目录
本章研究MAP之类
7.1.HashMap
简单的说,HashMap内部结构使用的是数组。HashMap就是就key做Hash算法,然后将hash后的值映射到数组下表,这样就能快速操作数组。
Hashmap必须保证几个特点:
1).hash算法必须是高效的;
2).hash值映射数组下标算法是高效的;
3).根据数组下标可以直接获取对应的值.
原文:https://blog.csdn.net/lan861698789/article/details/81323643
1.内部组成
| public class HashMap{ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量2的4次方 = 16 static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量:2的30次方 static final Entry<?,?>[] EMPTY_TABLE = {};//默认空 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;//数组 transient int size;//大小 } 原文:https://blog.csdn.net/lan861698789/article/details/81323643 static class Entry<K,V> { final K key; V value; Entry<K,V> next;//下个entry int hash;
Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } } |
最主要的结构:table链表数组、size大小。
这里使用了entry来做存储. Entry里面结构:key,value,next,hash
默认容量16
2.HASH算法
算出key的hash值
| final static int hash(Object k) { h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } |
都是高效的位运算。
3.HASH值映射数组下标算法
| static int indexFor(int h, int length) { return h & (length-1);//与运算 } |
4.添加put
原文:https://blog.csdn.net/lan861698789/article/details/81323643
代码:以test.put("01", "01-value");来举例。
| private static void test01() { HashMap<String, String> test = new HashMap<String, String>(); //indexFor(hash("01"), 16); test.put("01", "01-value"); //indexFor(hash("02"), 16); test.put("02", "02-value"); //indexFor(hash("99"), 16); test.put("99", "99-value"); test.get("02");
test.remove("02"); } |
| public V put(K key, V value) { if (key == null) return putForNullKey(value);//可以放空值 int hash = hash(key);//HASH算法,求出key的hash值。这里key:01的hash为1645 int i = indexFor(hash, table.length);//通过hash值,计算出数组中的下标。 这里为13 //旧值查找替换,直接通过数组下标,找到key对应的数组table[i] for (Entry<K,V> e = table[i]; e != null; e = e.next) { //循环table[i],查找是否有next元素 Object k; //对比hash和key是否相等。 如果相等,直接用新值替换旧值。并且返回旧值。 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
modCount++; //新增 addEntry(hash, key, value, i); return null; } 原文:https://blog.csdn.net/lan861698789/article/details/81323643 void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) {//扩容 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } //将新增的元素放到i位置,并将它的next指向旧的元素 Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e);//代码1 size++; } |
原理:
1).hash算法得出key的hash值
2).通过hash值得出该key在table数组的下标
3).判断该key在table数组里面是否存在,存在则替换为新值。 这里要注意next,后面会讲到hash冲突就会存到next里面。
4).如果不存在,则新增。
5).先做扩容2倍
6).新增,取出旧元素,将新元素赋值给table[i],在将table[i].next赋值为旧元素。
这里的旧元素,如果第一次新增就是null。如果新增的元素hash值一样,key不一样,那旧元素就不为空了。后面会讲到。
截图:
| 代码1执行后图 |
| |

分析:
通过新增,我们可以知道,虽然hashmap是以数组来存储的,但是每次新增数组下标却不一定是自增,所以他是无序的。
原文:https://blog.csdn.net/lan861698789/article/details/81323643
5.获取get
代码:
| public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key);
int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; } |
原理:
1).hash算法得出key的hash值
2).通过hash值得出该key在table数组的下标
3).循环next,找出hash和key都一样的元素
6.hash值冲突解决
虽然通过计算hash来获取数组下标很高效,但是还是会存在两个不同的key,计算得到的hash值一样的情况。那么hashmap会如何处理呢?
再看下hashmap的组成结构,发现entry里面有一个next属性,它会指向另外一个entry。
| |
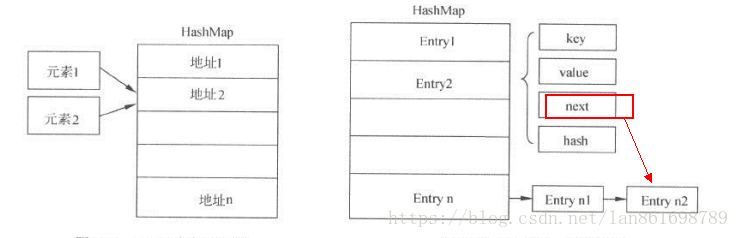
再次回顾添加的源码,里面两处使用了next。
第一次,查找旧值时候,会判断next是否存在
第二次,没有查到旧值,新增新值时候,每次新增的值都放在table[i],把旧值放到新值的next处,也就是table[i].next,这个值可能是null.
| public V put(K key, V value) { if (key == null) return putForNullKey(value);//可以放空值 int hash = hash(key);//HASH算法,求出key的hash值。这里key:01的hash为1645 int i = indexFor(hash, table.length);//通过hash值,计算出数组中的下标。 这里为13 //旧值查找替换,直接通过数组下标,找到key对应的数组table[i] //第一次 for (Entry<K,V> e = table[i]; e != null; e = e.next) { //循环table[i],查找是否有next元素 Object k; //对比hash和key是否相等。 如果相等,直接用新值替换旧值。并且返回旧值。 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } }
modCount++; //新增 //第二次 addEntry(hash, key, value, i); return null; }
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) {//扩容 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } //将新增的元素放到i位置,并将它的next指向旧的元素 Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e);//代码1 size++; } 原文:https://blog.csdn.net/lan861698789/article/details/81323643 static class Entry<K,V> { final K key; V value; Entry<K,V> next;//下个entry int hash;
Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } } |
7.hashMap输出顺序
虽然hashmap是以数组来存储的,但是每次新增数组下标却不一定是自增,所以他是无序的。
那么他是怎么排序的呢?
| private static void test01() { HashMap<String, String> test = new HashMap<String, String>(); System.out.println("01->"+indexFor(hash("01"), 16)); test.put("01", "01-value"); System.out.println("02->"+indexFor(hash("02"), 16)); test.put("02", "02-value"); System.out.println("99->"+indexFor(hash("99"), 16)); test.put("99", "99-value"); test.put("99", "99-value2"); //循环输出 Iterator<Entry<String, String>> iterator = test.entrySet().iterator(); while (iterator.hasNext()) { System.out.println(iterator.next().getKey()); } test.get("02");
test.remove("02"); } |
输出:
| 每次输出都是一样。 |

分析:
可以看出,hashmap排序是通过通过数组排序的,也就是按照table里面的数组顺序输出的。但是因为每次存入的数组下标不一样。所以看起来不是先进先出这种排序了。
| |

7.2.LinkedHashMap有序的map
| |

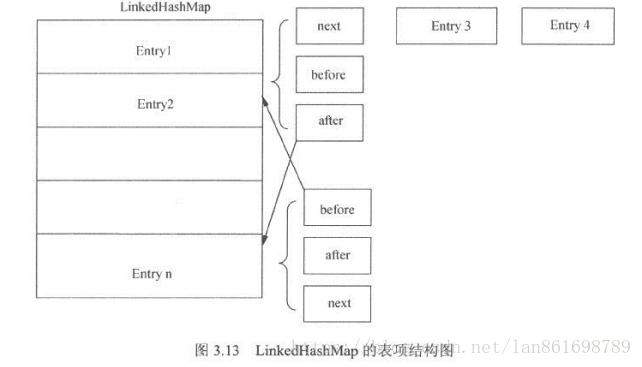
1.内部组成
| public class HashMap{ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量2的4次方 = 16 static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量:2的30次方 static final Entry<?,?>[] EMPTY_TABLE = {};//默认空 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;//数组 transient int size;//大小 }
static class Entry<K,V> { final K key; V value; int hash; Entry<K,V> next;//下个entry Entry<K,V> before, after;//linkedHashMap特有
Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } } |
黄色部分为linkedHashMap特有的结构。
| |
| |

原文:https://blog.csdn.net/lan861698789/article/details/81323643
