fid = fopen('F:\test.txt');
c1 = '%*s %e'; %第一行的转义说明符,’%’后面接一个’*’代表跳过这个数据,%*s即代表跳过第一个字符串’lambda:’,%e表示读取以科学计数法表示的数字。
c2 = '%*s %e';
c3 = '%*s %*s %*s %e';
c4 = '%*s %*s %*s %e';
c5 = '%*s %*s %e';
c6 = '%*s %*s %e';
formatSpec = [c1,c2,c3,c4,c5,c6]; %以6行为一组,重复读取,直至读取完整个文件
A = fscanf(fid,formatSpec,[6,inf])
fclose(fid);4. textscan
textscan 的用法与 fscanf 类似,建议先将 fscanf 的用法弄清楚再来看 textscan。
textscan 常见用法:
C = textscan(fileID,formatSpec)
C = textscan(fileID,formatSpec,N)同 fscanf 一样,fileID 为文件标识符,formatSpec 为格式字符串。N 则是重复匹配formatSpec 的次数。
与 fscanf 不同的是, textscan 将每个与 formatSpec 转义说明符匹配出来的数据都用一个元胞进行存储。并且 textscan 有很多选项提供,比如 ’Headerlines’ ,可以指定跳过文件的前n行; ’Delimiter’ 可以指定分隔符等等。
例:文本文件test.txt包含以下数据:
16。2。3。13
5。11。10。8
9。7。6。12
4。14。15。1
fid = fopen('F:\test.txt');
formatSpec = '%d'
A = textscan(fid,formatSpec,'delimiter','。'); %指定’。’为分隔符,如果不指定分隔符的话,就需要把formatSpec写成'%d。%d。%d。%d' 。
fclose(fid);
celldisp(A)
A{1} =
16
2
3
13
5
11
10
8
9
7
6
12
4
14
15
1