现阶段流行的高可用架构具体实现形式一般如下:
1)形如:Proxy+多个MySQL节点:例如 MySQL5.5/5.6一主N从(带semi-sync的复制)+MHA
2)MySQL5.6(GTID)双“主”复制+Keeplived+mysql-utilities(mysqlfailover)
不同于上述两者使用的是复制来做数据同步,如下为使用分布式协议(paxos、raft等)进行数据同步(需要至少3个节点)
3)PXC 或者 Galera
4)面向未来:MySQL Group Replication
先从工作中使用较多的多节点间半同步复制+MHA开始了解。(切换时间最长:30秒内,是因为需要进行补齐数据、重建复制关系等操作)
首先需要确认一点的是,MHA实现的是Master的高可用。
贴一张MHA作者在 MySQL Conference and Expo 2011 上分享的图片

复制关系搭建
MySQL一主多从复制关系,示例:
Manager Node 192.168.237.11(管理节点)
Data Node_1 192.168.237.12(数据节点,MySQL主库)
Data Node_2 192.168.237.13(数据节点,MySQL备库,候选主库)
Data Node_3 192.168.237.14(数据节点,MySQL备库)配置数据节点的iptables,保证管理节点能访问数据节点的MySQL端口
所有数据节点配置相同的过滤规则(MHA在启动的时候会检查过滤规则,不同则启动失败)
开启候选主库的log-bin。管理节点会检测候选主库是否有配置log-bin,若没有该配置项,MHA将不会进行failover
打通SSH互信
正确配置管理节点和数据节点的域名解析,很重要!
管理节点及数据节点间打通SSH互信:
# ssh-keygen -t rsa# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
数据节点部署
# yum install perl-DBI perl-DBD-MySQL
【避免出现Can't locate ExtUtils/MakeMaker.pm in @INC】
# tar zxvf ExtUtils-MakeMaker-7.18.tar.gz
# cd ExtUtils-MakeMaker-7.18
# perl Makefile.PL
# make && make install
# tar zxvf CPAN-2.10.tar.gz
# cd CPAN-2.10
# perl Makefile.PL
# make && make install
# cd mha4mysql-node-0.56
# perl Makefile.PL
# make && make install
设置relay log清除方式
mysql > set global relay_log_purge=0;
my.cnf中设置 relay_log_purge=0
关闭该参数的原因是因为在默认情况下,从库上的relay log在SQL线程执行完后会自动被删掉。但是在failover过程中从库需要利用候选主库上的中继日志来补数据,所以MySQL默认打开的自动清楚中继日志的功能需要关闭,但是为了不撑爆磁盘就需要定期清除旧的relay log。清除relay log需要考虑复制延时的问题。在ext3文件系统下,删除大文件建议采用硬链接的方法。
关于relay log的清除,可参考以下文章:
http://daisywei.blog.51cto.com/7837970/1881154
管理节点部署
mangaer节点安装MHA:(1)同数据节点一样,也需要安装 mha4mysql-node
(2)安装 mha4mysql-manager:# yum install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Config-IniFiles perl-Time-HiRes
# tar zxvf mha4mysql-manager-0.56.tar.gz
# cd mha4mysql-manager-0.56
# perl Makefile.PL
# make && make install
(2)修改配置文件:
建立mha配置文件及脚本目录
# mkdir -p /etc/mha_base/{app1,scripts}
复制源码包内的配置文件、脚本(app1.cnf、masterha_default.cnf 可以合并为一个文件)
# cp /root/mha4mysql-manager-0.56/samples/conf/app1.cnf /etc/mha_base/app1/# cp /root/mha4mysql-manager-0.56/samples/conf/masterha_default.cnf /etc/
# cp /root/mha4mysql-manager-0.56/samples/scripts/* /etc/mha_base/scripts/# vim /etc/masterha_default.cnf
[server default]
user=root
password=123456
ssh_user=root
repl_user=replication_user
repl_password=123456
master_binlog_dir= '/usr/local/mysql/data'
remote_workdir=/data/log/masterha
secondary_check_script= masterha_secondary_check -s 237_12 -s 237_13 -s 237_14 -user=root --master_host=237_12 --master_ip=192.168.237.12 --master_port=3306
ping_interval=1
# master_ip_failover_script= /script/masterha/master_ip_failover
# shutdown_script= /script/masterha/power_manager
# report_script= /script/masterha/send_report
# master_ip_online_change_script= /script/masterha/master_ip_online_change注:加粗的为数据库账户
# vim /etc/mha_base/app1/app1.cnf
[server default]
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/manager.log
[server1]
hostname=237_12
candidate_master=1
[server2]
hostname=237_13
candidate_master=1
[server3]
hostname=237_14
no_master=1
环境检测
# masterha_check_ssh --conf=/etc/mha_base/app1/app1.cnf
提示:All SSH connection tests passed successfully 表示节点间SSH连同
# masterha_check_repl --conf=/etc/mha_base/app1/app1.cnf
提示:MySQL Replication Health is OK.
启动MHA Manager
# nohup masterha_manager --conf=/etc/mha_base/app1/app1.cnf < /dev/null >/tmp/mha_manager.log 2>&1 &观察日志情况
# tail -f /tmp/mha_manager.logThu Aug 10 21:49:09 2017 - [info] Reading default configuration from /etc/masterha_default.cnf..
Thu Aug 10 21:49:09 2017 - [info] Reading application default configuration from /etc/mha_base/app1/app1.cnf..
Thu Aug 10 21:49:09 2017 - [info] Reading server configuration from /etc/mha_base/app1/app1.cnf..
查看MHA状态:
# masterha_check_status --conf=/etc/mha_base/app1/app1.cnfapp1 (pid:1716) is running(0:PING_OK), master:237_12
故障演练
(1)failover故障切换
模拟主库(192.168.237.12)MySQL实例挂掉
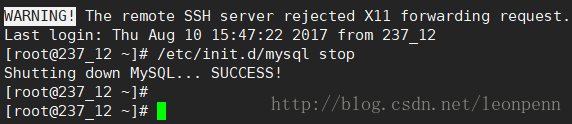
观察备库237.14的主从复制关系:主库已经切换为237.13
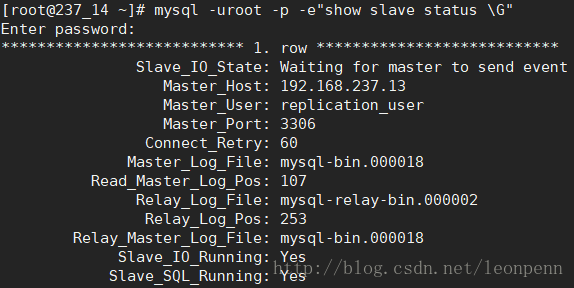
观察此时新的主库的binlog位置点:
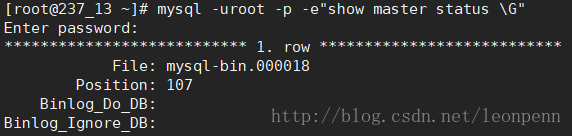
查看管理节点的日志记录(位置由配置文件中参数:manager_log决定)
# cat /var/log/masterha/app1/manager.log
From:
237_12(192.168.237.12:3306) (current master)
+--237_13(192.168.237.13:3306)
+--237_14(192.168.237.14:3306)
To:
237_13(192.168.237.13:3306) (new master)
+--237_14(192.168.237.14:3306)
[root@237_11 script]# masterha_check_status --conf=/etc/mha_base/app1/app1.cnf
app1 is stopped(2:NOT_RUNNING).
需要注意的是,无论宕机导致的master切换、还是没有特别设置地手动切换master(不含orig_master_is_new_slave选项),原来的master都不在MHA架构内了,即使重新启动也不会加入,必须手动加入。配置文件中仍然是以挂掉的master为主库,并没有提升candidated master为主库,此时MHA将不再具备高可用的特性,需尽快更新配置文件,并在管理节点运行masterha_check_ssh确认无误后重新启用MHA manager。
此时,若假设237.12上的MySQL已成功修复故障,正常启动后,可以以备库的身份加入MHA架构内:
首先,在MHA管理节点的日志中找到,复制需要的主库binlog位置点:

建立到新主库237.13的复制关系

Tips:该步骤很有可能会报1236的错误,并且Slave_IO_Running状态为 No

解决办法如下(从库切换到新的binlog,并重新指向之前卡在的主库binlog位置点):
mysql> stop slave;
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> flush logs;
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> show master status \G
*************************** 1. row ***************************
File: mysql-bin.000035
Position: 107
Binlog_Do_DB:
Binlog_Ignore_DB:
1 row in set (0.00 sec)
mysql> change master to master_log_file='mysql-bin.000018',master_log_pos=107;
Query OK, 0 rows affected (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.237.13
Master_User: replication_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000018
Read_Master_Log_Pos: 107
Relay_Log_File: 237_12-relay-bin.000002
Relay_Log_Pos: 253
Relay_Master_Log_File: mysql-bin.000018
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 107
Relay_Log_Space: 410
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 23713
1 row in set (0.00 sec)
当建立新主从关系后,可以开始修改MHA配置文件(app1.cnf)中的server1、server2的hostname,重新启用新的高可用
[server1]
hostname=237_13
candidate_master=1
[server2]
hostname=237_12
candidate_master=1# masterha_check_repl --conf=/etc/mha_base/app1/app1.cnf
# masterha_check_ssh --conf=/etc/mha_base/app1/app1.cnf
检查配置文件正确性
以app1.cnf为配置文件再次启动mha
# nohup masterha_manager --conf=/etc/mha_base/app1/app1.cnf < /dev/null >/tmp/mha_manager.log 2>&1 &
确认mha状态
# masterha_check_status --conf=/etc/mha_base/app1/app1.cnf
app1 (pid:1977) is running(0:PING_OK), master:node2
(2)online master switch(理论写操作的阻塞时间在0.5秒-2秒)
功能:用于调整无法在线变更的参数(例如innodb_buffer_pool_size等)。通过在从库配置文件中调整参数并重启生效后,执行online master switch将从库提升为主库,原主库同样修改参数后重启,并以从库的身份重新加入MHA架构,从而曲线实现了在线变更参数的需求而无需中断业务。
切换前需要先停止MHA manger,否则会有如下报错。

以下为成功切换过程
[root@237_11 app1]# masterha_stop --conf=/etc/mha_base/app1/app1.cnf
Stopped app1 successfully.
[1]+ Exit 1 nohup masterha_manager --conf=/etc/mha_base/app1/app1.cnf < /dev/null > /tmp/mha_manager.log 2>&1
[root@237_11 app1]#
[root@237_11 app1]# masterha_master_switch --conf=/etc/mha_base/app1/app1.cnf --master_state=alive --new_master_host=237_12 --orig_master_is_new_slave --running_updates_limit=10000 --interactive=0
Sun Aug 13 21:46:10 2017 - [info] MHA::MasterRotate version 0.56.
Sun Aug 13 21:46:10 2017 - [info] Starting online master switch..
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:10 2017 - [info] * Phase 1: Configuration Check Phase..
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:10 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sun Aug 13 21:46:10 2017 - [info] Reading application default configuration from /etc/mha_base/app1/app1.cnf..
Sun Aug 13 21:46:10 2017 - [info] Reading server configuration from /etc/mha_base/app1/app1.cnf..
Sun Aug 13 21:46:10 2017 - [info] GTID failover mode = 0
Sun Aug 13 21:46:10 2017 - [info] Current Alive Master: 237_13(192.168.237.13:3306)
Sun Aug 13 21:46:10 2017 - [info] Alive Slaves:
Sun Aug 13 21:46:10 2017 - [info] 237_12(192.168.237.12:3306) Version=5.5.54-log (oldest major version between slaves) log-bin:enabled
Sun Aug 13 21:46:10 2017 - [info] Replicating from 192.168.237.13(192.168.237.13:3306)
Sun Aug 13 21:46:10 2017 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Aug 13 21:46:10 2017 - [info] 237_14(192.168.237.14:3306) Version=5.5.54-log (oldest major version between slaves) log-bin:enabled
Sun Aug 13 21:46:10 2017 - [info] Replicating from 192.168.237.13(192.168.237.13:3306)
Sun Aug 13 21:46:10 2017 - [info] Not candidate for the new Master (no_master is set)
Sun Aug 13 21:46:10 2017 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..
Sun Aug 13 21:46:10 2017 - [info] ok.
Sun Aug 13 21:46:10 2017 - [info] Checking MHA is not monitoring or doing failover..
Sun Aug 13 21:46:10 2017 - [info] Checking replication health on 237_12..
Sun Aug 13 21:46:10 2017 - [info] ok.
Sun Aug 13 21:46:10 2017 - [info] Checking replication health on 237_14..
Sun Aug 13 21:46:10 2017 - [info] ok.
Sun Aug 13 21:46:10 2017 - [info] 237_12 can be new master.
Sun Aug 13 21:46:10 2017 - [info]
From:
237_13(192.168.237.13:3306) (current master)
+--237_12(192.168.237.12:3306)
+--237_14(192.168.237.14:3306)
To:
237_12(192.168.237.12:3306) (new master)
+--237_14(192.168.237.14:3306)
+--237_13(192.168.237.13:3306)
Sun Aug 13 21:46:10 2017 - [info] Checking whether 237_12(192.168.237.12:3306) is ok for the new master..
Sun Aug 13 21:46:10 2017 - [info] ok.
Sun Aug 13 21:46:10 2017 - [info] 237_13(192.168.237.13:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host.
Sun Aug 13 21:46:10 2017 - [info] 237_13(192.168.237.13:3306): Resetting slave pointing to the dummy host.
Sun Aug 13 21:46:10 2017 - [info] ** Phase 1: Configuration Check Phase completed.
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:10 2017 - [info] * Phase 2: Rejecting updates Phase..
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:10 2017 - [warning] master_ip_online_change_script is not defined. Skipping disabling writes on the current master.
Sun Aug 13 21:46:10 2017 - [info] Locking all tables on the orig master to reject updates from everybody (including root):
Sun Aug 13 21:46:10 2017 - [info] Executing FLUSH TABLES WITH READ LOCK..
Sun Aug 13 21:46:10 2017 - [info] ok.
Sun Aug 13 21:46:10 2017 - [info] Orig master binlog:pos is mysql-bin.000018:107.
Sun Aug 13 21:46:10 2017 - [info] Waiting to execute all relay logs on 237_12(192.168.237.12:3306)..
Sun Aug 13 21:46:10 2017 - [info] master_pos_wait(mysql-bin.000018:107) completed on 237_12(192.168.237.12:3306). Executed 0 events.
Sun Aug 13 21:46:10 2017 - [info] done.
Sun Aug 13 21:46:10 2017 - [info] Getting new master's binlog name and position..
Sun Aug 13 21:46:10 2017 - [info] mysql-bin.000035:107
Sun Aug 13 21:46:10 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='237_12 or 192.168.237.12', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000035', MASTER_LOG_POS=107, MASTER_USER='replication_user', MASTER_PASSWORD='xxx';
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:10 2017 - [info] * Switching slaves in parallel..
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:10 2017 - [info] -- Slave switch on host 237_14(192.168.237.14:3306) started, pid: 8397
Sun Aug 13 21:46:10 2017 - [info]
Sun Aug 13 21:46:11 2017 - [info] Log messages from 237_14 ...
Sun Aug 13 21:46:11 2017 - [info]
Sun Aug 13 21:46:10 2017 - [info] Waiting to execute all relay logs on 237_14(192.168.237.14:3306)..
Sun Aug 13 21:46:10 2017 - [info] master_pos_wait(mysql-bin.000018:107) completed on 237_14(192.168.237.14:3306). Executed 0 events.
Sun Aug 13 21:46:10 2017 - [info] done.
Sun Aug 13 21:46:10 2017 - [info] Resetting slave 237_14(192.168.237.14:3306) and starting replication from the new master 237_12(192.168.237.12:3306)..
Sun Aug 13 21:46:11 2017 - [info] Executed CHANGE MASTER.
Sun Aug 13 21:46:11 2017 - [info] Slave started.
Sun Aug 13 21:46:11 2017 - [info] End of log messages from 237_14 ...
Sun Aug 13 21:46:11 2017 - [info]
Sun Aug 13 21:46:11 2017 - [info] -- Slave switch on host 237_14(192.168.237.14:3306) succeeded.
Sun Aug 13 21:46:11 2017 - [info] Unlocking all tables on the orig master:
Sun Aug 13 21:46:11 2017 - [info] Executing UNLOCK TABLES..
Sun Aug 13 21:46:11 2017 - [info] ok.
Sun Aug 13 21:46:11 2017 - [info] Starting orig master as a new slave..
Sun Aug 13 21:46:11 2017 - [info] Resetting slave 237_13(192.168.237.13:3306) and starting replication from the new master 237_12(192.168.237.12:3306)..
Sun Aug 13 21:46:11 2017 - [info] Executed CHANGE MASTER.
Sun Aug 13 21:46:11 2017 - [info] Slave started.
Sun Aug 13 21:46:11 2017 - [info] All new slave servers switched successfully.
Sun Aug 13 21:46:11 2017 - [info]
Sun Aug 13 21:46:11 2017 - [info] * Phase 5: New master cleanup phase..
Sun Aug 13 21:46:11 2017 - [info]
Sun Aug 13 21:46:11 2017 - [info] 237_12: Resetting slave info succeeded.
Sun Aug 13 21:46:11 2017 - [info] Switching master to 237_12(192.168.237.12:3306) completed successfully.
1、安装Keepalived
[root@237_12 toolkits]# yum -y install gcc gcc-c++ gcc-g77 ncurses-devel bison libaio-devel cmake libnl* libnfnetlink* libpopt* popt-static openssl-devel
[root@237_12 toolkits]# tar zxvf keepalived-1.2.22.tar.gz
[root@237_12 toolkits]# cd keepalived-1.2.22
[root@237_12 keepalived]# ./configure
[root@237_12 keepalived]# make && make install
[root@237_12 keepalived]# mkdir /etc/keepalived/
[root@237_12 keepalived]# cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/
[root@237_12 keepalived]# cp /usr/local/etc/rc.d/init.d/keepalived /etc/init.d/
[root@237_12 keepalived]# cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/
[root@237_12 keepalived]# cp /usr/local/sbin/keepalived /usr/sbin/2、配置Keepalived
[root@237_12 keepalived]# vim /etc/keepalived/keepalived.conf! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
#vrrp_skip_check_adv_addr
#vrrp_strict
#vrrp_garp_interval 0
#vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER # 主库MASTER,备库BACKUP
interface eth0
virtual_router_id 51
priority 100 # 优先级,主库的优先级(1~254)必须比备库高
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { # VIP地址
192.168.237.19
}
3、每分钟定时检查MySQL Server的脚本,加入crontab:*/1 * * * * bash /etc/keepalived/mysql_check.sh
#!/bin/bash
MYSQL=/user/local/mysql/bin/mysql
MYSQL_HOST=127.0.0.1
MYSQL_USER=root
MYSQL_PASSWORD=123456
CHECK_TIME=3
#MySQL is working:MySQL_OK is 1;MySQL down:MySQL_OK is 0
MYSQL_OK=1
function check_mysql_helth (){
if [ $? = 0 ] ;then
MYSQL_OK=1
else
MYSQL_OK=0
fi
return $MYSQL_OK
}
while [ $CHECK_TIME -ne 0 ]
do
let "CHECK_TIME -= 1"
check_mysql_helth
if [ $MYSQL_OK = 1 ] ; then
CHECK_TIME=0
exit 0
if
A='ps -ef |grep keepalive |grep -v grep |grep -c keepalive'
if [$A -ne 0];then
service mysqld stop
exit 0
fi
if [$MYSQL_OK -eq 0] && [$CHECK_TIME -eq 0]
then
pkill keepalived
exit 1
fi
sleep 1
Done
4、启动测试
参考文档:
https://severalnines.com/blog/mysql-replication-failover-maxscale-vs-mha-part-1
MHA参数详解:http://wubx.net/mha-parameters/