一、KMP算法解决字符串匹配问题
KMP算法可以用来解决字符串匹配问题。现在有两个字符串,str1长度为n和str2长度为m且n>=m,判断是否存在str1中包含str2(也就是判断str2是否是str1的子串),如果存在,则返回true,如果不存在则返回false。
我们一般的思路是,从str1的第一个字符开始,截取和str2相同长度的子串,将两者人进行比较,直到末尾(真实情况下移动到n-m处结束)这种方式的时间复杂度为O(n*m)。
但是KMP算法可以将时间复杂度降到O(n+m)。
(图片引用:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html)
我认为,KMP算法的优势在于,减少了比较的次数,如果用传统思路,我们需要对str1的字符一个一个的比较。
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
1、首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。

2、因为B与A不匹配,搜索词再往后移。

3、就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。

4、继续比较str1和str2直到字符串有一个字符,与搜索词对应的字符不相同为止。

5、这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
这里我们就要引入两个概念:
- 前缀: "前缀"指除了最后一个字符以外,一个字符串的全部头部组合
- 后缀:"后缀"指除了第一个字符以外,一个字符串的全部尾部组合
- 部分匹配值:"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
知道这些概念以后,我们就需要对str2进行预处理,得到一个next[]数组,这个next数组表示的其实就是str2字符串的前缀和后缀存在的共有元素的所有情况。
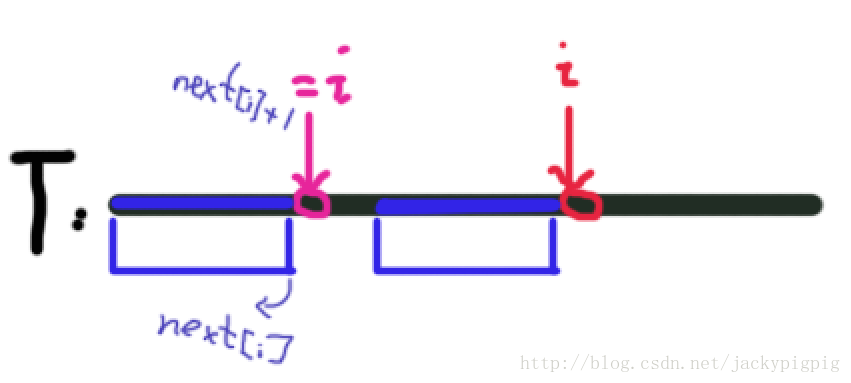
这张图的T表示str2字符串,蓝色的段落表示部分匹配值,我们可以看到,但我们从第一个位置比较str2和str1失败后,我们可以直接将第一段的蓝色线段的最左边移到右边蓝色线段的最左边,这样就避免了中间的重复比较操作,提高了效率。
那么,这个next数组应该怎么求呢?
- k表示的是前缀和后缀的长度,如果str2长度为n,那么它的前缀情况和后缀情况相等且为n种,分别是(0,1,...n-1)
- 初始一下next[0]=-1,next中储存的是当k为0~n-1,每种情况下前缀和后缀的部分匹配值。
- 枚举 i 从1到n,依次求next[i]
- 再用一个变量 k 记录答案,初始值为next[i-1],即图中左边那个篮框的位置,不过此时 k+1 这里不确定是不是i那个字符,再判断一下,若T[k+1]与T[i]不同,则k=next[k],直到k小于零为止。
void get_next(){
next[0]=-1;
for (int i=1; i<n; i++){
int k=next[i-1];
while (k>-1 && T[k+1]!=T[i]) k=next[k];
if (T[k+1]==T[i]) k++;
next[i]=k;
}
}- 附上几组求next数组的演示动画,可以截图下来慢慢看
- ababa

- ababacabc

接下来,我们就要进行str1和str2的字符串匹配了,前面得到next数组中已经储存了str2字符串的子串情况,一旦在比较的过程中出现不匹配的情况,就可以返回到上一次匹配的子串。最后的ans表示的是子串在str1中的开头元素的坐标。
void kmp(){
int k=0; //k代表T字符串中T中k以及之前的都匹配好了(T[0..k]=S[i-k-1..i-1])
for (int i=0; i<m; i++){ //i代表S字符串当前匹配位是第i位
while (k>-1 && S[i]!=T[k+1]) k=next[k]; //可以看做T一直向右移直到匹配成功或不能移了
if (S[i]==T[k+1]) k++; //若T[k+1]位与S[i],说明第k+1位也是匹配成功的,k就再加一下
if (k==n-1) k=next[k], ans++; //要是k是T的最后一位,说明T整串都匹配成功,处理一下答案
}
}这里可能不好理解,下面的动图可以提供一些帮助
S: ababababcababdababadb
T: ababa
