这个东西的还处于持续研发的阶段,还不能成为一个成熟体系的基础设施系统,但从研究意义上来说会有很多帮助,当然不用于商业目的,研发它的主动驱动性是不存在的。
本人比较随心所欲,设计图之类的东西几乎都是随便用点类似画图工具“画画”就行了(反正也没多少人看得懂,不是),你要说我水水的话,我到是感到很欣慰的,本来就是一个 “小小的菜鸟”呀!。
Google 前两年提出运行于全球级的 RDBMS “Spanner” 说实话当时看到这个东西,我的内心是相当澎湃,尤其是保证“分布式 CA*”的核心层 “True Time”方面的内容,根据相关的 “学术” 跟 “博客”,它是借助原子钟与GPS时钟来保证时间的准确性的,说实话在哪个时候我才知道原子钟是个什么东西,一下子又触碰到了知识盲区,书读少了没办法,哈哈哈!
原子钟精度可以达到 2000W年 相差一秒钟,而且据我所知这个时间是可以通过一些 “算法” 进行 “平衡时钟” 的,这样我们可以获取到几乎已经无比精确的时间值,既然可以拿到精确的时间那么 CA* 就可以保证。(-> 走出发去海淘进口原子钟)
面向全球级的 CA* 系统与区域性质的 CA* 系统从设计角度上来说是两码事情,考虑的方式都会不同,全球级的 CA* 系统的纵然保证了 “时间” 的几乎一致(完全一致是不可能的,差值是存在的,所以需要丢却一部分考虑一个容错的区间)但不要忘却一个最重要的东西是“网络平滑往返时迟”的问题,当然丢包率的影响也是很重大的,但恰恰 “ CA* ” 系统对这几个要素是非常敏感的,不过面向全球级 CA* 系统,准确的说是不成立的,它是一个伪命题!
而且 “Spanner” 它并不是即时的,而是处于大型集群异步事务的过程,利用“任务的时间”保证操作顺序的,这符合 Google Spanner 设计中很重要的一个观点 “相信时间”,不过因为这个缘故它在并发面前异常的脆弱,即:同一时间段【微妙时不同】对同个目标进行CURD操作,几乎不能保证 “任务时序”,不过这个问题几乎是分布式系统的一个“心病”了(虽然大多数人们从来不会承认),但你不可说这个东西不厉害。
好了逼逼了一大堆,都没说到本文的重点,啊哈哈!兄弟们要习惯,我一般想到关联点的开摆就停不下来,这个还是我压抑了自我很多的情况,不然等着看 “长篇大论” 吧!哈哈哈~笑!
区域性质的 CA* 系统,是在一个分布式集群中很重要的部分,它协同整个集群之间 “分布式资源” 访问之间的保护,举一个小例子:A与B 主机之间都需要去读写 Redis 之中的同一个 Key 的缓存,似乎人们这不太可能但真的不可能?但这类的情况发生的概率是很大的,Redis 它并不能保证两者之间的读写顺序,A主机先 Redis 服务器发送 Set 数据报文,B主机在之后几百个微妙后发送,那么真的就一定会是 “A主机” 先进行 Set ?只要搞过 “链路层网卡” 方面东西人都不会这么去看待这个问题,它不只受限于网络丢包、滑动窗口控制、SocketPoll 时钟周期频率、操作系统内核、TCP协议栈处理、Nagle;而且内核或网卡本身也是会出现丢包的(向内核以极高的频率向其同一个 TCPSocket 连接 PSH 数据包会造成内核出现丢包,网卡丢包是频率高了丢的)等等这些都会影响到 “应用层” Redis 服务器,收取到不同客户端 Socket 数据包的先后顺序。
上面就是告诉人们,它是不可能保证对 “Redis” 进行 “Set” 操作的先后顺序的,类似如 “keepalived + redis” 、“keepalived + zeekeeper” 这些方法实现的 “分布式 CA* ” 几乎没有考虑上述的问题。

这个图随便画的比较简单,有点意思就行了没必要搞那么花哨,我这个人就这样,画个图最多给你连接个线多的我懒的画,咋公司的情况,还招不到“技术大牛(当然也不敢,这是句废话)”,好苗子只认那些大公司(这个敢),但就算招到了要怎么留下他们才是一个很令人头疼的问题,这个真的是一件很不幸的事情呢!
这个图是架构类似一种 “DNS” 系统的结构,它是属于 “聚合式架构”,“离散式架构”拥有很高的效能 但就维护的角度来说不是很友好,但是游戏公司到挺适合的,而一般的企业就不是很适合了;而这类 “聚合式架构” 就比较贴合普通企业。
我们先想明白一点 “分布式 CA*” 系统是一种什么类型 I/O 的系统,才来决定该怎么去设计它,“分布式 CA*” 它是一个典型的 “高写入” 的系统,记住这个东西绝对不可能是 “高读入” 的系统,它的系统瓶颈就在 “写” 上面,所以这就是为什么 “malock” 系统的整体结构是上图所示的问题。
主从架构【结构】,真的适合 “分布式 CA*” 系统?先弄明白一点集群中的所有主机都在向 “malock” 的服务器不停的发送 “Enter、Exit” 指令用以控制 “目标锁” 的竞争与释放的过程;这是属于单纯的写操作,那么我们想一想采取主从的结构,我们不停的向 “主服务器(写库)” 进行 “Enter、Exit” 操作,同时 “主服务器” 向它的 “slave 节点” 之间广播操作,但是你真的有好好的去研究过思考过集群 “同步” 之间的 “时间差” 的问题,很多时候 “释放锁” 的频率几乎大于同步的时间,你几乎不用去质疑这个,测试一下就明白?
同时你是不是忽略了一个很重要的变量的,写入的效率受限于 “网络I/O” 的瓶颈,一般一个TCP连接大概一秒钟能够处理 12000 ~ 16000 包左右(平均大概是 14000 左右的样子),这个已经不是利用一些手段,例如: “粘包” 加速就能彻底解决的了的;纵然你增加再多 “slave 节点” 用以扩展读的能力,但这对整个 “分布式 CA*” 系统来说毫无意义,除了浪费硬件、人力资源可以找点存在感就没什么了。
malock 在设计之中 name-node(名称节点)的作用是很重要的(虽然还在研发之中尚未提交 github)简单的说它就是一张很大的表用于分派 “lock-key” 指向管理 “lock” 确切位置的 “malock-server-node(malock 服务器节点)”,它用以提高 malock “写” 的效率被设计出来的产物,同时起到一点负载平衡的作用,同时动态的维护各个节点,当某个节点出现 “完全宕机” 能够自动进行有效 “lock-key” 之间的节点 “平滑” (这是做最坏的打算,但这种可能性极低)。
当然上面没有提到一个很重要的东西,如果 “malock-client” 不对此进行优化的话,那么每次都重新 “质问” 名称节点服务器,那么整体的效率根本没有得到提升,还削减了很多的效能同时增加了 “malock-name-node” 的负载,所以这将要求 “malock-client” 采取一种 “本地缓存” 优化手段,类似于 “DNS本地缓存”,一般一个本地的 “key-lock” 缓存大概存活 15 分钟左右,“malock-client ” 就应该到时后重新 “质问” 一次,但质问过程其实并不一定需要单独的线程进行维护,“malock-client”只要主动的访问某个指定的 “keyid-lock” 就会诱发相应的 “event-source-point 事件源点”,虽然 “malock-name-node” 可以主动在 节点“平滑” 时推送新的源点到需求的 “malock-client” 是一个不错的方法,但这只针对于 “malock-name-node” 维护的可用 “malock-client” 连接并不多的情况,所以从 “通用性、中立性” 、设计向量” 的角度来说的话,它的缺陷还是比明显的。
malock-server-node 服务器节点,是基于 “Dual-Machine Hot standby 双机热备” 的方案设计的,这个节点比较类似“数据节点(DataNode)”但还是有一些区别的,当然它主要是管理 “lock-key” 之间的 “state”,同时协作 “malock-client” 们之间进行同步,这个节点最大的问题就是需要响应速度同时反抗死锁与并发,所以它并不适合进行很重的处理。
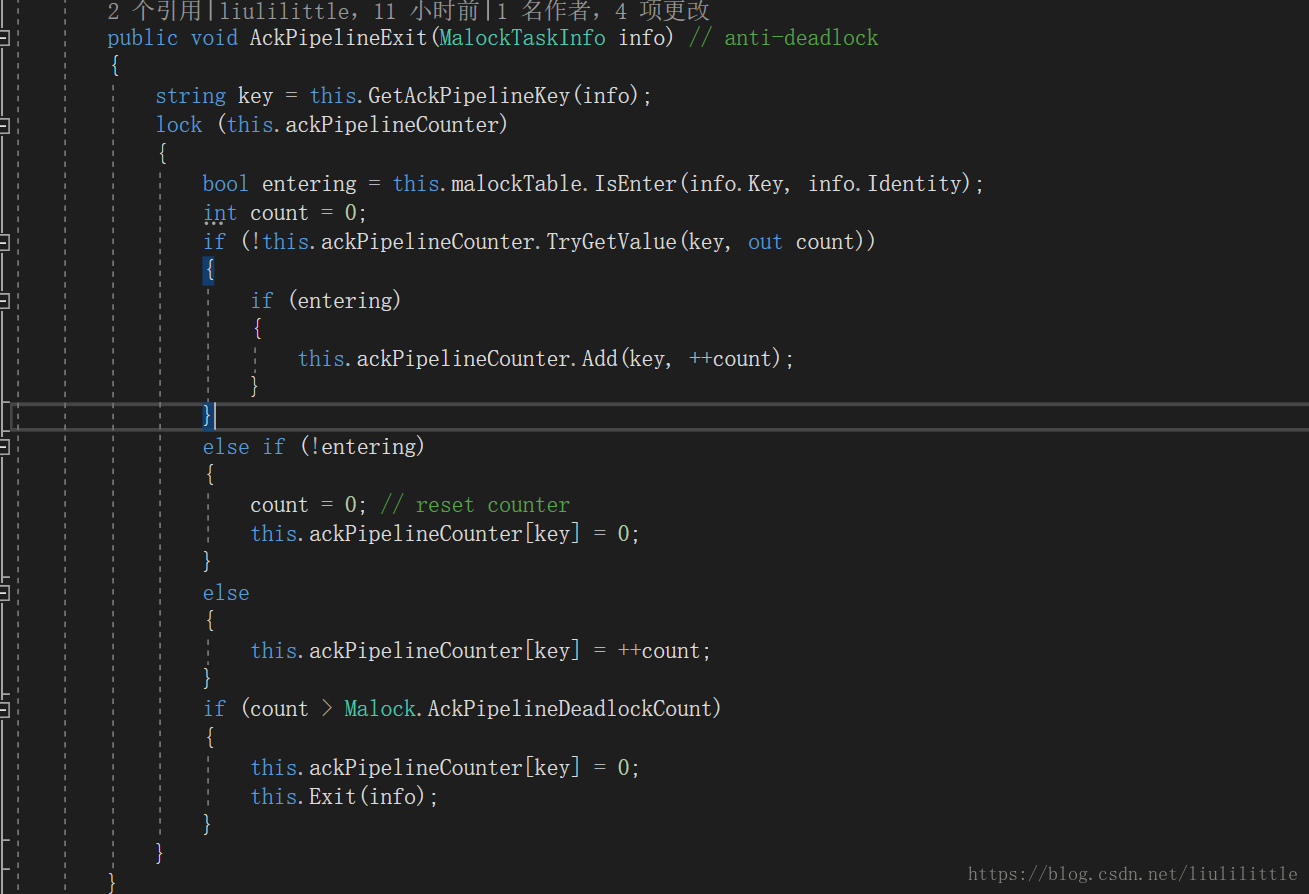
malock-server-node 利用一种 “ack-pipeline 确认流水线” 与 “ack-skateboard 确认滑板” 的办法来 “anti-deadlock” 同时规避高写入带来的 “并发控制” 问题,即 “客户端” 主动向服务器周期性向服务器 ack 当前 “客户与目标锁” 的流水真实状态,当然这必然会造成可能客户端还没有收取到服务器发送的 “enter” 指令数据包,但向服务器确认当前处于“ack-pipeline-exit”,那么理论上在不考虑并发的前提下“服务器”已经释放客户端持有的这个“lock”对象,但显然这是不现实的,所以我们需要寻找一些有效的办法用以控制“并发”从中推测出“客户端”的真实状况,而 “malock” 采取的就是一种 “ack-skateboard” 的办法,当然这只是一方面还有一些辅助的反抗死锁的处理,这里就不一一细说了。
人们可能会有一些疑问,为什么要客户端主动周期性向服务器 ack 呢?这个问题问的比较好,这说明小伙伴们真的用小脑瓜好好的进行过思考,想想为什么不应该是客户端主动 ack?我前面提到了 “malock-server-node” 需要响应的速度,同时它应该是一个越单纯越轻量的东西是最好的,若 “malock-server-node” 主动进行确认似乎并没有什么不好,但这个东西忽略了一个东西那就是服务器资源占用的问题,当服务器需要维护反复 ack 的 “lock” 非常非常之多的时候,服务器的资源会被大量的浪费在这个上面,同时服务器还需要维护 “客户端” 发起的大量不同锁之间 “enter” 的行为,本身就需要占用很高的资源消耗,那么当这个资源消耗持续增大时就会逐步影响到整个集群系统的整体效能,这是一个很不明智的行为,作为一明设计者,我是绝对不可能容忍这种情况的。
同时我们应该考虑 “malock-client” 与 “malick-server-node” 之间的协同,这个是很重要的一点,前面提到了服务器之间进行同步需要时间 “malock-client” 必须考虑进这些因素,同时由于 “malick-server-node” 是属于 “双机热备” 的体系,所以对于 “平滑” 的考虑也是很重要的,一般来说 “malock-client” 应控制默认采取的服务器始终是主服务器,只有当与 “主服务器” 之间连接被中断,在局域网中连接被中断的可能性几乎无限接近 1%,几乎大多数情况连接中断都可以肯定是服务器本身出现了什么故障,那么客户端应该立刻抛出异常?显然不是,这就是前面提到的 “malock-client” 必须考虑 “平滑” 的缘故。
小伙伴们这里可能对 “平滑” 有些疑惑,它主要是指的哪个方面,哈哈这个问题是很有趣的,它主要是指当 “malock-client” 与服务器之间出现了连接中断,那么不应该立即抛出网络中断异常,而且先测量 “备用服务器” 是否是可用的,若是 “备用服务器” 是处于可用的状态,那么把当前的任务 “平滑” 到 “备用服务器”,但如果 “备用服务器” 都是不可用的,那么就会抛出网络中断异常,但显然两个服务器都已经崩溃,这个就已经不是什么小事情了,这意味着这个“小集群”几乎完全崩溃,就需要进行问题的应急处理与排查处理;当然这有些危言耸听,这种可能性真的极低,只要程序本身很稳定,那么大多数情况都是人为造成的问题。
好了好了,今天关于 malock 的东西就先聊到这里,在聊我怕我真的可能会死了,呵呵~lp大人现在发飙了,malock 的源代码与测试 demo 你可以从我的 github 上面去获取到源代码,sourcecode: https://github.com/liulilittle/malock